
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- 機械学習における「ハイパーパラメータの概要・最適化手法」について詳しく解説!
- ハイパーパラメータの概要、チューニング手法(グリッドサーチ・ランダムサーチ・ベイズ最適化等)の概要・違いを詳しく解説!
【AI・機械学習】ハイパーパラメータとは
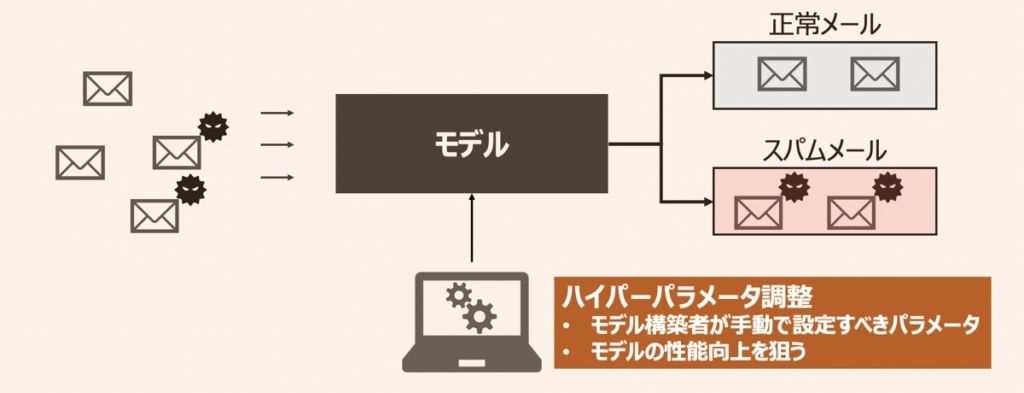
機械学習モデルを活用したアプリケーションには、設計者・モデル構築者が設定しなければならないパラメータが多数あります。それらパラメータを「ハイパーパラメータ」と呼びます。
ここでハイパーパラメータとは「モデル学習する前段階で設定するパラメータ」を指すことに注意しましょう。例えば、特徴量の特徴抽出方法やモデル(SVMや決定木等)の種類や設定時のパラメータがハイパーパラメータに該当します。反対に、学習によって更新されていくパラメータはハイパーパラメータではないことを区別しましょう。下記具体例をもとにイメージを深めましょう!
ニューラルネットワーク:ハイパーパラメータに該当する例
- ニューラルネットワークの層の数
- 各層に設定したユニット(パーセプトロン)数
- 損失関数を最小化するパラメータ探索アルゴリズムの種類(勾配降下法・Adam等)
- 上記探索アルゴリズム利用時に設定する引数
- 学習率
ニューラルネットワーク:ハイパーパラメータではない例
- 重み
ハイパーパラメータをチューニングする目的
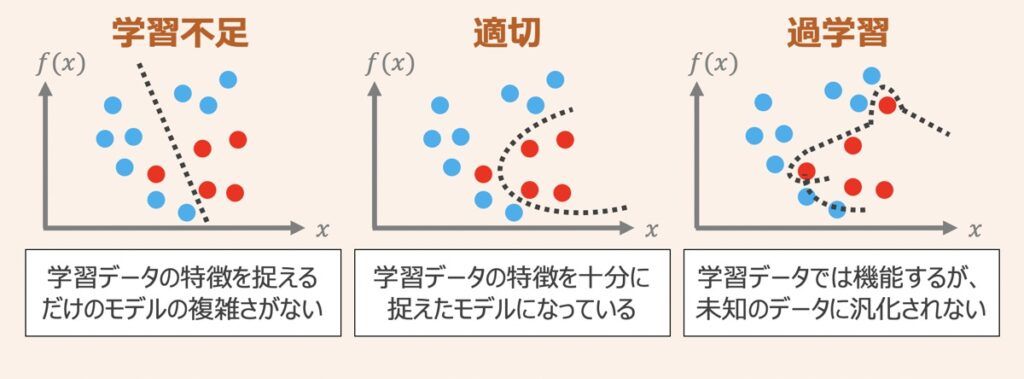
ハイパーパラメータのチューニングによって達成したいことは、モデルが陥る学習不足および過学習の状態を解消すること、それに付随してモデルの性能を改善することです。
上図を例にした、適切なグラフ形状を推定できるモデルの構築過程を考えてみましょう。この場合、ハイパーパラメータは直線・二次関数・多次元関数を形づけるための変数だとします。上図(左)の場合、モデルは直線であり、これだと単純すぎて学習データの特徴が捉えられていないことが分かります。一方で、上図(右)のような多次元グラフになると、過度に学習しすぎたあまり、グラフは複雑化し、未知のデータに対する汎化性能が低くなってしまいます。ハイパーパラメータのチューニングではこのような二極化した状態から抜け出し、上図(中)の状態を目指していくことを目的としています。
| 学習不足 | 十分にモデル学習できておらず性能が低い状態。 本来学習データに対して予測・分類精度が低い場合、学習不足と言う。 |
| 適切 | 学習データに対する予測・分類精度が高く、同時に汎化性能も高い状態。 |
| 過学習 | 学習データに対して過剰にフィッティングした状態。 学習データに対する予測・分類精度は高いが、汎化性能は低いことが特徴。 |
ハイパーパラメータ探索と最適化手法
前述の例では多次元グラフを用いたモデルという比較的シンプルな場合を考えました。一方で実際のモデル構築場面では、パラメータの値が大量にある中で、どの値の組み合わせが最適なのか考える必要があります。加えて、それを手作業でチューニングするとなると、膨大な時間がかかるため現実的な作業方法の検討が必要です。
上記理由から、近年のハイパーパラメータ探索作業は、オートチューニング手法を用いて自動で実施するのが主流となっています。今回ハイパーパラメータ探索手法としてよく用いられる下記をご紹介します。
- グリッドサーチ
- ランダムサーチ
- ベイズ最適化
グリッドサーチ
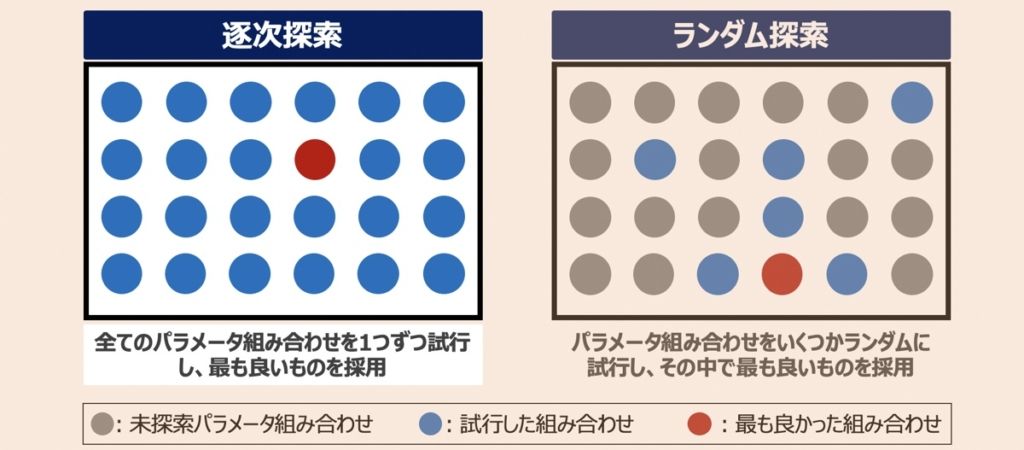
グリッドサーチとは、探索対象のパラメータ候補を列挙し、その全ての組み合わせを照らし合わせ、最適な組み合わせを見つけ出す探索手法です。一番シンプルなパラメータ探索手法であるものの、下記のようなメリット・デメリットがあります。
メリット
- 全て組み合わせを試行するため、ハイパーパラメータ候補の中で最も良いハイパーパラメータを必ず見つけ出せる
デメリット
- パラメータの候補数が多い場合、計算量が増大し、最適なパラメータを見つけ出すのに時間がかかる
- 上記に加えて学習データが膨大かつモデルが非常に複雑である場合、さらに計算量が増える。結果、時間的理由からグリッドサーチの利用が困難と判断することがある
Pythonによる機械学習プログラミングを学習している方向けに「グリッドサーチでハイパーパラメータ最適化・モデル構築」という解説記事も配信しております。適時ご参照ください。
【機械学習×Python】グリッドサーチによるハイパーパラメータ最適化方法を実演・ランダムフォレストによるモデル構築
本記事はPython機械学習プログラミングの解説記事です。「グリッドサーチをもとにハイパーパラメータの最適化ができるようになりたい」「ランダムフォレストでのモデル構築方法を知りたい」という方向けの内容となっています。
ランダムサーチ
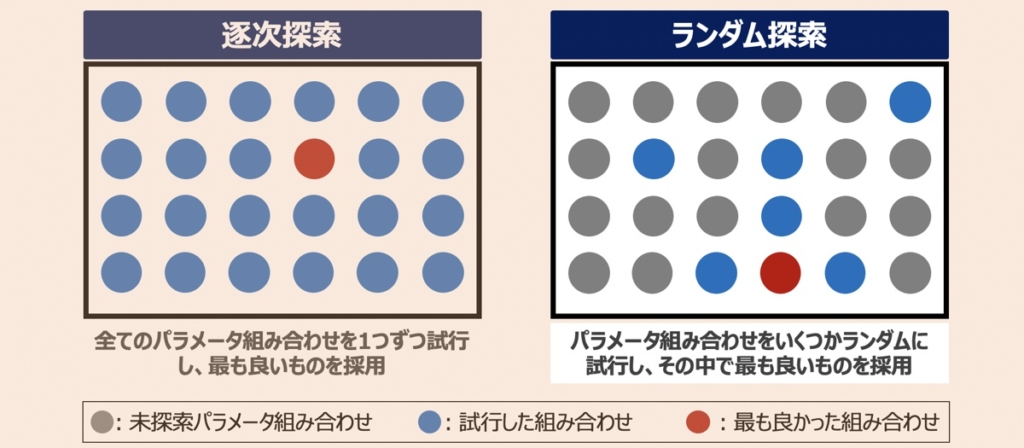
ランダムサーチとは、ハイパーパラメータの組み合わせをランダムに試行し、その中で最適なものを採用するパラメータ自動探索手法です。
メリット
- パラメータ探索上限回数を指定できるため、グリッドサーチのように計算量による時間的コストの課題が浮上しずらい
デメリット
- パラメータ探索上限回数を低く設定すれば、最適なパラメータの組み合わせを見逃す確率が上がる
このように、ランダムサーチの場合、パラメータ探索上限回数を設定することで、計算量による負荷を減らすことができます。一方で、定められた探索上限回数の中で、いかに効率的に最適なパラメータの組み合わせを探索できるかがポイントになるわけです。ここで、最適な組み合わせをより効率的に探索する手法として、下記のようなランダムサーチを改良した手法が用いられるようになりました。
ベイズ最適化
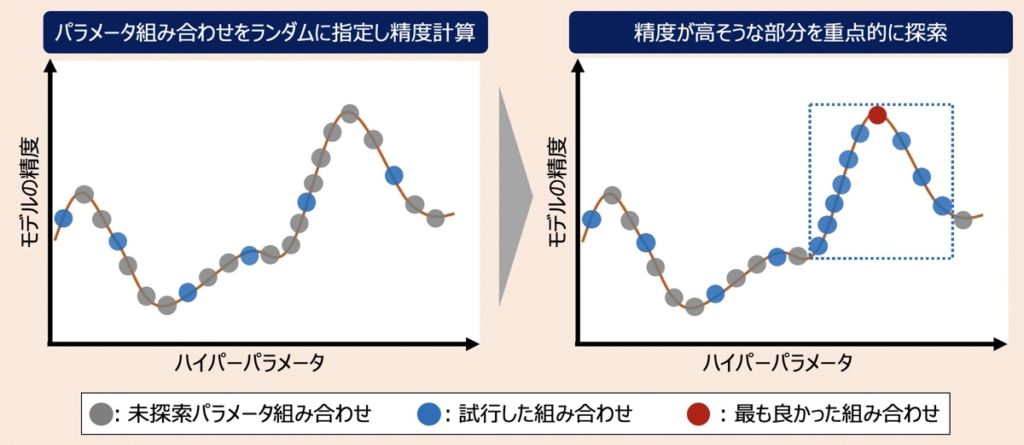
ベイズ最適化とは、ガウス課程と呼ばれる回帰モデルを利用して、最適なハイパーパラメータの組み合わせを見つけ出す手法です。最初の探索では広くランダムにパラメータ候補を指定し精度を求めていきます。続いて、ランダムに求めた精度をもとに、さらに精度が高くなりそうな組み合わせ候補を推定し、精度を計算していきます。このように、ランダム探索でパラメータ候補範囲を絞り、精度が上がりそうな観点を重点的に計算していくのがこの手法の特徴です。
メリット
- 計算量による時間的コストの課題が浮上しずらい
- 最適なハイパーパラメータの組み合わせを効率的に探索できる
デメリット
- ハイパーパラメータに離散値を用いる場合、パラメータ探索効率が落ちる
ベイズ最適化は上図のように回帰モデルを取り扱い「精度が最大値を取る箇所=最適なパラメータの組み合わせがある」という探索を行います。そのため、この方法上グラフの横軸として設定されているハイパーパラメータ候補は、連続値であることが好ましいと言えます。つまり、離散値のハイパーパラメーターを用いた場合、精度探索の計算量が自ずと増加してしまうため、探索効率に悪影響が及ぶことに注意が必要です。
ハイパーパラメータのチューニング作業を実行するタイミング
最適なハイパーパラメータの組み合わせは、ハイパーパラメータのチューニングで見つけ出すことができます。一方で、これら最適な組み合わせは、機械学習に用いる説明変数や学習データ量を修正する度に変わってしまうことに注意が必要です。そのため、パラメータチューニング後に学習データを増やしたり、説明変数の加工処理を行うと、再度ハイパーパラメータのチューニングが必要になります。
パラメータチューニングの実行順序には注意しましょう!初期のモデル構築では、データクレンジング・加工等の観点に集中し、精度アップを狙うのが好ましいです。これらを実施しても精度向上が見込めなくなった段階で、ハイパーパラメーターのチューニングを行うのが効率的でしょう。
【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
