
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- Pythonによる多項式回帰モデルの作成と評価方法について詳しく学びたい
- 機械学習における回帰モデルの作成方法に興味がある
多項式回帰とは
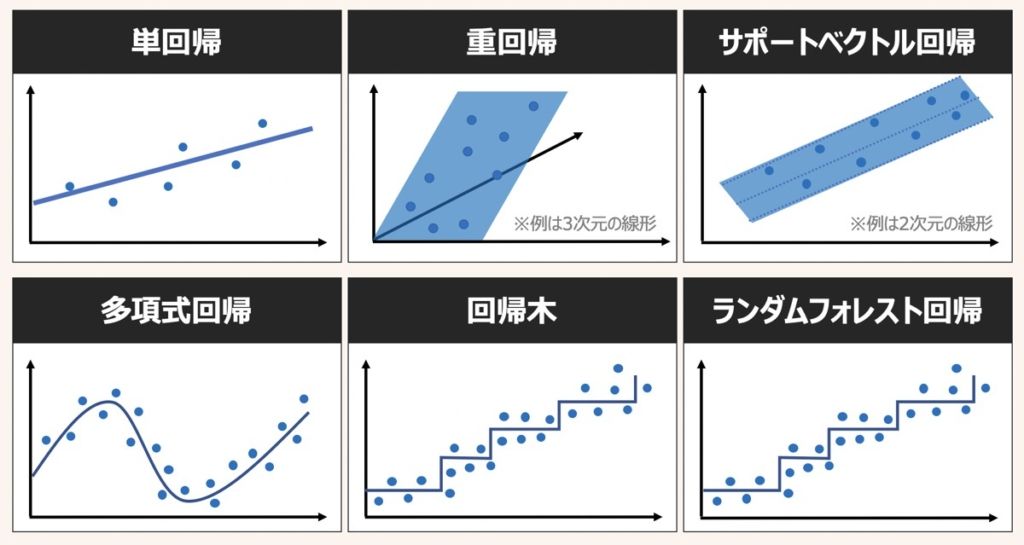
回帰分析とは(カテゴリ値や離散値ではなく)連続値に基づき、ある結果を予測する分析手法を指します。
回帰モデルとは、回帰分析をもとに1つ以上の独立変数(説明変数)と連続値の従属変数(目的変数)との関係を表現したものを指します。
多項式回帰モデルとは、説明変数と目的変数の関係が二次・三次関数のような非線形の分布として表されるモデルを指します。
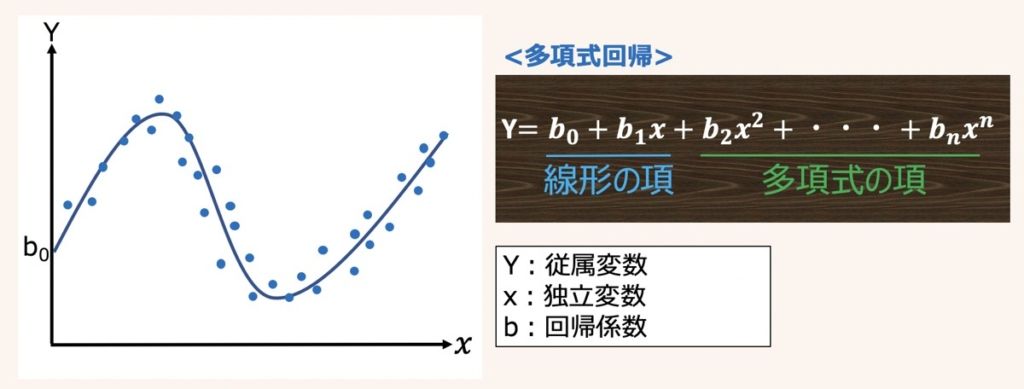
多項式の方程式は、線形回帰方程式に多項式の項が追加された形として上図のように表されます。
ここで、回帰分析の理論的な概要が知りたい方はこちらの記事で解説していますため、合わせてご覧下さい。
線形単回帰・重回帰分析とは?|回帰モデル導出・評価における統計学的理論や機械学習への応用方法を徹底解説
「単回帰・重回帰分析の概要」「回帰モデル作成時の評価方法やモデル性能改善方法」について詳しく知りたい方向けの記事です。
本記事ではPythonを用いて多項式回帰モデルを作成・評価する方法について解説します。
【事前準備】多項式回帰モデル作成に必要なデータ
実際にPythonのScikit-learnライブラリを用いて多項式回帰モデルを構築していきましょう!下記の手順でプログラムを構築していきます。
- データセットの説明
- データの準備
- 回帰モデル学習
- モデル性能評価
今回は機械学習モデル過程で必須となるデータクレンジングやグラフ可視化等の前処理プロセスは割愛しています。その代わり、モデル作成と評価方法を詳しく解説しております。
データクレンジングやグラフ可視化を通じて回帰モデル作成について言及した記事も配信しています。合わせてご覧下さい。
【機械学習・Python】線形単回帰・重回帰分析に基づき予測モデルを作成|scikit-learnでモデル開発・評価
Pythonとscikit-learnを用いて単回帰および重回帰モデルを作成・評価する方法について解説します。
データセットの説明

データセットには、Boston Housingというデータセットを活用します。
1970年代後半におけるボストンの住宅情報とその地域における環境をまとめたデータセットであり、住宅価格の予測を目的とした回帰モデル作成のチュートリアルによく利用されます。
Boston Housingデータセットの説明変数および目的変数の概要はそれぞれ以下になります。
説明変数一覧
| 特徴量名 | 概要 |
|---|---|
| CRIM | (地域人工毎の)犯罪発生率 |
| ZN | 25,000平方フィート以上の住宅区画の割合 |
| INDUS | (地域人工毎の)非小売業の土地面積の割合 |
| CHAS | チャールズ川沿いに立地しているかどうか(該当の場合は1、そうでない場合は0) |
| NOX | 窒素酸化物の濃度(単位:pphm) |
| RM | 平均部屋数/一戸 |
| AGE | 1940年よりも古い家の割合 |
| DIS | 5つのボストン雇用センターまでの重み付き距離 |
| RAD | 主要な高速道路へのアクセス指数 |
| TAX | 10,000ドルあたりの所得税率 |
| PTRATIO | (地域人工毎の)学校教師1人あたりの生徒数 |
| B | (地域人工毎の)アフリカ系アメリカ人居住者の割合 |
| LSTAT | 低所得者の割合 |
目的変数一覧
| 特徴量名 | 概要 |
|---|---|
| MEDV | 住宅価格の中央値(単位 $1,000) |
データの準備
前述したBoston Housingのデータセットを準備するために以下のコードを実行しましょう。
# データ前処理
import numpy as np
import pandas as pd
# データ可視化
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("ggplot")
# %matplotlib inline
# グラフの日本語表記対応
from matplotlib import rcParams
rcParams["font.family"] = "sans-serif"
rcParams["font.sans-serif"] = "Hiragino Maru Gothic Pro"
# データセット読込
from sklearn.datasets import load_boston
boston = load_boston()
# DataFrame作成
df = pd.DataFrame(boston.data)
df.columns = boston.feature_names
df["MEDV"] = boston.target【実践】多項式回帰モデル(次数=2)の作成・評価
次に示すような説明変数および目的変数を用いて多項式回帰モデルを作成します。
| 説明変数 | LSTAT(低所得者の割合) |
| 目的変数 | MEDV(住宅価格の中央値) |
回帰モデルの学習
今回多項式の次数=2として多項式回帰モデルを作成します。以下のコードを実行しましょう。
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.model_selection import train_test_split
""" モデル準備 """
# モデルの変数
X = df[['LSTAT']].values # 説明変数
y = df['MEDV'].values # 目的変数
# 学習・テストデータ分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
""" 多項式が2次の項を追加 """
# 回帰モデルのインスタンス化
model_reg = LinearRegression()
# 2次の多項式特徴量のクラスをインスタンス化
quadratic = PolynomialFeatures(
degree=2, # 多項式の次数
interaction_only=False, # Trueの場合、ある特徴量を2乗以上した項が除かれる
include_bias=True, # Trueの場合、バイアス項を含める
order='C' # 出力する配列の計算順序
)
# データ演算・変換
X_quad_train = quadratic.fit_transform(X_train)
# 回帰モデルに上記データを適合
model_reg.fit(X_quad_train, y_train)
""" データプロット """
# 多項式曲線を描くためのプロット
X_fit = np.arange(X_train.min(), X_train.max(), 1)[:, np.newaxis]
X_quad_fit = quadratic.fit_transform(X_fit)
y_quad_predict = model_reg.predict(X_quad_fit)
plt.plot(X_fit,
y_quad_predict,
label='quadratic (d=2)',
color='blue',
lw=3,
linestyle='--'
)
# トレーニングデータのプロット
plt.scatter(X_train, y_train, label='トレーニングデータ', color='lightgray')
# グラフの書式設定
plt.xlabel('LSTAT(低所得者の割合)')
plt.ylabel('MEDV(住宅価格の中央値)')
plt.legend(loc='upper right')
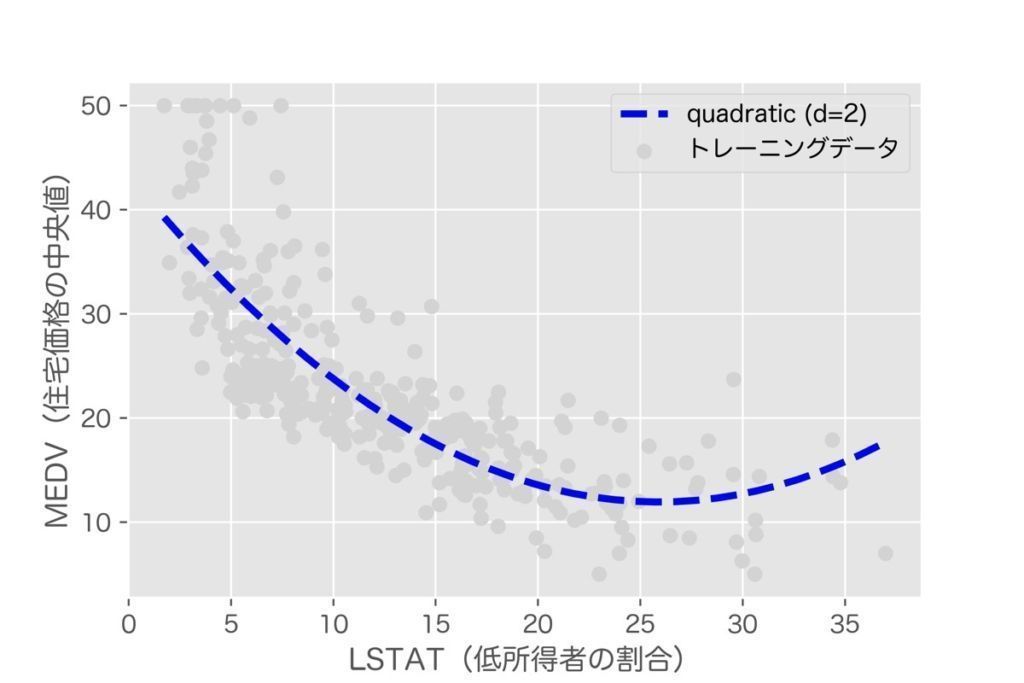
plt.show()PolynomialFeaturesメソッドの概要
回帰モデル作成の際に用いるscikit-learnのLinearRegression()メソッドに対して、PolynomialFeatures()メソッドを適用することで多項式回帰モデルを作成しています。
ここでPolynomialFeatures()メソッドで利用する引数情報を下記に示します。
quadratic = PolynomialFeatures(
degree=2,
interaction_only=False,
include_bias=True,
order='C'
)| 引数名 | 概要 | デフォルト |
|---|---|---|
| degree | 多項式の次数 | 必須 |
| interaction_only | Trueの場合、ある説明変数を2乗以上した項が除かれる | False |
| include_bias | Trueの場合、バイアス項を含める | True |
| order | 出力する配列の計算順序 | ‘C’ |
degreeは多項式の次数を決定する引数です。この値に手を加えることで、2次関数や3次関数等の分布を表現できるようになります。
【評価】RMSEおよび決定係数R2を用いた性能評価
RMSE(平均平方二乗誤差)と決定係数R2を用いて回帰モデルの性能を評価します。
from sklearn.metrics import r2_score # 決定係数
from sklearn.metrics import mean_squared_error # RMSE
# 推論のために学習データ&テストデータを変換
X_quad_train = quadratic.fit_transform(X_train)
X_quad_test = quadratic.fit_transform(X_test)
# 平均平方二乗誤差(RMSE)
print('RMSE 学習: %.2f, テスト: %.2f' % (
mean_squared_error(y_train, model_reg.predict(X_quad_train), squared=False), # 学習
mean_squared_error(y_test, model_reg.predict(X_quad_test), squared=False) # テスト
))
# 決定係数(R^2)
print('R^2 学習: %.2f, テスト: %.2f' % (
r2_score(y_train, model_reg.predict(X_quad_train)), # 学習
r2_score(y_test, model_reg.predict(X_quad_test)) # テスト
))
# 出力結果
# RMSE 学習: 6.08, テスト: 6.39
# R^2 学習: 0.56, テスト: 0.51上記決定係数R2に着目すると、学習データを使ったR2は0.56、テストデータを使ったR2は0.51であり、目的変数をうまく捕捉できていないことが分かります。
ここで回帰モデルの評価指標について詳しく知りたい方はこちらの記事で解説しています。
【AI・機械学習】回帰モデルの性能評価および評価指標の解説|決定係数・RMSE・MAE・残差プロット
機械学習の性能評価方法の中で「回帰モデルはどうやって評価するの?」本記事ではその疑問に回答します。具体的に、決定係数、RMSE、MAE等の評価指標があり、それら特徴・利用シーンを1つずつ詳しく解説します。
【実践】多項式回帰モデル(次数=3)の作成・評価
続いて、次数=3の多項式回帰モデルを作成します。
モデルに適用する説明変数および目的変数は前回同様下記を用います。
| 説明変数 | LSTAT(低所得者の割合) |
| 目的変数 | MEDV(住宅価格の中央値) |
回帰モデルの学習
多項式回帰モデル作成のためのコードを下記に示します。
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.model_selection import train_test_split
""" モデル準備 """
X = df[['LSTAT']].values # 説明変数
y = df['MEDV'].values # 目的変数
# 学習・テストデータ分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 回帰モデルのインスタンス化
model_reg = LinearRegression()
""" 多項式が2次の項を追加 """
# 2次の多項式特徴量のクラスをインスタンス化
cubic = PolynomialFeatures(
degree=3, # 多項式の次数
interaction_only=False, # Trueの場合、ある特徴量を2乗以上した項が出力されない
include_bias=True, # Trueの場合、バイアス項を含める
order='C' # 出力する配列の計算順序
)
# データ演算・変換
X_cubic_train = cubic.fit_transform(X_train)
# 回帰モデルに上記データを適合
model_reg.fit(X_cubic_train, y_train)
""" データプロット """
# 多項式曲線を描くためのプロット
X_fit = np.arange(X_train.min(), X_train.max(), 1)[:, np.newaxis]
X_cubic_fit = cubic.fit_transform(X_fit)
y_cubic_predict = model_reg.predict(X_cubic_fit)
plt.plot(X_fit,
y_cubic_predict,
label='cubic (d=3)',
color='green',
lw=3,
linestyle='--'
)
# トレーニングデータのプロット
plt.scatter(X_train, y_train, label='トレーニングデータ', color='lightgray')
# グラフの書式設定
plt.xlabel('LSTAT(低所得者の割合)')
plt.ylabel('MEDV(住宅価格の中央値)')
plt.legend(loc='upper right')
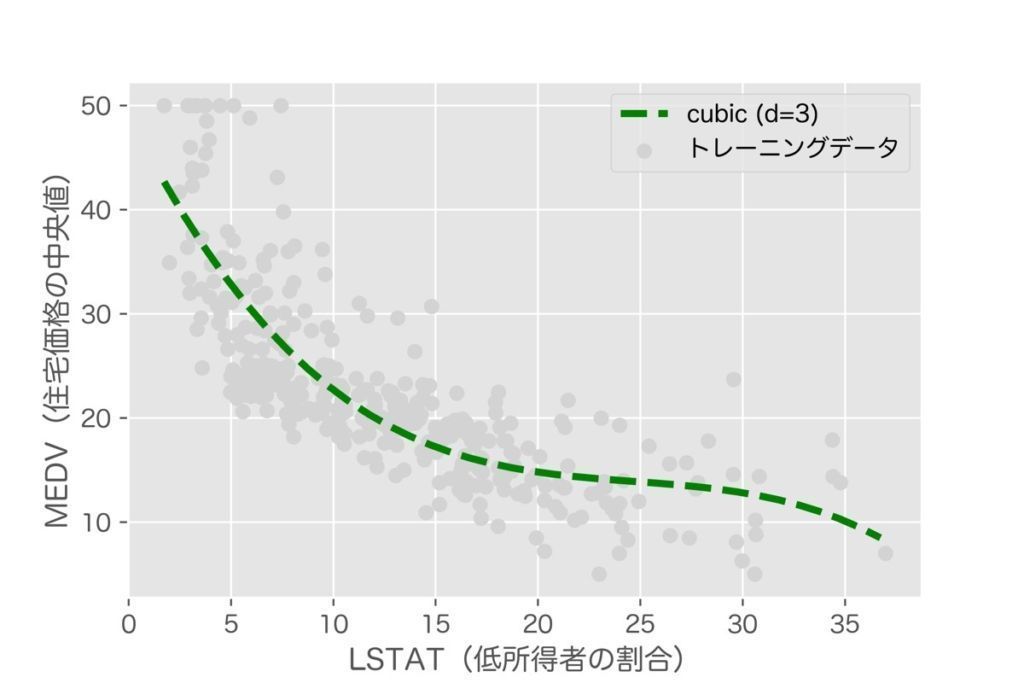
plt.show()今回3次の多項式回帰モデルを作成するため、PolynomialFeatures()メソッドの引数degree=3を渡しています。
【評価】RMSEおよび決定係数R2を用いた性能評価
RMSEと決定係数R2を用いて回帰モデルの性能評価を行います。
from sklearn.metrics import r2_score # 決定係数
from sklearn.metrics import mean_squared_error # RMSE
# 推論のために学習データ&テストデータを変換
X_cubic_train = cubic.fit_transform(X_train)
X_cubic_test = cubic.fit_transform(X_test)
# 平均平方二乗誤差(RMSE)
print('RMSE 学習: %.2f, テスト: %.2f' % (
mean_squared_error(y_train, model_reg.predict(X_cubic_train), squared=False), # 学習
mean_squared_error(y_test, model_reg.predict(X_cubic_test), squared=False) # テスト
))
# 決定係数(R^2)
print('R^2 学習: %.2f, テスト: %.2f' % (
r2_score(y_train, model_reg.predict(X_cubic_train)), # 学習
r2_score(y_test, model_reg.predict(X_cubic_test)) # テスト
))
# 出力結果
# RMSE 学習: 5.25, テスト: 5.66
# R^2 学習: 0.68, テスト: 0.61説明変数の数を増やしたことで、学習データを使った決定係数R2は0.56→0.68、テストデータを使ったR2は0.51→0.61に改善されました。
3次の多項式回帰は2次のそれと比較し、目的変数と説明変数の関係をうまく捕捉できているように見えます。
【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
