
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
機械学習プロジェクトとは
機械学習プロジェクトには大きく分けて「機械学習モデルの構築」と「機械学習モデルの実装」があります。
【本日の解説範囲】AI・機械学習モデルの構築プロジェクト

モデル構築プロジェクトの場合、目的は「課題解決・ビジネス成長に寄与する機械学習モデル構築」になります。また、目的達成に向けて「モデルの性能評価・改善」を繰り返していくことが主要なアプローチです。本記事ではこの機械学習モデル構築プロジェクトの具体的な進め方について後述します。
【参考】AI・機械学習モデルの実装プロジェクト
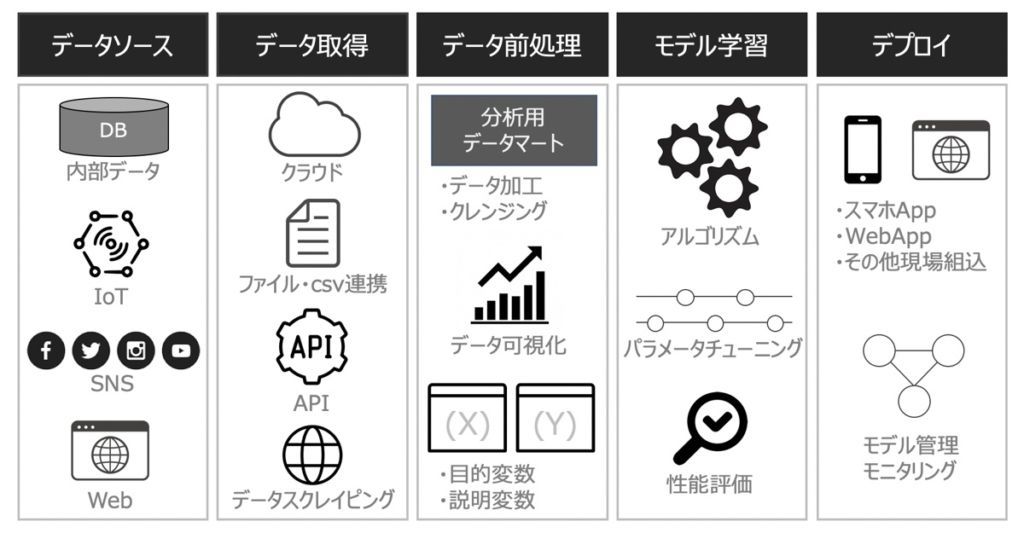
本記事では深く言及しませんが、参考として機械学習モデル実装プロジェクトで検討すべき観点を上図に示します。ポイントはデータ収集(データソース)からモデルが利用(デプロイ)されるまでの一連のデータフローをデザインすることです。具体的に下記が主な検討要件です。
| 検討要件 | 概要 |
|---|---|
| モデルの拡張性 | モデル・アプリ間、モデル・分析データ間のシームレスな連携ができること |
| モデルの保守性 | モデル自体の容易な改修が可能であること |
| モデルの管理 | モニタリングやスコアリング体制が機能すること |
| 業務・ビジネス適用性 | 業務やビジネスの意思決定・自動化支援がモデル利用により実現できること |
| データガバナンス | データのルール整備、コンプライアンスの遵守 |
| セキュリティ対策 | 一連のデータフロー構築に際してセキュリティレベルが担保されること |
AI・機械学習モデル構築プロジェクトの全体像
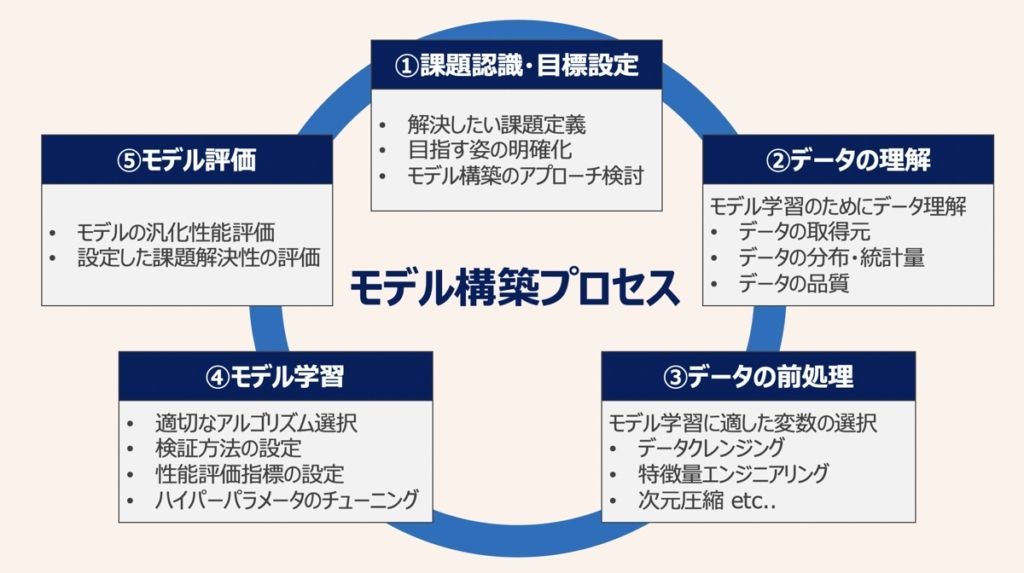
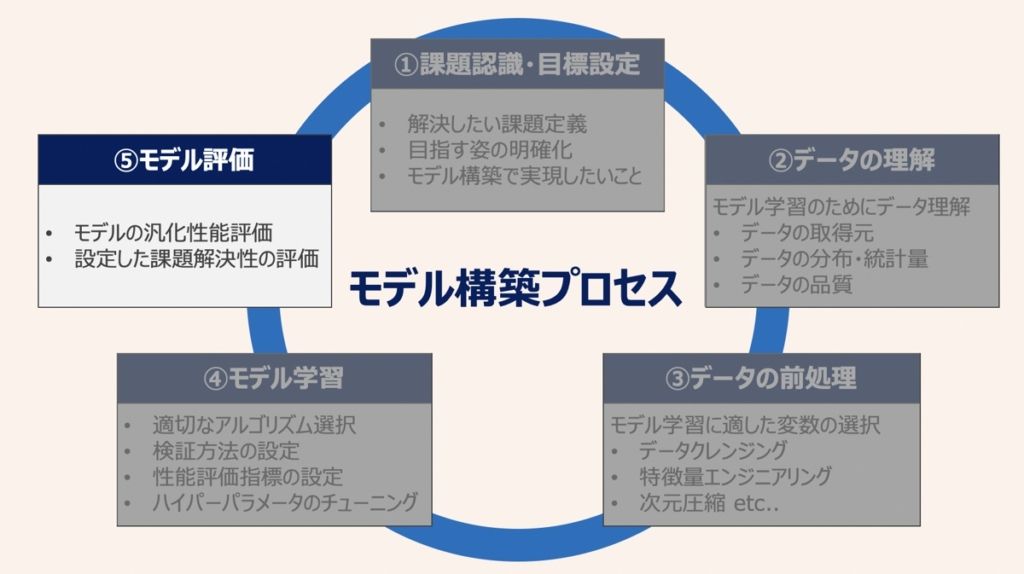
ここから具体的なプロジェクトの進め方を解説していきます。まず、進め方の全体像を把握しましょう。上図の①〜⑤がモデル構築における具体的なタスクに該当します。①〜⑤のサイクルを回しながら「モデルの性能を向上」させていくのが、モデル構築における分析アプローチの特徴です。以下それぞれのタスクについて詳しく見ていきましょう!
課題認識・目標設定

「現状の状況を十分に理解すること」「課題の明確化」がここでのポイントです。そして、課題解決に向けた方向性(目指す姿)を描き、機械学習モデル構築に向けて対象とすべき分析領域を特定します。
| 検討事項 | 作業内容 |
|---|---|
| 現状把握・課題定義 | 解決したいビジネス・業務の現状と課題を明確化 |
| 目指す姿の明確化 | 課題解決に向けて目指すべき姿を明確化 |
| 分析領域の特定 | 目指す姿に対して、分析モデルが担う役割・位置付けを定義 |
現状把握・課題定義
ビジネス・業務課題を明確化する具体的な作業内容として、例えば下記があります。
- 業務・現場担当者へのヒアリング
- 既存システム・分析モデルの仕様書・設計書確認
- 既存システム・分析モデルを包含する全体アーキテクチャの理解
目指す姿の明確化
対象のビジネス・業務シーンの現状・課題を整理した後は、課題解決に向けて目指す姿を明確化していきます。ビジネスシーンでは「売上向上と費用削減」、業務シーンでは「作業負荷削減」「属人業務の標準化」「自動化」というキーワードを具体的なKPIに設定し、目指す姿を定義することが多いと言えます。
分析領域の特定
課題と目指す姿が明確化できた後は、対象とすべき分析モデル像を描き、分析モデルの役割・支援範囲を特定します。簡易的な例を下記に示します。
| 課題定義 | 目指す姿 | KPI | 分析領域の特定 |
|---|---|---|---|
| 商品の売上停滞 | 顧客のニーズを正確に捉えて商品プロモーションできる仕組み構築 | 売上向上 | ・顧客属性の分析モデル ・レコメンドエンジン |
| 商品仕入れにおける 過剰発注・欠品が深刻 | 在庫管理システムを導入し在庫数を最適化 | コスト削減 | ・商品需要予測 |
| 工場ラインでの欠陥製品確認作業に時間がかかる | 工場ラインの製品チェックを自動化 | 人件費削減 | ・欠陥製品の異常検知 |
| 問い合わせの応対品質が 担当者によってバラバラ | 属人化スキルの標準化 | 顧客満足度向上 | ・AIチャットボット |
| 商品サイトのCVR低下 | 顧客毎に最適なサイトUI・UXを提供 | 商品購入率 | ・最適コンテンツ予測 |
ここで上記を整理する中で、解決すべき課題によって「分析モデルとして機械学習モデルを用いないケース(統計的手法を利用等)」も検討されうるでしょう。必ずしもAI・機械学習モデルの利用が課題に対して最適とは言えない場合ももちろんあるため注意しましょう。後述の説明に関しては「分析モデル=機械学習モデル」として説明していきます。
上記「分析領域の特定」検討に際して、さらに下記観点を深掘りすると、具体的なケースが描けるでしょう。
- どんなデータを用いるのか?
- モデル構築の目的は?
- モデルのインプットは?
- モデルの学習方法は?(教師あり、強化学習、教師なし)
- モデルの現場利用シーンとは?
- モデルのアウトプットイメージは?
タスクまとめ
課題認識・目標設定タスクでの整理結果例をいくつか紹介します。
【物流業務】商品在庫数の最適化
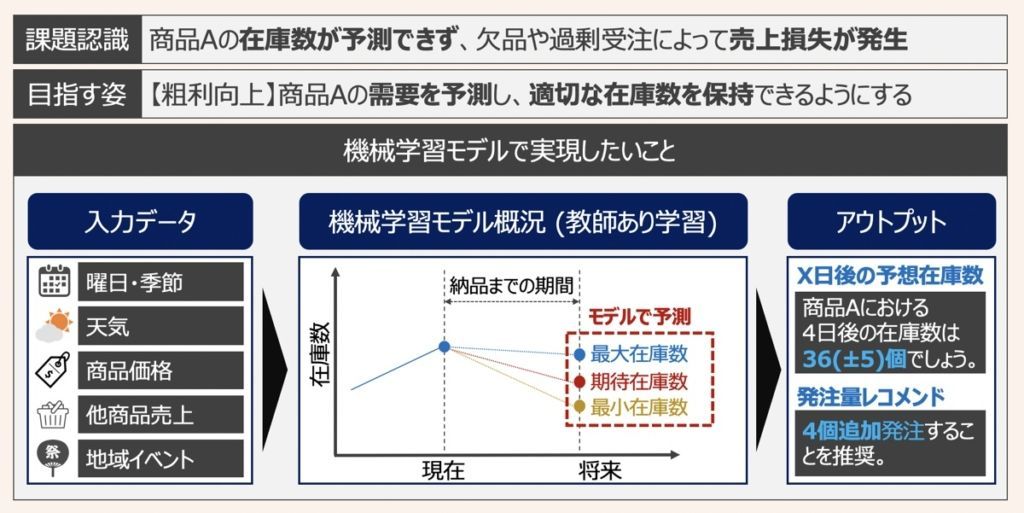
【商品販売】営業支援

データの理解
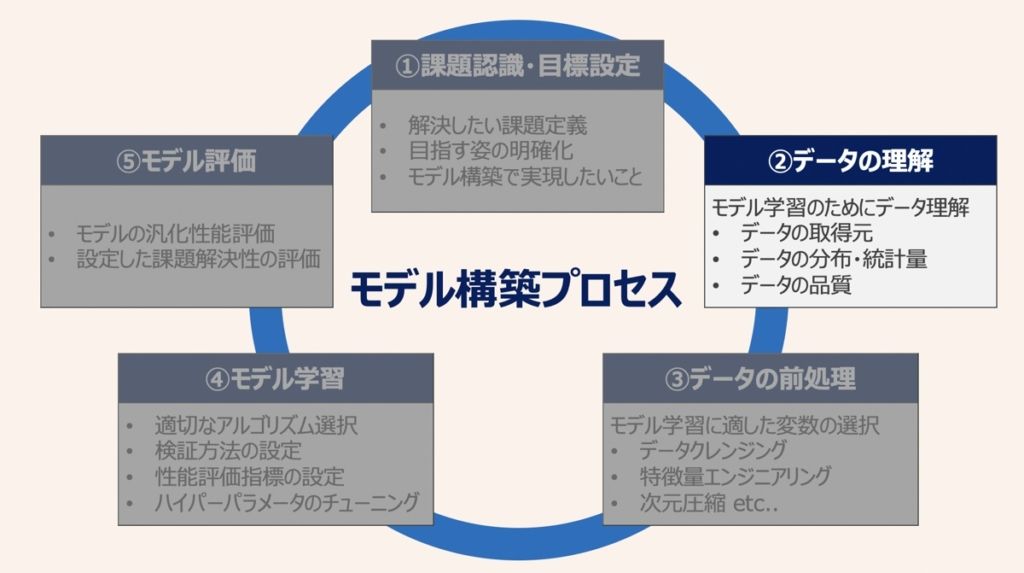
特定した分析領域上で利用するデータの理解がタスク内容であり、いきなりモデル作成に取りかからないことがポイントです。効率的な分析・PDCA循環を意識し、最適なモデルを構築するには、データのソース・取得方法・統計的性質・品質の十分な理解が大切です。その上で「分析シナリオ」の作成がここでは求められます。
| 検討事項 | 作業内容 |
|---|---|
| データソースの理解 | ・データの取得元確認 |
| データの取得方法の理解 | ・データ取得タイミング(日次・週次・月次) ・データ取得方法(オンライン・バッチ) ・データ取得容量 |
| データの統計的性質理解 | ・変数の意味(利用用途・単位等) ・統計量(平均値・中央値・尺度・標準偏差等) ・データの分布(傾向・ばらつき・外れ値等) ・欠損値の有無 ・変数同士の相関性 |
| データの品質理解 | ・データ量の適切性 ・データのバイアス(偏り) ・モデル構築に必要な変数有無 |
| 分析シナリオの作成 | 上記4観点を十分理解し、課題認識・目標設定タスク定義の「目指す姿」実現に向けて分析手順を設定 |
【具体的作業イメージ】データの統計的性質理解
- 統計情報の計算
- グラフ可視化(簡易な傾向分析や相関分析もここで実施)
グラフの可視化やデータ分析手法について、下記の記事で幅広く解説しています。
【具体的作業イメージ】分析シナリオの作成
- 機械学習モデルに用いる説明変数・目的変数の決定方法
- データクレンジング・特徴量エンジニアリングでの実施事項
- 機械学習アルゴリズムの候補
データの前処理
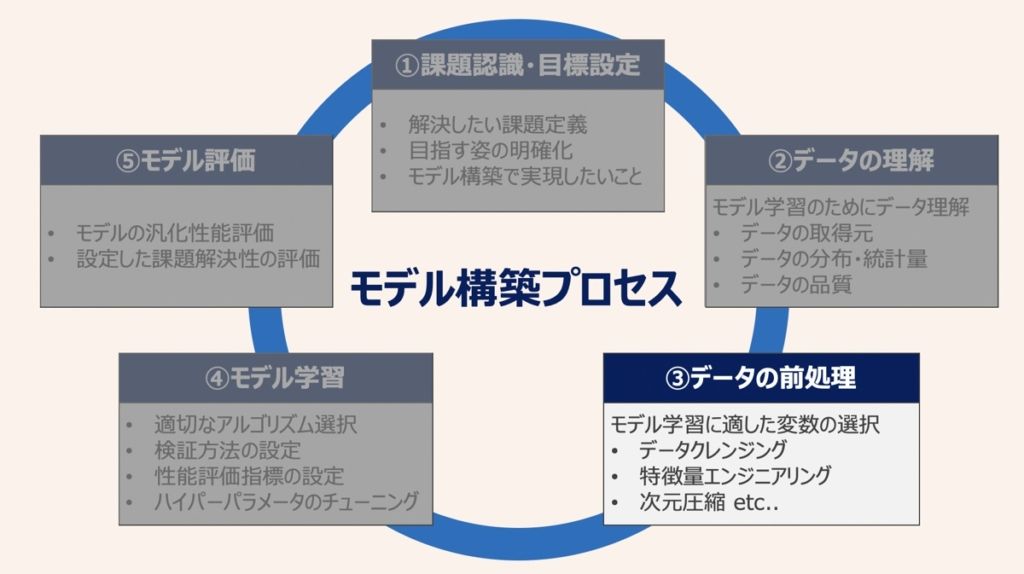
前述の分析シナリオに基づき、下記のようなデータの前処理を実行します。モデル構築する上で最適な説明変数と目的変数を準備することがここでのポイントです。
| 取組事項 | 作業内容 |
|---|---|
| データクレンジング | ・欠損値の削除や補完 ・外れ値の除去 |
| データスケーリング | ・正規化(特徴量を0〜1の範囲にスケーリング) ・標準化(最小・最大標準化等) |
| 特徴量エンジニアリング | ・特徴量の形式(数値・順序・名義特徴量)別処理 ・順序特徴量の数値化 ・名義特徴量のワンホット表現 ・その他新規特徴量の追加・加工 |
| 次元圧縮・特徴量の除外 | ・多重共線性を示す特徴量の削除 ・数値特徴量の次元圧縮(主成分分析等) ・低分散・標準偏差ゼロの特徴量の削除 |
| 目的変数・説明変数の決定 | ・統計的検定・変数絞込み(カイ二乗・分散分析等) ・モデルベースの変数絞込み(特徴量重要ランク付け) |
具体的なデータ前処理手法については、下記記事にて紹介しております。是非ご覧ください。
モデル学習
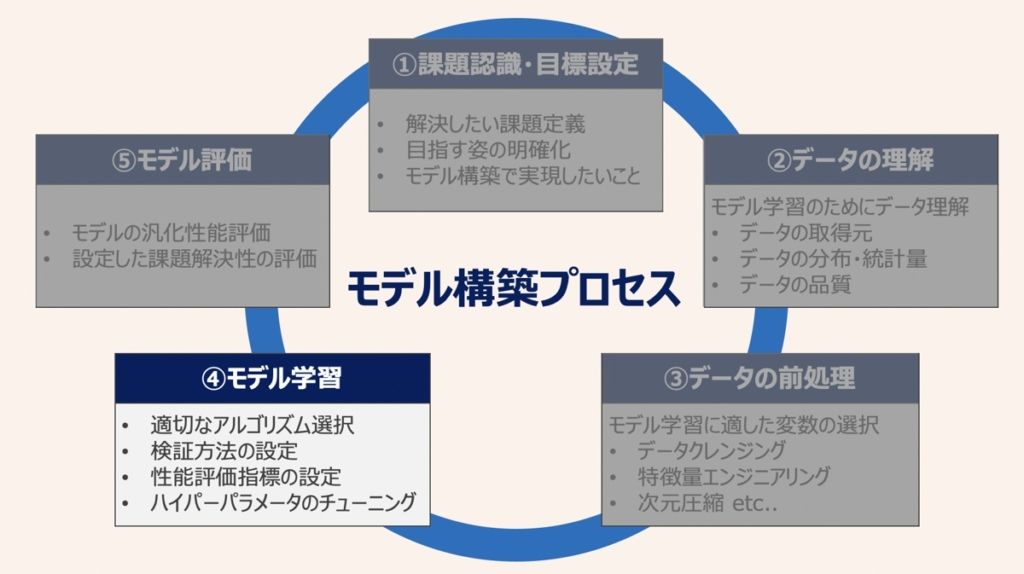
前述で決定した説明変数と目的変数を用いて機械学習モデルを構築することが本タスクのポイントです。プロジェクト全体として「②データの理解」及び「③データの前処理」に費やす作業量の割合は約8割と言われています。全体タスクとしての作業も残すところあとわずかです!
「④モデル学習」における具体的な検討事項は下記です。
| 検討事項 | 作業内容 |
|---|---|
| データセット作成 | ・前処理後データから説明変数・目的変数を抽出 ・学習とテスト用のデータセットをそれぞれ作成 |
| アルゴリズムの選択 | モデル用途に応じてアルゴリズムを選択 ・分類(決定木・SVM・ロジスティック回帰等) ・回帰(線形回帰・重回帰・多項式回帰等) ・構造化(階層クラスタリング、k平均法等) |
| 検証方法の設定 | テストデータを用いた検証方法 ・ホールドアウト ・k分割交差検証 |
| 説明変数の見直し | 【主にタスクサイクル2巡目以降で検討】 ・再帰的にモデルを構築し重要度(低)の変数削除 |
| ハイパーパラメータのチューニング | 【主にタスクサイクル2巡目以降で検討】 アルゴリズムのパラメータチューニング ・グリッドサーチ ・ベイズ最適化等 |
アルゴリズムの選択
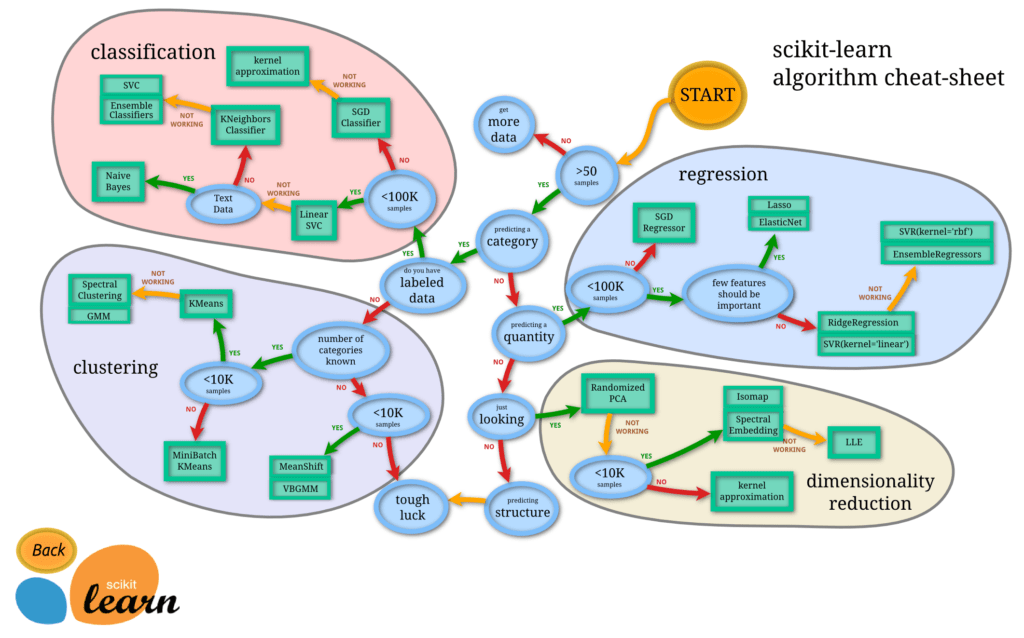
機械学習アルゴリズムを選択には、Scikit-learnホームページ掲載の上図を参考にするのがおすすめです。目的とするモデルイメージをもとにアルゴリズムを複数ピックアップしてモデルを作成し、性能比較します。
検証方法の設定
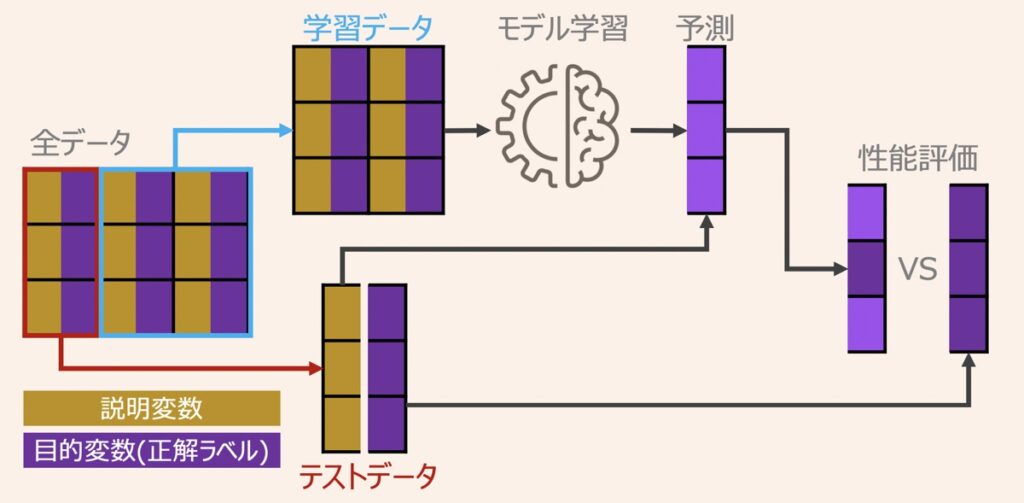
テストデータを活用したモデル検証方法として「ホールドアウト検証」と「K-分割交差検証」という代表的な2つの手法があります。具体的な内容は下記で紹介していますため是非ご覧ください。
【AI・機械学習】ホールドアウト検証とK分割交差検証(K-foldクロスバリデーション)|モデル性能の評価
機械学習モデルの予測性能を検証する方法として「ホールドアウト検証」と「K-分割交差検証(K-foldクロスバリデーション)」という代表的な2つの手法があります。本記事ではこれらの検証方法について解説します。
ハイパーパラメータチューニング
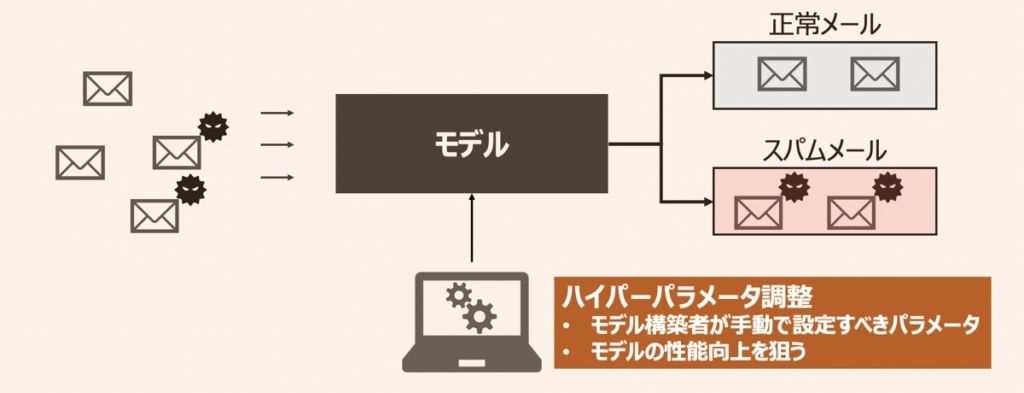
ハイパーパラメータのチューニングによって達成したいことはモデルが陥る学習不足および過学習の状態を解消すること、それに付随してモデルの性能を改善することです。具体的な内容は下記で紹介しています。
【AI・機械学習】ハイパーパラメータとは・モデルチューニングの最適化手法(グリッドサーチ・ベイズ最適化等)を徹底解説
機械学習における「ハイパーパラメータの概要・最適化手法」の解説記事です。本記事読了後は、ハイパーパラメータとは何か理解できるとともに、要所に応じた最適なチューニング方法(グリッドサーチ・ランダムサーチ・ベイズ最適化等)を把握できるようになるでしょう。
モデルの性能評価
構築した学習済みモデルの汎化性能評価が本タスクの目的です。加えて、作成したモデルが初段階で検討した「課題・目指す姿・分析領域と正しくマッチしているものであったか」についても検証が必要です。
| 検討事項 | 作業内容 |
|---|---|
| 汎化性能評価(分類問題) | 正解率・適合率・再現率等を用いて性能評価 |
| 汎化性能評価(回帰問題) | 決定係数・MAE・RMSE等を用いて性能評価 |
| 汎化性能評価(構造化) | エルボー法、シルエット図等を用いて性能評価 |
| 課題解決性の全体評価 | 本プロジェクトで設定した「課題・目指す姿・分析領域」と整合が取れているか評価 |
汎化性能の評価
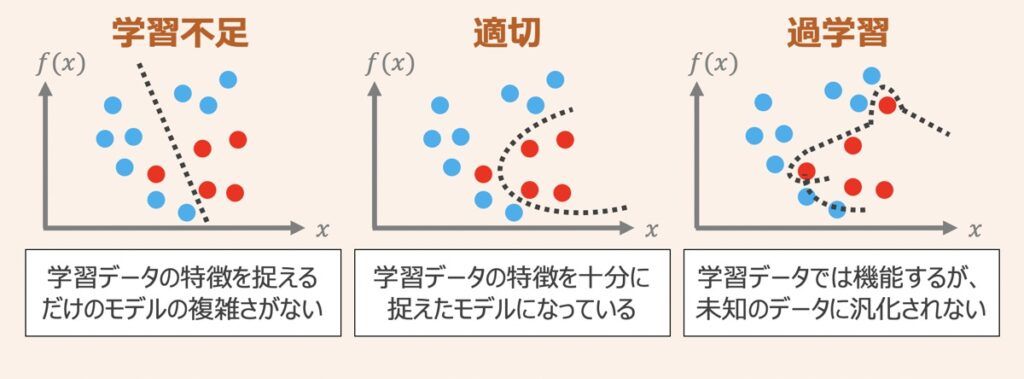
機械学習モデル自体の必須要件として、学習済みモデルが未知のデータの予測できるようになることがあります。この未知のデータに対する予測精度を汎化性能と呼び、機械学習モデル構築プロジェクトでは汎化性能の評価に基づき、モデルの性能改善を行なっていきます。以下具体的な評価指標算出方法について紹介します。
分類問題
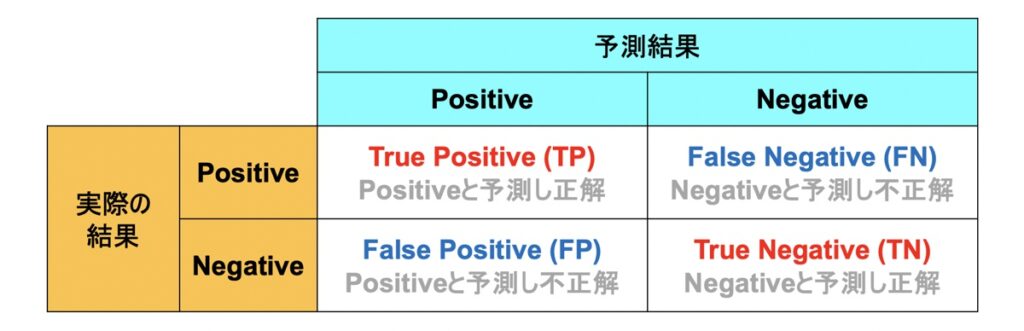
分類問題の場合、テストデータと機械学習モデルから得られる混同行列をもとに、性能評価を行います。評価指標は正解率・適合率・再現率等が用いられます。分類問題における具体的な評価指標概要は下記記事で解説しています。
【AI・機械学習】分類モデルの性能評価および評価指標の解説|正解率・適合率・再現率・F値・特異度・偽陽性率
機械学習における分類モデルの性能評価方法について解説します。本記事読了いただくことで、機械学習の集計データに基づきモデルを多様な角度から評価することができるようになります。
回帰問題
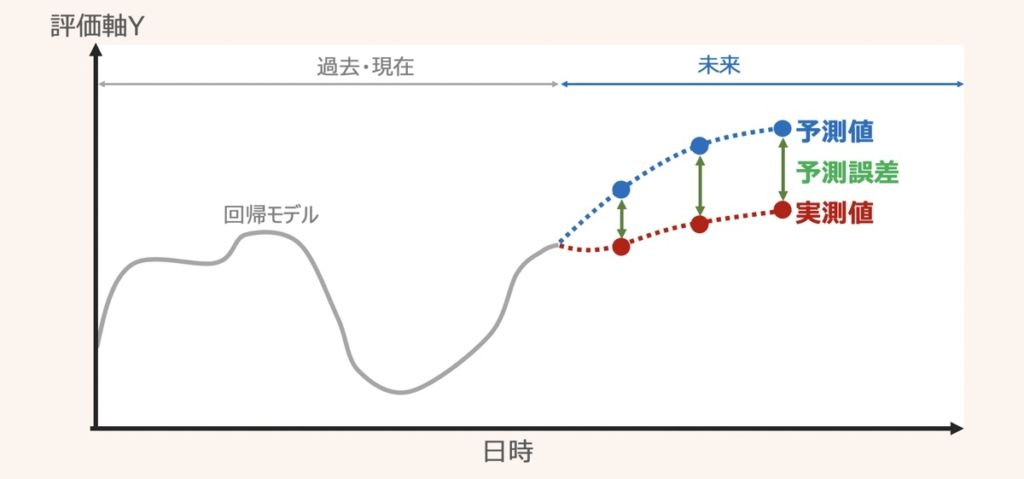
回帰問題の性能評価は、予測値と実測値の数値の差分である「予測誤差」によって評価するのが基本です。この予測誤差が小さいほどモデルの性能が良いと判断します。評価指標は決定係数、平均二乗誤差(RMSE)や平均絶対誤差(MAE)等が用いられます。具体的な評価指標概要は下記記事で解説しています。
【AI・機械学習】回帰モデルの性能評価および評価指標の解説|決定係数・RMSE・MAE・残差プロット
機械学習の性能評価方法の中で「回帰モデルはどうやって評価するの?」本記事ではその疑問に回答します。具体的に、決定係数、RMSE、MAE等の評価指標があり、それら特徴・利用シーンを1つずつ詳しく解説します。
課題解決性の全体評価
構築した機械学習モデルが当初検討した課題の解決に向けてどれほど貢献できるものであったかを評価します。その評価結果をもとに、さらなる改善ポイントを洗い出します。加えて、①〜⑤タスクサイクルを繰り返していく中で分析シナリオやモデルを再設計し、最適と言えるモデル構築を目指します。
【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
