
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- 機械学習モデルの予測性能を検証するホールドアウト検証およびK-分割交差検証(K-foldクロスバリデーション)について詳しく知りたい!
テストデータを用いた予測結果の検証について
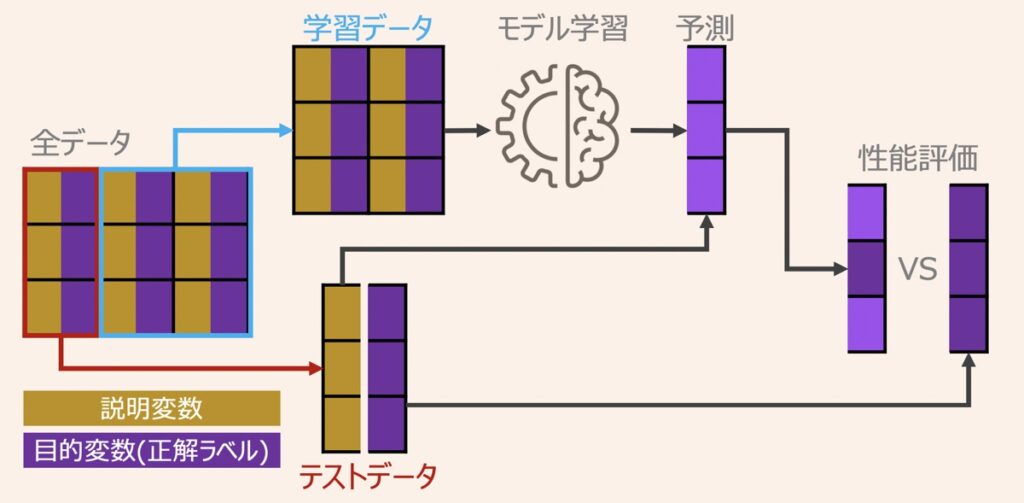
機械学習全般での重要ステップとして、学習済みモデルが未知のデータの予測できるようになることがあります。この未知のデータに対する予測精度を汎化性能と呼びます。
モデル学習は、学習データを基準にパラメータを更新して、学習データ内に限った予測性能向上を目指している段階であるため、その時点で汎化性能は保証されていません。汎化性能を正確に評価するには、全てのデータセットを学習データとして利用するのではなく、学習データと汎化性能を評価するためのテストデータに分割して利用するのが好ましいと言えます。
さらに、モデルのハイパーパラメータチューニイングまで考慮する場合、学習データとテストデータに加え、検証データを用意するのが好ましいです。各データの役割を下記に示しましたため、違いを整理しておきましょう。
| データ | 役割 |
|---|---|
| 学習データ (トレーニングデータ) | モデルを学習するために用いる。 |
| 検証データ | 学習データを構築したモデルから誤差を評価するために用いる。 ハイパーパラメータの最適化や、過学習の兆候発見が主な目的。 |
| テストデータ | 全ての学習過程が終わったタイミングでモデルの汎化性能の評価で用いる。 |
学習データとテストデータを分割した代表的な検証方法として「ホールドアウト検証」と「K分割交差検証」があります。本記事ではこれら2つの検証法について後述します。
ホールドアウト検証(Holdout Method)
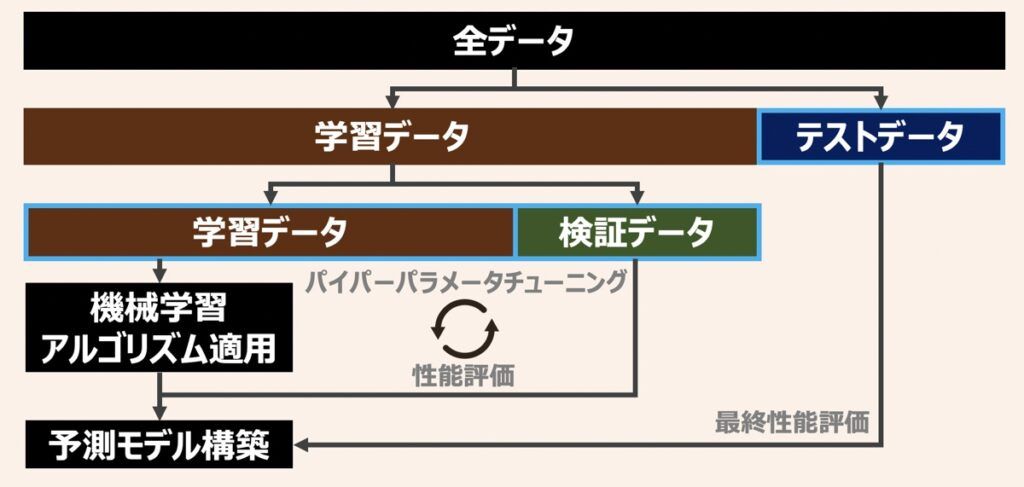
ホールドアウト検証とは、全てのデータセットを任意の割合で学習データ、検証データ、テストデータに分割して検証する方法であり、機械学習モデルの汎化性能評価に際して従来より使用されている一般的な検証方法です。
ホールドアウト法において、学習データは、モデルの学習に使用されます。検証データは、機械学習全般においてハイパーパラメータを最適化するために使用されたり、過学習兆候を洞察するために利用されます。一方で、定められたハイパーパラメータをもとにモデル学習を行うする際は、検証データを利用しないこともあります。テストデータは、最終的なモデルの汎化性能の評価に用います。
一般に学習・テストデータで分割する際の割合は、{学習データ:テストデータ=8:2}や{9:1}が広く採用されています。検証データも用いる際は、{学習データ:検証データ:テストデータ=8,1,1}や{7,1,2}がよく採用される印象です。この割合は一概に正解はないため、用いるデータの状態に応じて柔軟に変更してみましょう。
ホールドアウト検証には1つ問題があります。それは分割したデータに偏りがある場合に正確な検証ができなくなることです。つまり、偏りのあるデータが多数混在するデータセット用いる際は、偏りに性能評価が影響されない検証方法が望まれます。その代表的な方法としてk分割交差検証があります。以下k分割交差検証の特徴を後述します。
K-分割交差検証(K-fold Cross-validation)

k分割交差検証とは、全てのデータがテストデータとして利用されるよう、学習データとテストデータをk個に分割して性能評価する方法です。
具体的に下記のような手順で実行されます。
- データセットをランダムにk個分割する
- k-1個を学習データ、1個をテストデータとして割り振る
- 割り振った学習データでモデルを構築し、テストデータで予測性能を推定する
- 1~3の手順をk回繰り返す
- それぞれのモデルから得られた予測性能をもとに平均性能を計算する
k分割交差検証は一般にモデルのハイパーパラメータチューニングの際に用いられることが多いです。また、一般的にk=10で指定されることが多いです。
ここでk分割交差検証とは、ホールドアウト検証で問題に挙がった「データの偏りから発現しうる不安定な性能評価」を克服した検証方法でした。そのため、そもそもデータの偏りが発現しずらいほど十分なデータ量を使用している場合は、k=5のように、kの値を小さくすると良いかもしれません。k分割交差検証においてkの値が大きくなりすぎると、検証に対する計算コストが増大します。加えて、性能評価の分散(バリアンス)が高くなる傾向にあり、モデルの平均性能が正確に推定できなくなる可能性があります。
反対に小さなデータセットを扱う場合は、kの値を大きくすると良いでしょう。イテレーション数k回の繰り返しで利用される学習データが増えるため、汎化性能の評価に対する偏り(バイアス)を低く抑えることができます。
一つ抜き交差検証(Leave-one-out交差)
Leave-one-out交差検証とは、すべてのデータから1データずつ抜き出したものを検証データとし、残りの全てを学習データとする手法を指します。
具体的に下記のような手順で検証が行われます。
- 例えば、データ数が100個あるデータセットを用いる場合、まず、データセットを100分割する。
- 1番目の1データを検証用に、残り99データを学習用に用いて学習・検証を実行
- 2番目の1データを検証用に、残り99データを学習用に用いて学習・検証を実行
- 3番目・・・・
- 100番目・・・
このように、得られるデータ数に応じたパターン全てを学習・検証できるのが特徴であり、総合的にモデルの精度を検証することができます。
| 特徴 | 概要 |
|---|---|
| メリット | ホールドアウト法やK-分割交差検証と比較し、多くの学習データをとれるため、 モデルの精度向上が見込める。 |
| デメリット | データ数に比例して計算量が増大するため、学習コストがかかる。 近年ではデータ数が多くない場合に限り利用される傾向にあり。 |
【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
