
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- 回帰木を用いて機械学習モデルを構築する方法を知りたい
- 決定木における「分類木」と「回帰木」の違いを知りたい
決定木|分類木と回帰木の違い
決定木とは
決定木(Decision Tree)とは、分類や予測を目的に用いられる機械学習アルゴリズムの1つであり、手段としてツリー(樹形図)を用いるのが特徴です。
決定木には「分類木」と「回帰木」があります。
ある事象の分類が目的の場合は「分類木」を用い、数値の予測が目的の場合は「回帰木」を用います。
以下分類木と回帰木についてもう少し詳しく見ていきましょう!
分類木とは
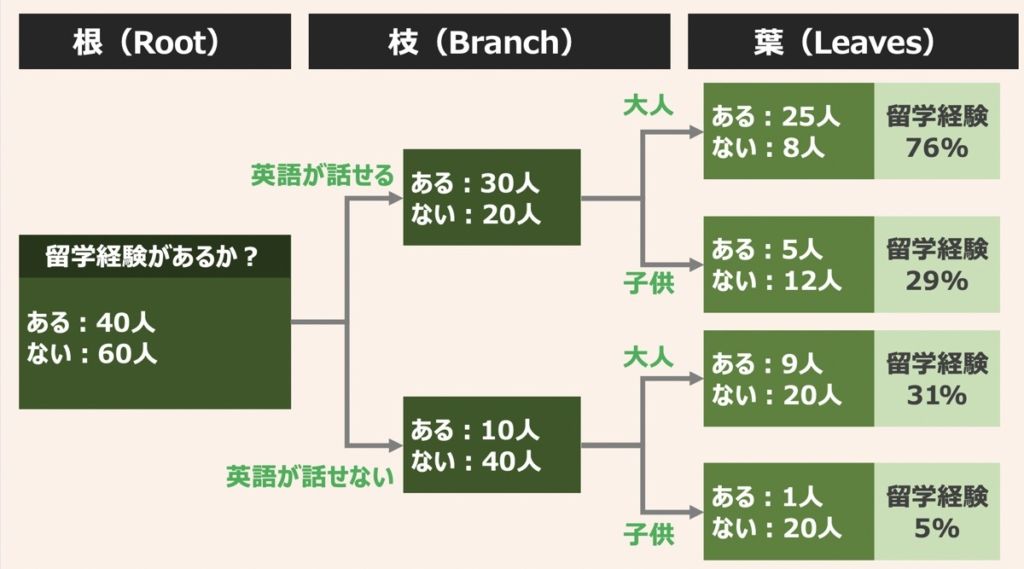
上図を例に分類木を解説します。
「英語が話せる/話せない」「対象が大人か/子供か」という説明変数をもとに、「留学経験がある人/ない人」を分類するモデルを考えてみましょう。
上図で示すように、「留学経験あり/なし」というカテゴリー変数または順序変数、フラグを示すような目的変数をツリー状に分類して表したものを分類木と言います。
さらに、「留学経験あり/なし」というツリーの始まりを根(Root)と呼び、途中の分岐を枝(Branch)またはノード(Node)と呼び、最終的な分岐の結果を葉(Leaves)と呼びます。
回帰木とは
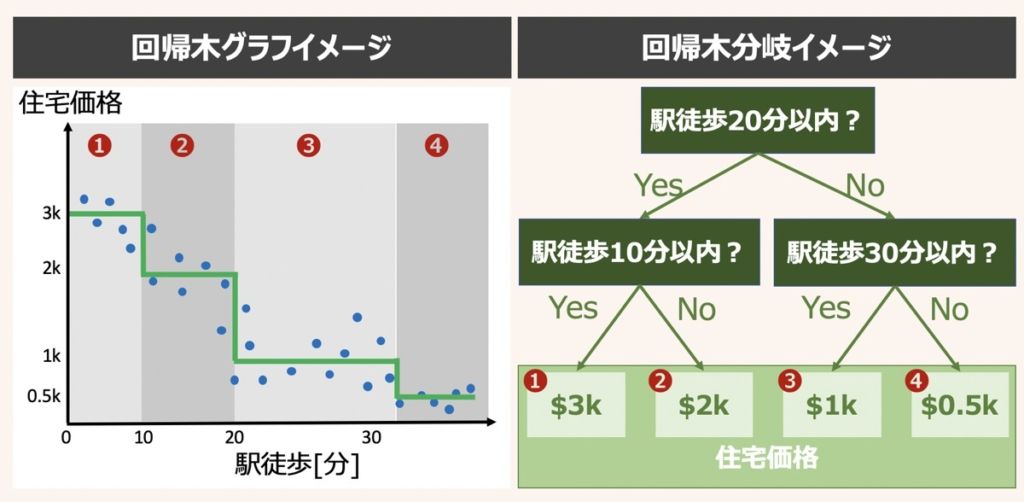
「住宅価格がいくらか予測する」といった連続して値が変動する数値変数を用いる場合、回帰木が有効です。
例えば上図に示すように、「住宅価格」は、「駅からの距離」で変動すると仮説立てたします。
「駅徒歩20分以内?」→YES→「駅徒歩10分以内?」→YES→「住宅価格=3,000$と予測」という分岐ができます。
このように回帰木の原理は分類木と同じですが、回帰木の場合は目的が「予測」であり、ツリーの分岐・葉を表現する手段として連続値を用います。
本記事ではPythonを用いて回帰木のモデル作成・評価の方法について解説します。
【事前準備】決定木回帰モデル作成に必要なデータ
実際にPythonのScikit-learnライブラリを用いて回帰木モデルを構築していきましょう!下記の手順でプログラムを構築していきます。
- データセットの説明
- データの準備
- 回帰モデル学習
- モデル性能評価
今回は機械学習モデル過程で必須となるデータクレンジングやグラフ可視化等の前処理プロセスは割愛しています。その代わり、モデル作成と評価方法を詳しく解説しております。
データクレンジングやグラフ可視化を通じて回帰モデル作成について言及した記事も配信しています。合わせてご覧下さい。
【機械学習・Python】線形単回帰・重回帰分析に基づき予測モデルを作成|scikit-learnでモデル開発・評価
Pythonとscikit-learnを用いて単回帰および重回帰モデルを作成・評価する方法について解説します。
データセットの説明

データセットには、Boston Housingというデータセットを活用します。
1970年代後半におけるボストンの住宅情報とその地域における環境をまとめたデータセットであり、住宅価格の予測を目的とした回帰モデル作成のチュートリアルによく利用されます。
Boston Housingデータセットの説明変数および目的変数の概要はそれぞれ以下になります。
説明変数一覧
| 特徴量名 | 概要 |
|---|---|
| CRIM | (地域人工毎の)犯罪発生率 |
| ZN | 25,000平方フィート以上の住宅区画の割合 |
| INDUS | (地域人工毎の)非小売業の土地面積の割合 |
| CHAS | チャールズ川沿いに立地しているかどうか(該当の場合は1、そうでない場合は0) |
| NOX | 窒素酸化物の濃度(単位:pphm) |
| RM | 平均部屋数/一戸 |
| AGE | 1940年よりも古い家の割合 |
| DIS | 5つのボストン雇用センターまでの重み付き距離 |
| RAD | 主要な高速道路へのアクセス指数 |
| TAX | 10,000ドルあたりの所得税率 |
| PTRATIO | (地域人工毎の)学校教師1人あたりの生徒数 |
| B | (地域人工毎の)アフリカ系アメリカ人居住者の割合 |
| LSTAT | 低所得者の割合 |
目的変数一覧
| 特徴量名 | 概要 |
|---|---|
| MEDV | 住宅価格の中央値(単位 $1,000) |
データの準備
前述したBoston Housingのデータセットを準備するために以下のコードを実行しましょう。
# データ前処理
import numpy as np
import pandas as pd
# データ可視化
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("ggplot")
# %matplotlib inline
# グラフの日本語表記対応
from matplotlib import rcParams
rcParams["font.family"] = "sans-serif"
rcParams["font.sans-serif"] = "Hiragino Maru Gothic Pro"
# データセット読込
from sklearn.datasets import load_boston
boston = load_boston()
# DataFrame作成
df = pd.DataFrame(boston.data)
df.columns = boston.feature_names
df["MEDV"] = boston.target【実践】決定木(回帰木)モデルの作成・評価|単回帰の場合
回帰木モデル作成に際して、次のような変数を用いることとします。
まずは分かりやすいように、単回帰のモデルを作成します。
| 説明変数 | LSTAT(低所得者の割合) |
| 目的変数 | MEDV(住宅価格の中央値) |
回帰木のモデル学習
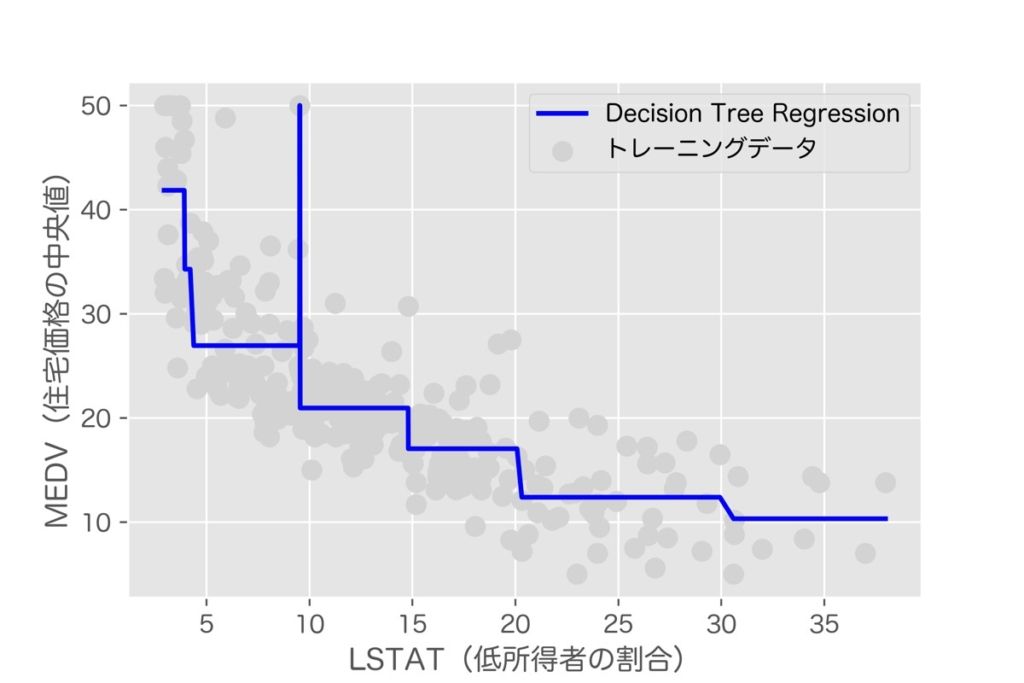
回帰木モデルを作成するコードを下記に示します。また、推論結果の可視化も合わせて行います。
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
""" モデル学習 """
# 変数定義
X = df[['LSTAT']].values # 説明変数
y = df['MEDV'].values # 目的変数(住宅価格の中央値)
# データ分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1)
# 決定木回帰
model_tree = DecisionTreeRegressor(criterion='mse',
splitter='best',
max_depth=3,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
ccp_alpha=0.0
)
model_tree.fit(X_train, y_train)
# 推論
y_train_pred = model_tree.predict(X_train)
y_test_pred = model_tree.predict(X_test)
""" グラフ可視化 """
# flatten:1次元の配列を返す、argsort:ソート後のインデックスを返す
sort_idx = X_train.flatten().argsort()
# 可視化用に加工
X_train_plot = X_train[sort_idx]
Y_train_plot = y_train[sort_idx]
train_predict = model_tree.predict(X_train_plot)
# 可視化
plt.scatter(X_train_plot, Y_train_plot, color='lightgray', s=70, label='トレーニングデータ')
plt.plot(X_train_plot, train_predict, color='blue', lw=2, label="Decision Tree Regression")
# グラフの書式設定
plt.xlabel('LSTAT(低所得者の割合)')
plt.ylabel('MEDV(住宅価格の中央値)')
plt.legend(loc='upper right')
plt.show()DecisionTreeRegressorメソッドの概要
回帰木は、scikit-learnのDecisionTreeRegressor()メソッドを用いて作成できます。
このメソッドで利用する引数情報を下記に示します。
model_tree = DecisionTreeRegressor(criterion='mse',
splitter='best',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
ccp_alpha=0.0
)| 引数名 | 概要 | デフォルト |
|---|---|---|
| criterion | 不純度を測定する基準(平均二乗誤差、平均絶対誤差など) | ‘squared_error’ |
| splitter | 条件探索アルゴリズムを選択するオプション(’best’と’rondom’が指定可能) | ‘best’ |
| max_depth | 決定木のノード深さの制限値。ツリーが深くなりすぎて過学習の状態に陥った際は、このパラメータが正則化の役割を果たす。 | None |
| min_samples_split | ノードを分割するために必要なサンプルの最小値 | 2 |
| min_samples_leaf | 1ノードの深さを作成するために必要となるデータ数の最小値。指定した値以上のデータ数を持たないノードは作られない。 | 1 |
| min_weight_fraction_leaf | サンプルの重みを考慮した上でのmin_samples_leafに該当 | 0.0 |
| max_features | ランダムに指定する説明変数の数 (全ての説明変数がモデル学習に活用されるわけではなく、ランダムに割り振られる) | None |
| random_state | 乱数シード | None |
| max_leaf_nodes | 作成される決定木の葉の数を、指定した値以下に制御する | None |
| min_impurity_decrease | 決定木の成長の早期停止するための閾値。不純度が指定の値より減少した場合、ノードを分岐し、不純度が指定の値より減少しなければ分岐を抑制。 | 0.0 |
| ccp_alpha | ccp_alphaが大きいほどプルーニングされるノードの数が増加。プルーニングとは、精度低下をできるだけ抑えながら過剰な重みを排除するプロセスを指す。 | 0.0 |
回帰木の分岐ロジックを確認
前述で作成した回帰木のモデルがどのように分岐しているか可視化してみましょう。
ツリーはdtreeviz.trees.dtreeviz()関数を用いることで可視化できます。下記のコードを実行してみましょう。
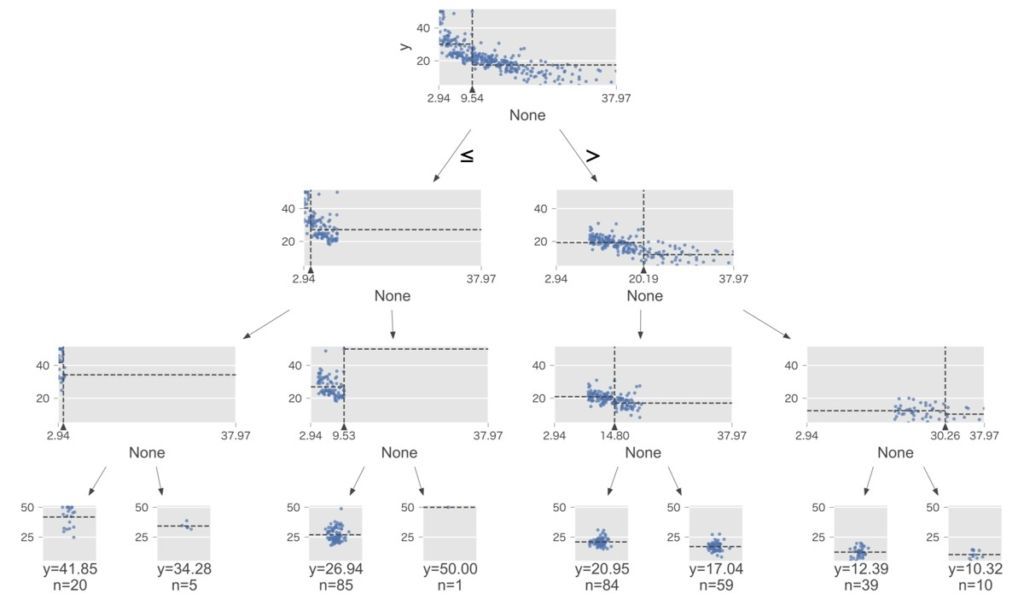
from dtreeviz.trees import dtreeviz
from IPython.display import SVG
# 回帰木の分岐の仕方を可視化
viz = dtreeviz(model_tree, X_train, y_train, target_name="y")
# svg形式で保存
viz.save("regression_decisiontree.svg")
# 分岐可視化
SVG(filename="regression_tree.svg")上記実行時によく報告されるエラーとして次のようなものがあります。
ExecutableNotFound: failed to execute ‘dot’, make sure the Graphviz executables are on your systems’ PATH
このようなエラーに遭遇した場合、dtreeviz : Decision Tree Visualizationのドキュメントにあるインストール手順に従うと、エラーが回避できるでしょう。
【評価】RMSEおよび決定係数R2を用いた性能評価
RMSE(平均平方二乗誤差)と決定係数R2を用いて回帰モデルの性能を評価します。
from sklearn.metrics import r2_score # 決定係数
from sklearn.metrics import mean_squared_error # RMSE
# 予測値(Train)
y_train_pred = model_tree.predict(X_train)
# 予測値(Test)
y_test_pred = model_tree.predict(X_test)
# 平均平方二乗誤差(RMSE)
print('RMSE 学習: %.2f, テスト: %.2f' % (
mean_squared_error(y_train, y_train_pred, squared=False), # 学習
mean_squared_error(y_test, y_test_pred, squared=False) # テスト
))
# 決定係数(R^2)
print('R^2 学習: %.2f, テスト: %.2f' % (
r2_score(y_train, y_train_pred), # 学習
r2_score(y_test, y_test_pred) # テスト
))
# 出力結果
# RMSE 学習: 3.86, テスト: 6.56
# R^2 学習: 0.81, テスト: 0.52上記決定係数R2に着目すると、学習データを使ったR2は0.81と関係が捕捉できているにも関わらず、テストデータを使ったR2は0.52と低くなっています。
上記の結果から分かることから、回帰木のモデルが過学習の状態にあると言えます。
回帰モデルの評価指標について詳しく知りたい方はこちらの記事で解説しています。
【AI・機械学習】回帰モデルの性能評価および評価指標の解説|決定係数・RMSE・MAE・残差プロット
機械学習の性能評価方法の中で「回帰モデルはどうやって評価するの?」本記事ではその疑問に回答します。具体的に、決定係数、RMSE、MAE等の評価指標があり、それら特徴・利用シーンを1つずつ詳しく解説します。
【実践】決定木(回帰木)モデルの作成・評価|重回帰の場合
続いて、複数の説明変数を回帰木に適用してモデルを作成し、単回帰の場合と性能比較してみましょう。
| 説明変数 | 目的変数以外の変数全て |
| 目的変数 | MEDV |
回帰木のモデル学習
回帰木モデルを作成するコードを下記に示します。
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
""" モデル学習 """
# 変数定義
X = df.iloc[:, :-1].values # 説明変数(目的変数以外)
y = df['MEDV'].values # 目的変数(住宅価格の中央値)
# データ分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1)
# 決定木回帰
model_tree = DecisionTreeRegressor(criterion='mse',
splitter='best',
max_depth=3,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
ccp_alpha=0.0
)
model_tree.fit(X_train, y_train)【評価】RMSEおよび決定係数R2を用いた性能評価
RMSE(平均平方二乗誤差)と決定係数R2を用いて回帰モデルの性能を評価します。
from sklearn.metrics import r2_score # 決定係数
from sklearn.metrics import mean_squared_error # RMSE
# 予測値(Train)
y_train_pred = model_tree.predict(X_train)
# 予測値(Test)
y_test_pred = model_tree.predict(X_test)
# 平均平方二乗誤差(RMSE)
print('RMSE 学習: %.2f, テスト: %.2f' % (
mean_squared_error(y_train, y_train_pred, squared=False), # 学習
mean_squared_error(y_test, y_test_pred, squared=False) # テスト
))
# 決定係数(R^2)
print('R^2 学習: %.2f, テスト: %.2f' % (
r2_score(y_train, y_train_pred), # 学習
r2_score(y_test, y_test_pred) # テスト
))
# 出力結果
# RMSE 学習: 2.34, テスト: 4.25
# R^2 学習: 0.93, テスト: 0.80上記決定係数R2に着目すると、学習データを使ったR2は0.81→0.93、テストデータを使ったR2は0.52→0.80であり、単回帰の場合と比較して大きく精度が改善されました。
決定木のモデルは過学習に陥りやすい特徴がありますが、テストデータを用いた決定係数が1に近いことから、汎化性能も良いと言えます。
【評価】残差プロットによる可視化
最後に回帰木の残差プロットの表現方法について解説します。次のようなコードを入力しましょう。
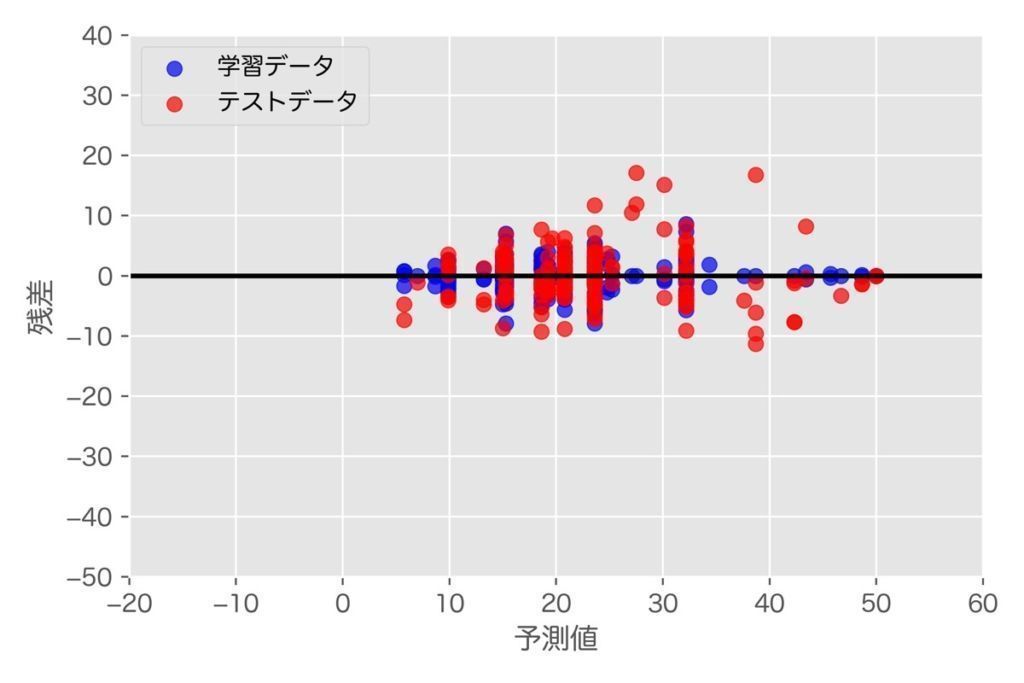
# 予測値と残差をプロット(学習データ)
plt.scatter(y_train_pred, # グラフのx値(予測値)
y_train_pred - y_train, # グラフのy値(予測値と学習値の差)
c='blue', # プロットの色
marker='o', # マーカーの種類
s=40, # マーカーサイズ
alpha=0.7, # 透明度
label='学習データ') # ラベルの文字
# 予測値と残差をプロット(テストデータ)
plt.scatter(y_test_pred,
y_test_pred - y_test,
c='red',
marker='o',
s=40,
alpha=0.7,
label='テストデータ')
# グラフの書式設定
plt.xlabel('予測値')
plt.ylabel('残差')
plt.legend(loc='upper left')
plt.hlines(y=0, xmin=-20, xmax=60, lw=2, color='black')
plt.xlim([-20, 60])
plt.ylim([-50, 40])
plt.tight_layout()
plt.show()【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
