
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- 機械学習の「分類モデル」の性能評価方法について詳しく知りたい!
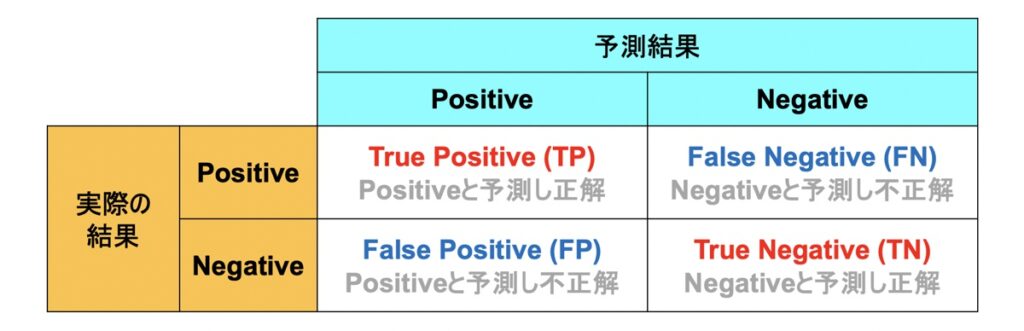
混同行列(Confusion Matrix)
本記事は機械学習教師あり学習における分類モデルを焦点に当て、その評価方法を解説します。分類モデルの評価は、回帰モデルと異なり、予測結果と実際の結果(正解ラベル)のとりうるパターンが複数考えられるのが特徴です。それら複数のパターンをクロス集計表に示した混同行列(Confusion Matrix)を用いて評価するのが基本となります。
例えば「Yes or No」「◯ or ×」「Positive or Negative」のように、一番単純な2種類の出力からなる分類問題であれば、予測結果と実際結果がとりうるパターンは2×2パターンであるため、混合行列は下記のように示されます。
| 用語 | 意味 | パターン例 |
|---|---|---|
| True | 予測が正解 | – |
| False | 予測が不正解 | – |
| Positive | 予測したい事象 | 商品購入 |
| Negative | 予測したい事象の反対 | 商品未購入 |
| True Positive(TP) | Positiveな実際の結果を正しくPositiveと予測した回数 | 予)商品買う! 実)買った! |
| False Negative | Positiveな実際の結果を間違ってNegativeと予測した回数 | 予)商品買う! 実)未購入・・ |
| True Negative | Negativeな実際の結果を正しくNegativeと予測した回数 | 予)買わない! 実)未購入! |
| False Positive | Negativeな実際の結果を間違ってPositiveと予測した回数 | 予)買わない! 実)買った・・ |
【参考】分類問題で取り扱う機械学習の代表的なアルゴリズムは下記になります。
- 決定木
- SVM
- ランダムフォレスト
- ナイーブベイズ
- ロジスティック回帰
- ニューラルネットワーク
分類問題で取り扱う代表的な評価指数
混合行列のTP、FP、FN、FNを用いた代表的な評価指標を紹介していきます。本記事で解説する評価指標は下記です。
- 正解率 (Accuracy)
- 適合率 (Precision)
- 再現率 (感度, Recall, True Positive Rate, TPR)
- F値 (F-measure)
- 特異度 (specificity, True Negative Rate, TNR)
- 偽陽性率 (False Positive Rate, FPR)
- ROC曲線とAUC
上記をPythonを用いて実際に出力してみたい方向けの記事もあります。適時ご参照ください。
【AI・機械学習】Python・Scikit-learnで分類問題の性能評価指標(正解率・適合率・再現率・F値)を出力
機械学習における分類問題の性能評価のために、Pythonで評価指標を出力する方法を解説します。ライブラリはScikit-learn(サイキット・ラーン)を用い、正解率・適合率・再現率・F値を出力するコーディング方法を学んでいきましょう!
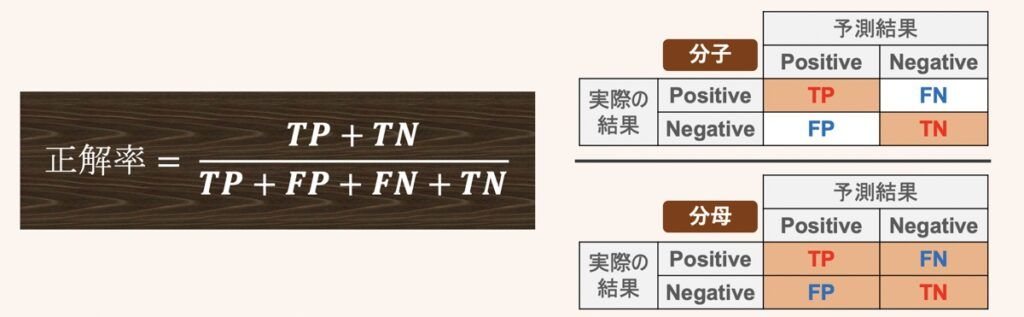
正解率 (Accuracy)
特徴
正解率は全体のデータから「Positive or Negative」という予測をした際、正しく予測できたデータの割合を示したものです。
注意点
正解率は分類モデルの精度を示す上で一番基本となる指標ですが、正解率だけでモデル性能を判断しようとすると、モデルの欠陥を見落とす可能性があります。例えば、下記が正答率のみだと評価が難しいケースに該当します。
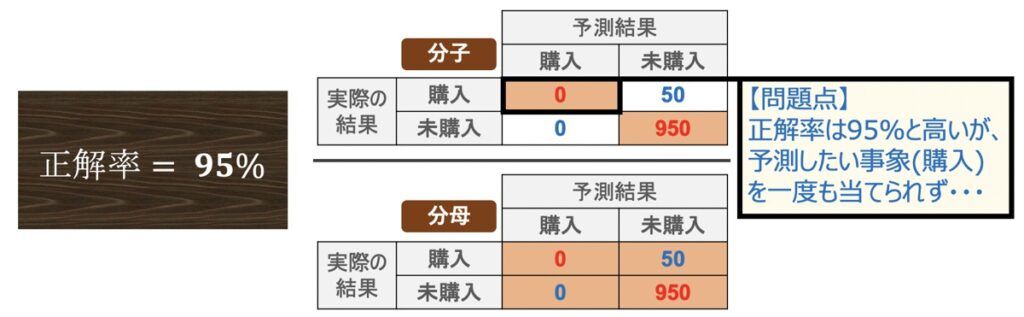
上記は商品を購入しそうな顧客に対して営業をしたい営業担当者がいたとします。この場合モデルの役割は「商品を購入してくれそうな顧客を正確に購入と予測すること」でしょう。上記の正解率は95%と予測がほとんど的中しているものの、真に商品を購入してくれそうな顧客は一度も「購入」と予測できていないことが分かります。これでは実際の現場に導入しても役に立つモデルとは言えませんね・・・
モデルをビジネスシーンに合った評価をするために、正解率に加えて適合率や再現率をしばし用いられます。以下それぞれの評価指標も見ていきましょう!
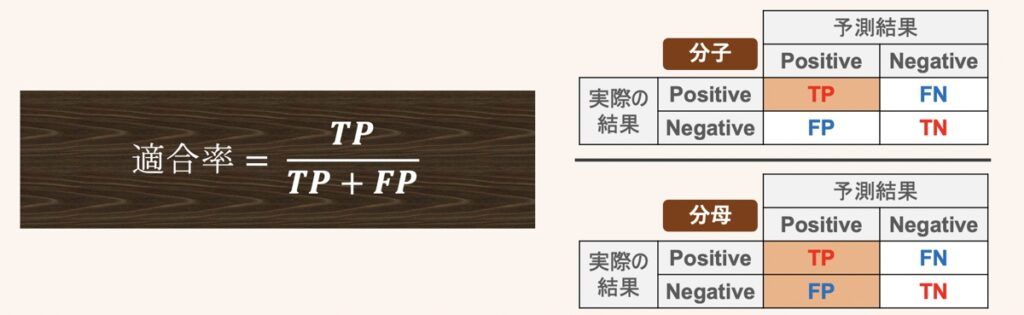
適合率 (Precision)
特徴
適合率はPositiveと予測した全データのうち、正しくPositiveと予測できた割合を示したものです。
適用例
適合率は「PositiveをNegativeとして間違って予測しても良いが、Negativeなものは確実にNegativeとして分類したい」場合の評価に用いられます。

例えば上図のように、商品の営業活動に機械学習モデルを取り入れたとします。営業活動の大半は予算と人的リソースに制約があるため、「多少商品に興味がある顧客(Positive)を見落とし売上機会を失っても良いから購入しない可能性が高い顧客(Negative)は正しく予測し営業活動しないようにしたい」と効率重視で考える傾向にあります。このようなケースでは適合率での評価が重要視されます。
一方で、生命活動に直結する癌診断等では「癌ではない(Negative)という予測が多少外れても良いから癌の疑いがある患者(Positive)は漏れなく抽出したい」というニーズがあるでしょう。これは癌であることを見逃してしまうことの方がリスクであるためです。癌である(Positive)を癌でない(Negative)と間違って予測したかどうかの評価は、適合率で正しく確認できないため、代わりに再現率を重要視して評価します。
再現率 (Recall)
特徴
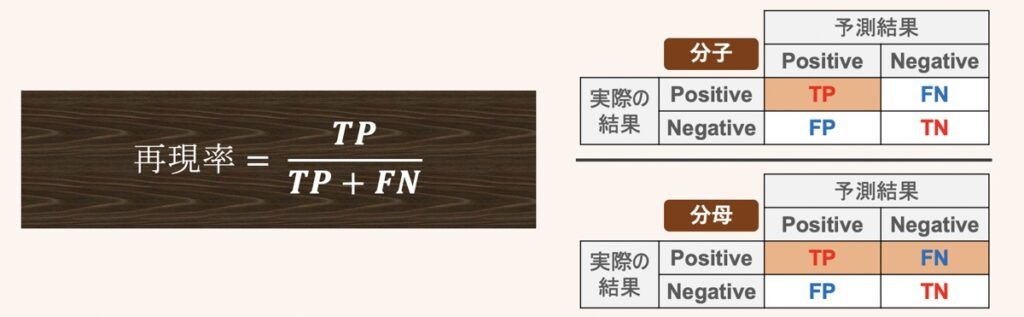
再現率は実際にPositiveだったデータのうち、正しくPositiveとして予測できた割合を示すものです。
適用例
再現率は「NegativeをPositiveと間違って予測しても問題ないが、Positiveは正しくPositveとして分類したい」場合の評価に用いられます。

上図のように、再現率は癌診断のような「本当は癌である(Positive)にもかかわらず間違って癌ではない(Negative)と予測してしまう危険性を回避し、癌の疑いがある患者(Positive)は漏れなく分類したい」というケースで重要視する評価指標です。
一方で、営業活動のように「多少商品に興味がある顧客(Positive)を見落とし売上機会を失っても良いから購入しない可能性が高い顧客(Negative)は正しく予測し営業活動しないようにしたい」というケースでは、再現率で正しく評価できないため、代わりに適合率を重要視して評価します。
F値 (F-measure)

特徴
F値は適合率と再現率の調和平均を取った評価指標です。
適合率と再現率とF値の関係
適合率と再現率はトレードオフの関係にあり、どちらかが大きくなるともう一方は小さくなります。そのため適合率の高さ重視のモデルや再現率の高さ重視のモデルというように、ビジネスシーンに分けて重視する評価指標を選ぶ場合が多々あります。一方でそれらビジネスシーンに共通して言えるのは、適合率と再現率のバランスも大切であるということです。故に、適合率と再現率の調和平均を取ったF値がモデルの総合評価指標として用いられるのです。
特異度 (specificity)
特徴
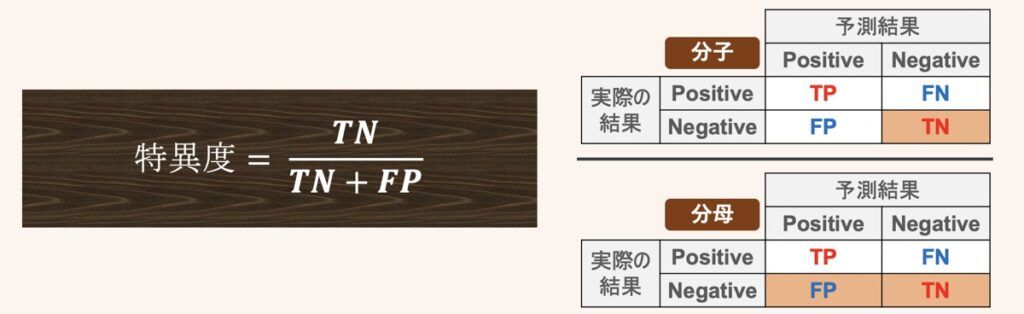
特異度は実際にNegativeだったデータのうち、正しくNegativeとして予測できた割合を示すものです。再現率のPositive/Negativeを反転させた指標になります。
偽陽性率 (False Positive Rate)
特徴
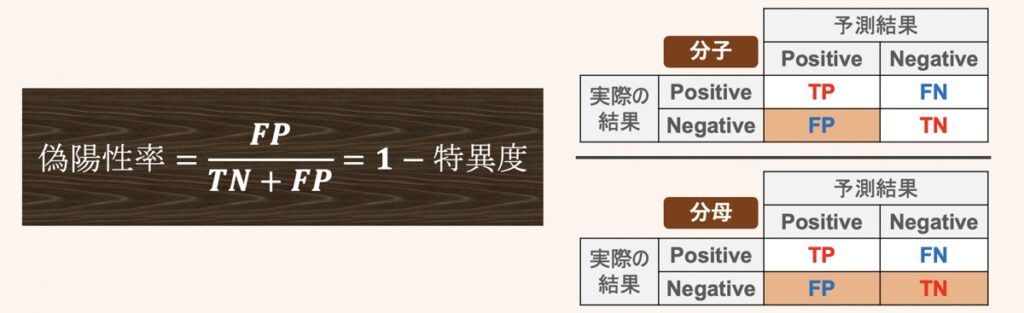
偽陽性率は実際にNegativeだったデータのうち、誤ってPositiveと予測してしまった割合を示すものです。上述した指標と異なり、小さければ小さいほど性能が良いと評価します。
ROC曲線とAUC
特徴
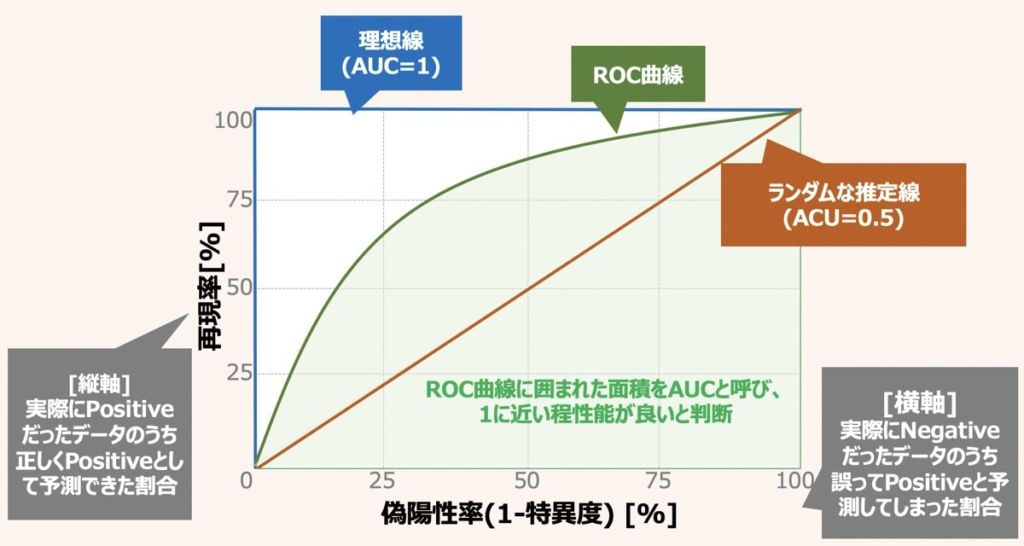
ROC曲線は機械学習分類モデル、特に2値分類モデルに特化した評価指標であり、縦軸に再現率、横軸に偽陽性率を用いるのが特徴的です。
実際の評価では、ACUと呼ばれるROC曲線に囲まれた面積を用いて分類モデルを定量評価します。面積は0〜1の範囲で値を取り、AUCが1に近いほど分類モデルの性能が高いと判断するのです。
ROC曲線およびAUCは下記記事で詳しく解説しています。ぜひご覧下さい。
【AI・機械学習】ROC曲線・PR曲線・AUC|2値分類モデルの性能評価方法を解説!
本記事では機械学習分類モデルの評価指標として用いる「ROC曲線」「PR曲線」「AUC」それぞれの意味・違い・評価方法を詳しく解説します。
【参考】回帰モデルの評価について
今回は機械学習における教師あり学習の「分類モデル」の評価指標について詳しく解説しました。「回帰モデル」についても当サイトでは詳しく解説しておりますため、是非ご覧ください。
【AI・機械学習】回帰モデルの性能評価および評価指標の解説|決定係数・RMSE・MAE・残差プロット
機械学習の性能評価方法の中で「回帰モデルはどうやって評価するの?」本記事ではその疑問に回答します。具体的に、決定係数、RMSE、MAE等の評価指標があり、それら特徴・利用シーンを1つずつ詳しく解説します。
【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
