
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- Pythonによるグリッドサーチのハイパーパラメータの最適化手法が知りたい!
- ランダムフォレストでのモデル構築方法を知りたい!
【機械学習】ハイパーパラメータとは
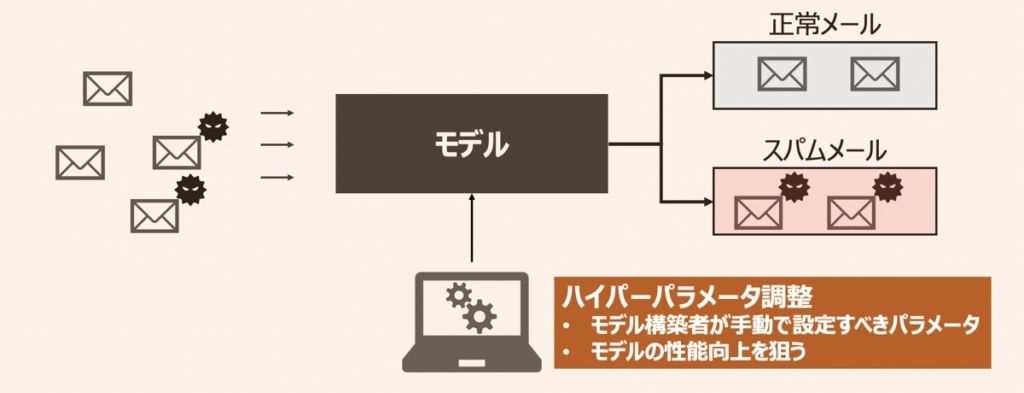
機械学習モデルを活用したアプリケーションには、設計者・モデル構築者が設定しなければならないパラメータが多数あります。それらパラメータを「ハイパーパラメータ」と呼びます。ハイパーパラメータについて詳しく内容を知りたい方は、まずこちらの記事をご覧ください。
【AI・機械学習】ハイパーパラメータとは・モデルチューニングの最適化手法(グリッドサーチ・ベイズ最適化等)を徹底解説
機械学習における「ハイパーパラメータの概要・最適化手法」の解説記事です。本記事読了後は、ハイパーパラメータとは何か理解できるとともに、要所に応じた最適なチューニング方法(グリッドサーチ・ランダムサーチ・ベイズ最適化等)を把握できるようになるでしょう。
グリッドサーチとは|ハイパーパラメータ探索メソッド
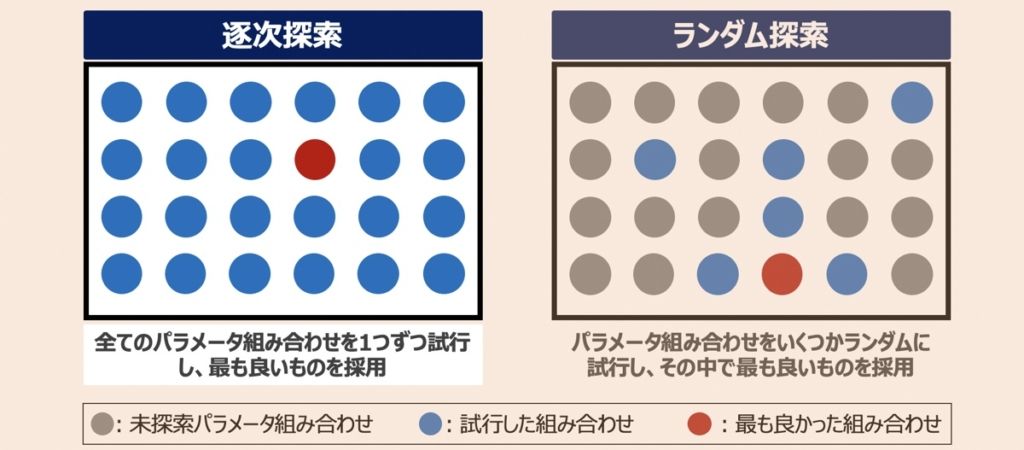
グリッドサーチとは、探索対象のパラメータ候補を列挙し、その全ての組み合わせを照らし合わせ、最適な組み合わせを見つけ出す探索手法です。本記事ではグリッドサーチというハイパーパラメータ探索手法を利用し、Pythonプログラムを構築していきます。
ランダムフォレスト(Random Forest)とは
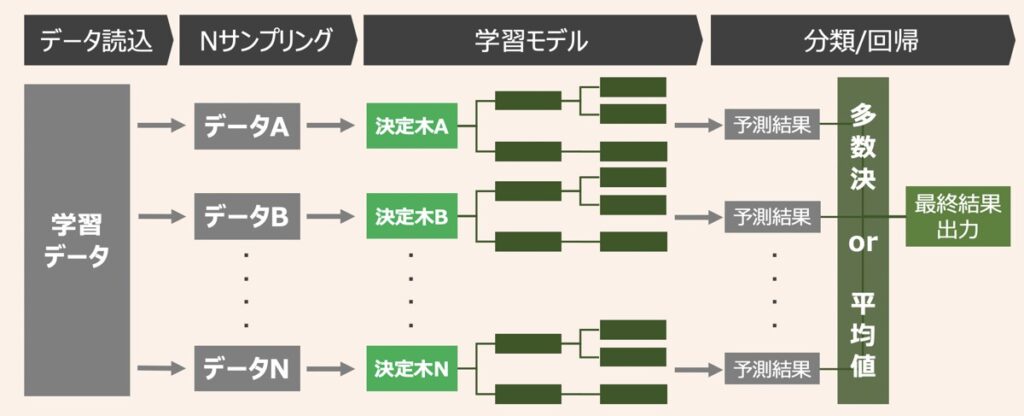
ランダムフォレストとは、決定木による複数識別器を統合させたバギングベースのアンサンブル学習アルゴリズムです。分類(判別)・回帰(予測)両方の用途で利用可能な点も特徴的です。
ランダムフォレストは、決定木モデルを単体で利用した場合に発現しやすい過学習問題に対応した方法の1つとして位置付けられます。復元抽出したデータで過学習した決定木を複数用意し、各決定木から得られた結果を多数決または平均値を取ることで最終結果を得ます。このような仕組みを利用することで過学習の度合いを減らそうという思想です。
今回Pythonで構築するモデルは、このランダムフォレストを採用します。
Pythonでハイパーパラメータを最適化したランダムフォレストモデルを構築
それでは実際にPythonコードを触りながらハイパーパラメーターチューニングとモデル構築を実施していきましょう!下記の手順で進めていきます。
- データセットの説明
- データの準備
- モデル学習・グリッドサーチによるハイパーパラメータチューニング
- 性能評価
データセットの説明

データセットには、機械学習のサンプルデータとして有名なIris(アヤメ)データセットを活用します。3種類のアヤメ(Iris Setosa, Iris Versicolor, Iris Virginica)があり、それぞれ50サンプルずつ(合計150サンプル)用意されているデータです。このアヤメの名前を目的変数として利用します。また、説明変数にはアヤメの計測値である萼片(sepals)と花びら(petals)の長さと幅の4つを利用します。
データの準備
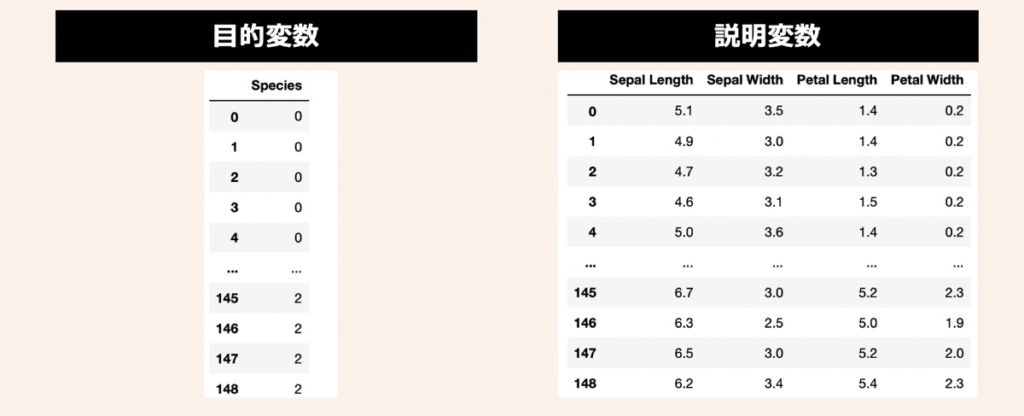
まず、前述したアヤメのデータセットを準備します。上記目的変数と説明変数をPandas形式で取り扱うために、下記のコードを実行してみましょう。
"""
①データセットの準備(Sckit-learnで提供されているアヤメのデータを利用)
"""
import numpy as np
import pandas as pd
from sklearn import datasets
# データロード
iris = datasets.load_iris()
# 説明変数
X = iris.data
X = pd.DataFrame(X, columns=["Sepal Length", "Sepal Width", "Petal Length", "Petal Width"])
# 目的変数
Y = iris.target
Y = iris_target = pd.DataFrame(Y, columns = ["Species"])後述では変数(X)を説明変数の集合体、変数(Y)を目的変数として利用していきます。今回データ加工やクレンジング、特徴量エンジニアリング等の前処理工程は割愛します。
【モデル学習】グリッドサーチによるハイパーパラメータチューニング
モデル学習工程ではまず、ランダムフォレストのモデルを構築し、グリッドサーチによるハイパーパラメータ探索を実行します。続いて、得られた最適なパラメータ組み合わせを利用し、モデルの再構築を行います。下記のコードを順次実行してみましょう。
ハイパーパラメータ探索
"""
②モデル学習
・ランダムフォレストを識別子として利用
・ハイパーパラメータのチューニング手法にはグリッドサーチを採用
"""
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
# 学習データ&テストデータ分割
X_train, X_test, Y_train, Y_test = train_test_split(X.values,Y.values,test_size=0.3, random_state=3)
# グリッドサーチによるハイパーパラメータ探索候補設定
# 今回はRandomForestClassifierのパラメータが対象(値は任意に設定)
parameters = {
'n_estimators': [10, 20, 30, 50, 100, 300], # 用意する決定木モデルの数
'max_features': ('sqrt', 'log2','auto', None), # ランダムに指定する特徴量の数
'max_depth': (10, 20, 30, 40, 50, None), # 決定木のノード深さの制限値
}
# モデルインスタンス
model = RandomForestClassifier()
# ハイパーパラメータチューニング(グリッドサーチのコンストラクタにモデルと辞書パラメータを指定)
gridsearch = GridSearchCV(estimator = model, # モデル
param_grid = parameters, # チューニングするハイパーパラメータ
scoring = "accuracy" # スコアリング
)
# 演算実行
gridsearch.fit(X_train, Y_train)
# グリッドサーチの結果から得られた最適なパラメータ候補を確認
print('Best params: {}'.format(gridsearch.best_params_))
print('Best Score: {}'.format(gridsearch.best_score_))グリッドサーチによるハイパーパラメータ探索ではGridSearchCV()というメソッドを活用します。下記のように記載することでメソッド実行が可能です。
gridsearch = GridSearchCV(estimator = モデルを指定, # 今回はRandomForestClassifierが対象
param_grid = モデルのパラメータ指定, # 今回はRandomForestのパラメータ(引数)が対象
scoring = 基準となる評価方法を指定, # (例) 'accuracy'(正解率),‘f1_micro’(F値)
)【モデル再学習】最適なハイパーパラメータでランダムフォレストモデル構築
グリッドサーチにより探索された最適なパラメータはbest_params_というメソッドで確認できます。
前述で得られた最適なパラメータ組み合わせ結果をもとにモデルを再構築します。以下を実行しましょう。
# 最適なハイパーパラメータの組み合わせを用いてモデル再構築
model = RandomForestClassifier(n_estimators = gridsearch.best_params_['n_estimators'], # 用意する決定木モデルの数
max_features = gridsearch.best_params_['max_features'], # ランダムに指定する特徴量の数
max_depth = gridsearch.best_params_['max_depth'], # 決定木のノード深さの制限値
criterion='gini', # 不純度評価指標の種類(ジニ係数)
min_samples_leaf = 1, # 1ノードの深さの最小値
random_state = 0, # 乱数シード
)
# モデル学習
model.fit(X_train,Y_train)【参考】ランダムフォレストで使用するパラメータ一覧
ランダムフォレストのモデル構築に際して、考慮すべきパラメータには下記があります。
| 引数名 | 重要度 | 概要 |
|---|---|---|
| n_estimators | ★ | 用意する決定木モデルの数 (N分割した学習データの数とも捉えられる) |
| max_features | ★ | ランダムに指定する特徴量の数 (全ての特徴量がモデル学習に活用されるわけではなく、ランダムに割り振られる) |
| max_depth | 決定木のノード深さの制限値 | |
| criterion | 不純度評価指標の種類 | |
| min_samples_leaf | 1ノードの深さの最小値 |
モデル性能評価
最後に今回構築したモデルの精度を見てみましょう!
正解率ベースで算出してみると、正解率約95%という結果が得られました。
from sklearn import metrics
# 評価
predicted = model.predict(X_test)
print(metrics.accuracy_score(predicted,Y_test))【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
