
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- 機械学習における分類問題の性能評価のために、Pythonで評価指標を出力する方法を解説!
- Scikit-learnを用いた正解率・適合率・再現率・F値の確認方法を一挙公開!
本記事で取り扱う機械学習分類モデルの評価指標
本記事では下記の評価指標を対象としたPythonプログラミング方法を解説していきます。
- 正解率 (Accuracy)
- 適合率 (Precision)
- 再現率 (感度, Recall, True Positive Rate, TPR)
- F値 (F-measure)
ここで、各評価指標の意味について知りたい方は下記の記事をご参照下さい。
【AI・機械学習】分類モデルの性能評価および評価指標の解説|正解率・適合率・再現率・F値・特異度・偽陽性率
機械学習における分類モデルの性能評価方法について解説します。本記事読了いただくことで、機械学習の集計データに基づきモデルを多様な角度から評価することができるようになります。
Pythonを用いた性能評価
正解率(Accuracy)
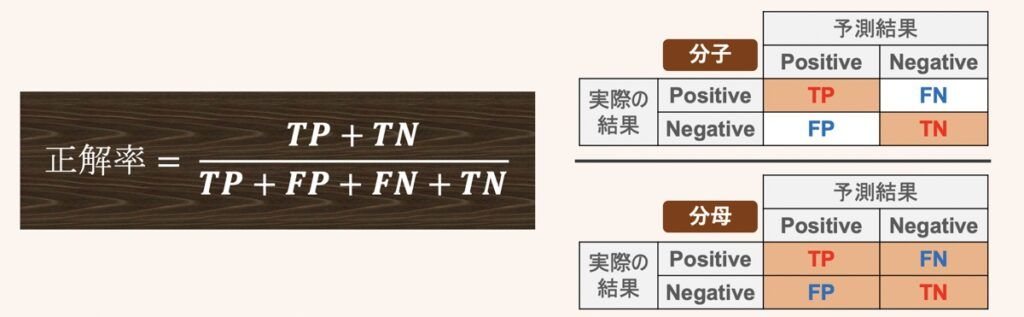
正解率を得るためのコーディング方法を下記に示します。
from sklearn.metrics import accuracy_score
y_test = [0, 0, 0, 1, 1, 1, 1, 1, 1, 1] #正解サンプル
y_pred = [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] #予測サンプル
""" 正解率 """
print(accuracy_score(y_test, y_pred))
# 出力結果
# 0.6sklearnのaccuracy_scoreメソッドを呼び出して正解率を算出しています。第一引数、第二引数は下記のように設定しています。
""" 正解率 """
accuracy_score(テストデータの正解ラベル, 推論したいデータのクラスラベル)適合率(Precision)
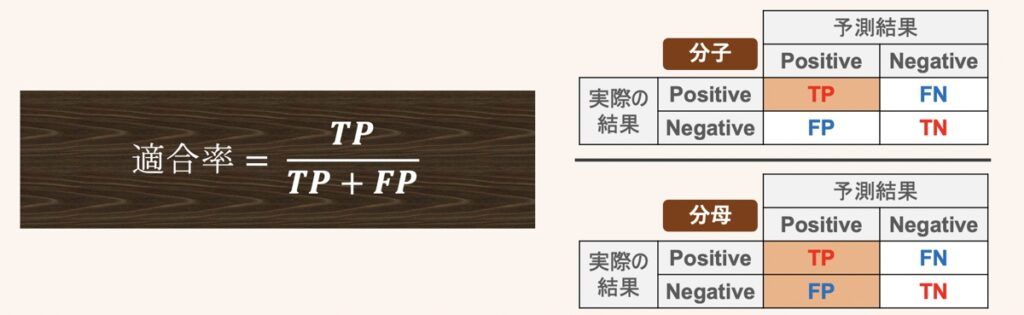
適合率を得るためのコーディング方法を下記に示します。
from sklearn.metrics import precision_score
y_test = [0, 0, 0, 1, 1, 1, 1, 1, 1, 1] #正解サンプル
y_pred = [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] #予測サンプル
""" 適合率 """
print(precision_score(y_test, y_pred, average="binary"))
# 出力結果
# 0.8引数:average(平均値の算出)について
分類問題のタスクは、最も単純な二値分類だけでなく多クラス分類として取り扱われる場合があります。今回は2値分類のタスクを想定し、average=”binary”と設定しています。なお、何も設定しなければデフォルトでbinaryになります。
再現率(感度, Recall, True Positive Rate, TPR)
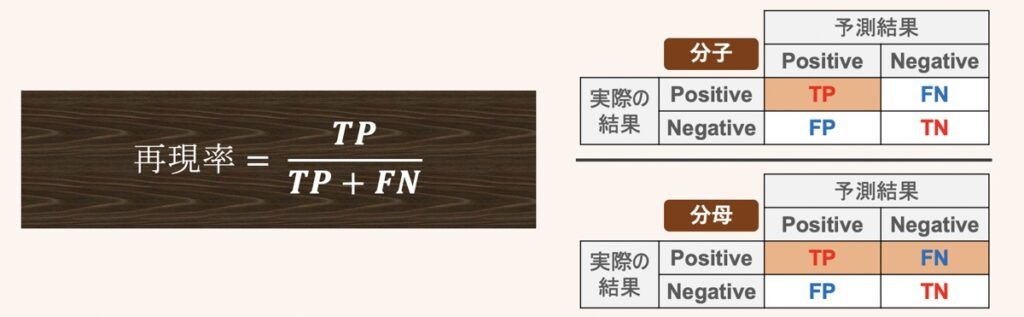
再現率を得るためのコーディング方法を下記に示します。
from sklearn.metrics import recall_score
y_test = [0, 0, 0, 1, 1, 1, 1, 1, 1, 1] #正解サンプル
y_pred = [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] #予測サンプル
""" 再現率 """
print(recall_score(y_test, y_pred, average="binary"))
# 出力結果
# 0.57F値 (F-measure)

F値を得るためのコーディング方法を下記に示します。
from sklearn.metrics import f1_score
y_test = [0, 0, 0, 1, 1, 1, 1, 1, 1, 1] #正解サンプル
y_pred = [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] #予測サンプル
""" F値 """
print(f1_score(y_test, y_pred, average='binary'))
# 出力結果
# 0.67分類レポート(Accuracy,Precision,Recall,f1-score)
最後にこれまで取り扱った正解率・適合率・再現率・F値をまとめて分類レポート(Classification Report)として出力したい際のコーディング方法について解説します。
from sklearn.metrics import classification_report
y_test = [0, 0, 0, 1, 1, 1, 1, 1, 1, 1] #正解サンプル
y_pred = [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] #予測サンプル
""" 分類問題の性能評価レポート """
print(classification_report(y_test, y_pred))# 出力結果
# 1 precision recall f1-score support
# 2
# 3 0 0.40 0.67 0.50 3
# 4 1 0.80 0.57 0.67 7
# 5
# 6 accuracy 0.60 10
# 7 macro avg 0.60 0.62 0.58 10
# 8 weighted avg 0.68 0.60 0.62 10Classification Reportの1行目のカラムは左から出力要素、適合率(Precision)、再現率(Recall)、F値(F1-Score)、出力要素のラベル数(Support)になります。今回出力要素は0と1と表示されているため、2値分類と判断できます。
6行目は正解率(accuracy)とクラスラベル数の合計が出力されます。7行目は各カラムに対するマクロ平均(各クラスラベルの単純な平均)、8行目はデータ件数等の重みを考慮した平均が算出されます。
【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
