
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- AI・機械学習理論および実装方法の習得に興味あり。
- 決定木とは何か知りたい。
- 決定木の概要・種類(分類木・回帰木)・Pythonでの実装方法が知りたい。
【AI・機械学習】決定木(ディシジョンツリー)とは?

決定木とは「YES or NO」や「100以上 or 100未満」のように、2つの分岐する回答が得られる条件によって予測を行う方法を指します。決定木アルゴリズムは、人間の思考プロセスに近い方法であるため、結果が分かりやすく、説明性が高いという点が特徴的です。
上図を見てみましょう。決定木は、一番上のデータグループから成る根(Root)ノードをはじめ、枝分かれ部分を指す枝(Branch)ノード、最終的な決定木の分類を指す葉(Leaves)ノードで構成されます。また、あるノードに対して分岐前のノードを親ノード、分岐後のノードを子ノードと呼びます。さらに、決定木の枝となる分岐ラインをエッジと呼びます。
決定木の種類(分類木・回帰木)
決定木にはクラス分類問題を取り扱う分類木と連続的な数値予測問題を取り扱う回帰木があります。
分類木
「英語が話せる/話せない」「対象が大人か/子供か」という説明変数をもとに、「留学経験がある人/ない人」を分類するモデルを考えてみましょう。
上図で示すように、「留学経験あり/なし」というカテゴリー変数または順序変数、フラグを示すような目的変数をツリー状に分類して表したものを分類木と言います。

分類木の出力結果をグラフで示した場合、軸に垂直な直線で”カクっとした形”として描画されるのが特徴的です。
例えば、気温と湿度を説明変数に設定し、過ごしやすい/過ごしずらいを分類する決定木を考えてみましょう。気温が20度~25度、湿度が40%~60%のときに過ごしやすいと感じ、それ以外の温度・湿度条件の場合は過ごしにくいと感じたとします。この場合、分類木が出力する最終的なグラフ結果は上図のように描けるでしょう。
回帰木
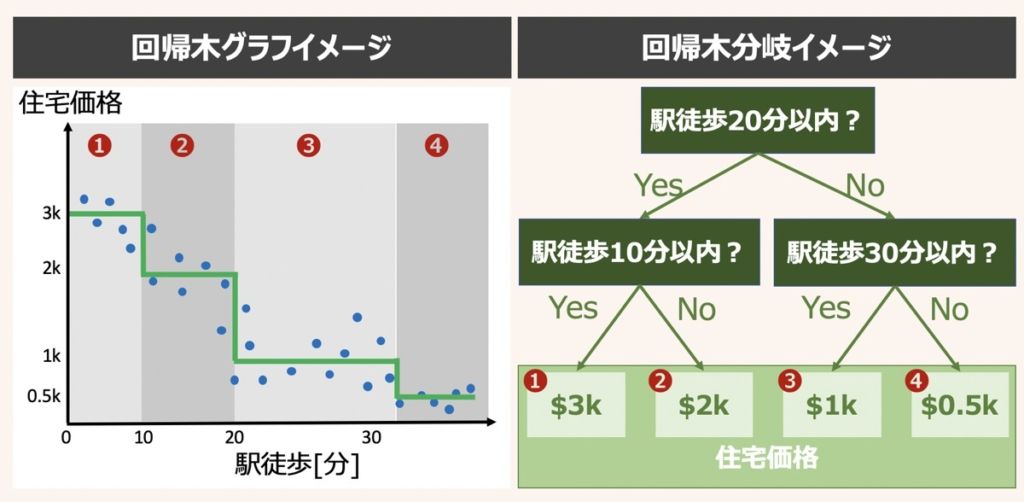
「住宅価格がいくらか予測する」といった連続して値が変動する数値変数を用いる場合、回帰木が有効です。
例えば上図に示すように、「住宅価格」は、「駅からの距離」で変動すると仮説立てたします。
「駅徒歩20分以内?」→YES→「駅徒歩10分以内?」→YES→「住宅価格=3,000$と予測」という分岐ができます。
このように回帰木の原理は分類木と同じですが、回帰木の場合は目的が「予測」であり、ツリーの分岐・葉を表現する手段として連続値を用います。
決定木の分岐イメージ
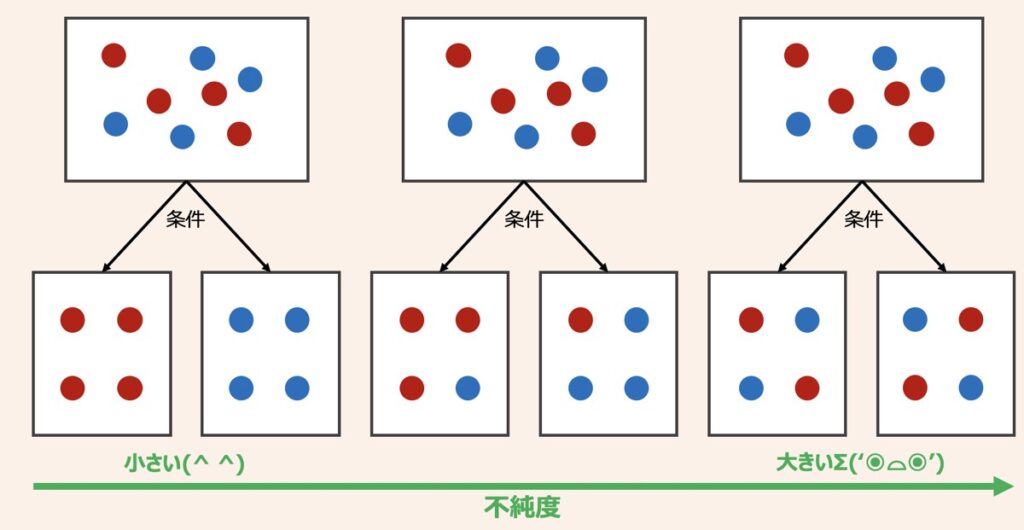
決定木を機械学習アルゴリズムとして採用した場合、具体的にどのように枝が分岐していくのでしょうか?
決定木の学習では、「不純度」というデータ分割のきれいさを示すに指標に基づき、不純度が小さくなるように枝を分岐を繰り返していきます。不純度の指標には、情報エントロピーやジニ不純度が代表的です。どちらの指標も値が大きいほど不純物が混在していることを示し、小さいほど綺麗に整頓されていることを示します。
情報エントロピー
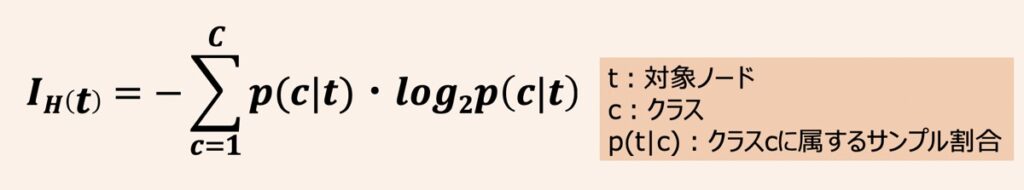
エントロピーは一般的に乱雑さを測定するための指標として用いられます。ノードtに含まれるクラスCに属するサンプル割合をp(t|c)と置いた場合、ノードtにおけるエントロピーは上記のように示されます。
ジニ不純度
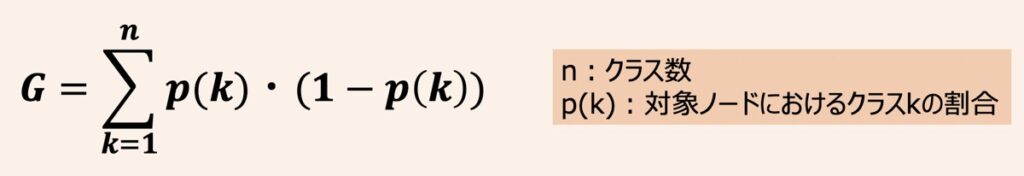
ジニ不純度は上式で定義されます。
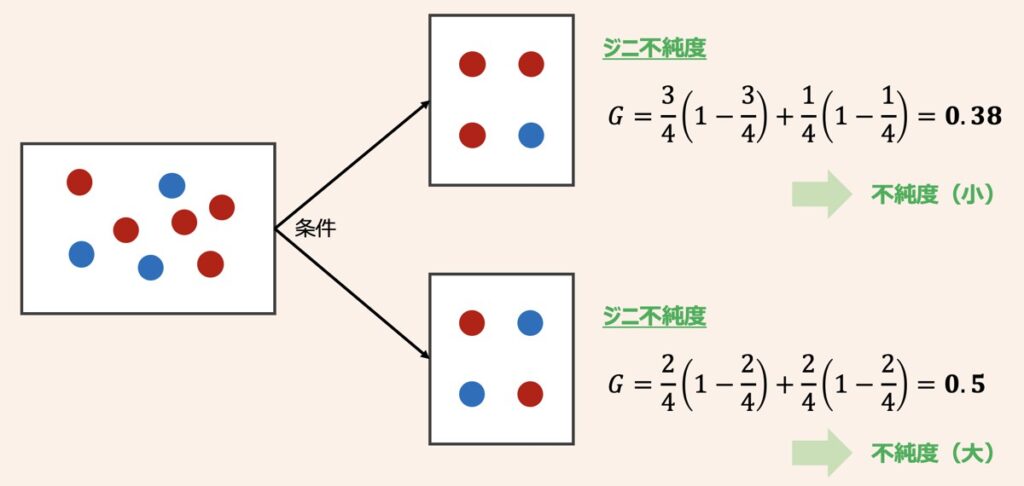
例えば、青と赤の2つのクラスからなるデータを分割した場合、それぞれでのジニ不純度は上記になります。
決定木の過学習対策
決定木の分岐を増やしていくと、葉ノードに含まれる不純物は減少するため、トレーニングデータの分類精度も高まります。一方で、分岐を増やし複雑化しすぎると、過学習という別の問題が浮上する点に注意が必要です。
多くの特徴量を用いて決定木を分割する場合は分割数が多くなるため、決定木が複雑化し、過学習になる傾向も高まります。そのため、過学習防止を目的に「分割できる枝の深さを制限を設ける」「分割に必要なデータ数の下限値を定義する」等が必要となります。
剪定・枝切り
剪定・枝切りは、決定木の過学習防止を目的とした方法であり、トレーニングデータを活用して決定木を意図的に過学習させた後、テストデータを用いて汎化性能の悪い決定木の分岐を切り落とすという方法を指します。剪定・枝切りの代表的な手法としてREPやコスト複雑度枝切り等があります。
REP(Reduce Error Pruning)
REPとは、精度が悪化しなければ、ノードを最も割合の高いクラスの葉ノードに置き換える方法を指します。
コスト複雑度枝切り(Cost-Complexity Pruning)
コスト複雑度枝切りとは、過学習防止のために部分木の葉ノードの数が大きくならないよう抑制しつつ、葉ノードに含まれる不純物を減らしていく方法を指します。
決定木のメリット・デメリット
機械学習アルゴリズムに決定木を採用した場合のメリットおよびデメリットについて言及します。
決定木のメリット
- 人間の思考プロセスに近い方法であるため、結果が分かりやすく、説明性が高い。
- 条件分岐の様子を可視化できるため、結果の解釈が用意。
- 決定木では数値データとカテゴリデータ双方を特徴量として取り扱いできるため、他の機械学習アルゴリズムと比較してデータ前処理が少ないて済む。
- 特徴量の分割はスケールに依存しない。特徴量のスケーリング処理(標準化・正規化)は不要。
決定木のデメリット
- 過学習対策を要考慮。特徴量の数が多くなると、条件分岐が複雑化し、過学習に陥る可能性が高くなる。
- 決定境界を斜めに引くとうまく分類できるケースの場合、予測性能が悪くなる。特徴量の主成分分析を行うことである程度の性能低下を軽減できる可能性あり。
- データにおけるクラスの割合を均衡にしておく必要がある。
- データが少し変わると全く異なる決定木が出力される。
【Python】決定木を用いた機械学習モデルの構築
決定木を採用した機械学習モデルをPythonで実装するに際して、種類・アルゴリズム別実装方法を言及します。
- 分類木
- 回帰木
- ランダムフォレスト(分類)
- ランダムフォレスト回帰
- XGBoost
分類木
分類木は、特徴量データが与えられたら、出力結果として「YES or NO」のような2択分類や「グループA or グループB or グループC」のようなカテゴリ分類をするために活用します。Pythonでの具体的な実装方法はこちらをご覧ください。
【Python】決定木(分類木)の構築方法|scikit-learnによる機械学習モデル作成入門
決定木の分類モデルをPythonで構築する方法について解説します。データの準備・モデル学習・ツリー構造可視化・性能評価に至るまで体系的に言及。
回帰木
ある数値(連続値)の推定ルールをツリーで表現した決定木を回帰木と呼びます。Pythonでの具体的な実装方法はこちらをご覧ください。
【Python】回帰木モデルの作成と評価方法|scikit-learn・機械学習による決定木を用いた回帰分析入門
「Pythonによる回帰木のモデル作成と評価方法を知りたい方向け」の記事になります。
ランダムフォレスト
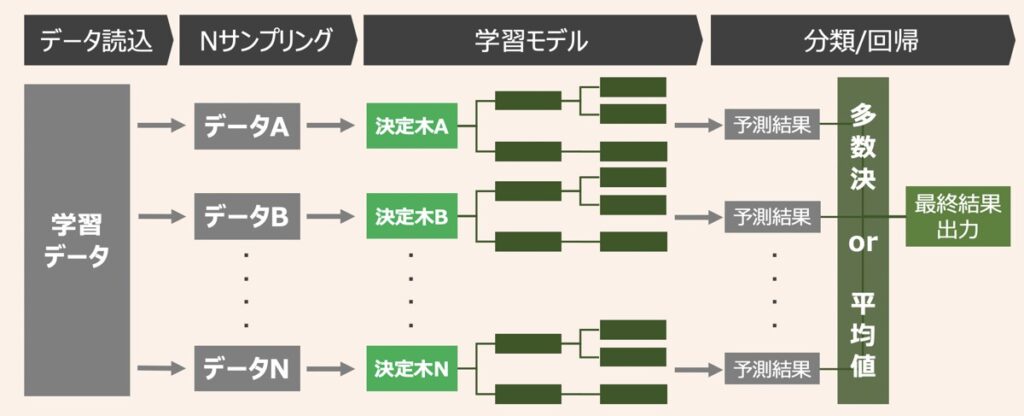
ランダムフォレストとは、決定木による複数識別器を統合させたバギングベースのアンサンブル学習アルゴリズムです。Pythonでランダムフォレストの分類モデルの実装方法が知りたい方はこちらの記事をご覧ください。
【機械学習×Python】グリッドサーチによるハイパーパラメータ最適化方法を実演・ランダムフォレストによるモデル構築
本記事はPython機械学習プログラミングの解説記事です。「グリッドサーチをもとにハイパーパラメータの最適化ができるようになりたい」「ランダムフォレストでのモデル構築方法を知りたい」という方向けの内容となっています。
ランダムフォレスト(回帰)
Pythonでランダムフォレストの回帰モデルの実装方法が知りたい方はこちらの記事をご覧ください。
【Python】ランダムフォレスト回帰のモデル作成と評価方法|scikit-learn・機械学習による回帰分析入門
「Pythonによるランダムフォレスト回帰のモデル作成と評価方法を知りたい方向け」の記事になります。
XGBoost
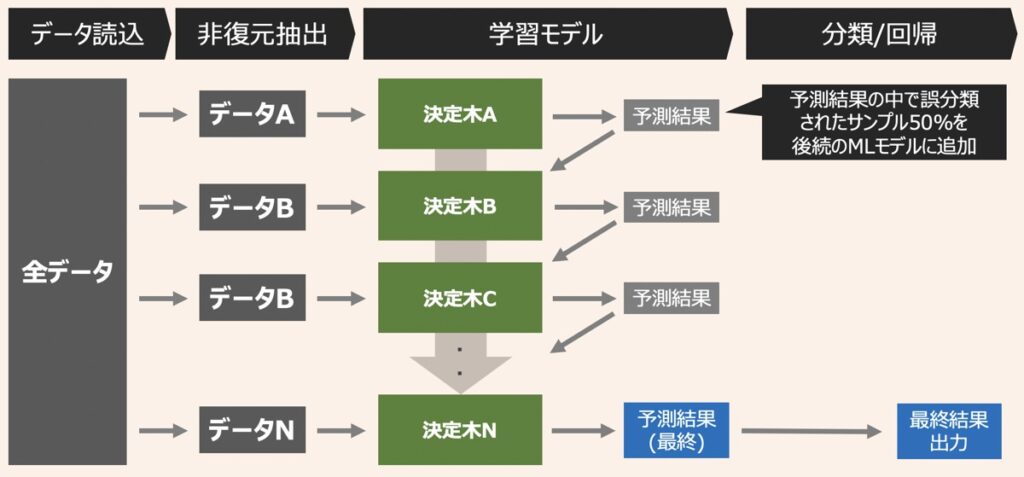
XGBoostとは、アンサンブル学習を代表するアルゴリズムの一つであり、ブースティングと決定木を組み合わせで構成されています。
【機械学習】XGBoostとは?|Pythonで分類モデルを実装する方法解説
アンサンブル学習の代表的アルゴリズムである「XGBoost」について詳しく知りたい方向けに、「XGBoostの概要」および「Pythonでの実装方法」を解説します。
【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
