
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- Pythonを用いたポイ活チャレンジに興味あり!
- 案件情報を自動取得し、ポイ活を効率化したい!
ポイ活とは?

ポイ活とは、「ポイントサイト」を通じて、ポイントを稼ぐ活動を指します。
ポイントサイトとは、サイト内で紹介中の商品やサービスを購入・利用することによってポイントが貯まるサイトです。例えば、あるポイントサイトを経由して証券口座開設を行うことで、5000ポイントを獲得することができます。
【Python】Selenium(セレニウム)とは
Seleniumとは、Webブラウザを起動し操作自動化を実現できるPythonモジュールです。Seleniumを用いると、例えばブラウザ上のフォーム記入、マウスクリック、ブラウザ画面遷移という操作が自動化可能です。
Seleniumの概要や基礎的なコーディング方法についてはこちらの記事で詳しく解説しています。
【Python】Seleniumとは?Webブラウザ操作の自動化方法を徹底解説
PythonでWebブラウザの自動操作を実現したい方向けに「Seleniumの概要」「Seleniumの利用手順」について詳しく解説します。
【参考】Selenium学習におすすめの教材
Seleniumによるブラウザ操作について詳しく学習したい方向けにおすすめの教材をご紹介します。

【Python】仮想通貨ポイント獲得案件をプログラムで自動取得!

本記事ではポイ活サイトで稼ぎたい!という方向けにポイ活作業を効率化できる自動操作プログラムの構築術について解説します。その際、上記のビッコレというポイントサイトを題材としてプログラムを構築していきます。事前に会員登録しておきましょう。
【実践】Python×Seleniumを活用したポイ活案件の自動取得
それでは実際にPythonプログラムをもとにポイ活サイトの案件情報を自動取得するコードを記述していきます。
会員情報
ポイ活サイトにログインするためのメールアドレスとパスワードを記載し、そのコードを先頭に配置します。
# ======================================================
# 会員情報
# ======================================================
user_mail = "登録したメールアドレス"
password = "パスワード"ライブラリの読込
ブラウザを自動操作するためのSeleniumライブラリをはじめ、データ処理のためのPandasライブラリを読込ます。以下を実行しましょう。
# ======================================================
# ライブラリ
# ======================================================
# 待機時間
from time import sleep
# データ処理
import pandas as pd
# Selenium関連
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import Select
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
# Chrome Driver(自動取得)
from webdriver_manager.chrome import ChromeDriverManagerポイ活サイトログイン
ポイ活サイトにログインするためのコードを以下に示します。
# ======================================================
# ログイン
# ======================================================
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from time import sleep
# ブラウザインスタンス
browser = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
# リンクを開く
browser.get("https://bikkore.jp/login")
# メールアドレス入力
browser.find_element(By.NAME, "email").send_keys(user_mail)
# パスワード
browser.find_element(By.NAME, "password").send_keys(password)
# ログインボタン
browser.find_element(By.CLASS_NAME, "login-submit-btn").find_element(By.TAG_NAME, "button").click()
sleep(8)ポイ活案件情報取得
ポイ活サイトの掲載されている案件情報を自動取得するためのコードを以下に示します。今回は例として、比較的容易に達成できるスマホ系案件を自動取得したいと思います。他のカテゴリ案件の情報を取得したい場合、コード6行目のcategoryを編集すると良いです。例えば、クレジットカード系案件であればカテゴリ番号=3とし、アンケート系であればカテゴリ番号=21になります。実際のサイトのURLを見るとカテゴリ番号は確認が可能です。
# ======================================================
# URL設定情報
# ======================================================
# カテゴリ番号(スマホはカテゴリ番号=8)
category = "8"
smartphone_url = f"https://bikkore.jp/matter/category/{category}"
# ページ数
pages = ["", "2", "3", "4", "5", "6"]
# ======================================================
# データ取得
# ======================================================
from selenium.webdriver.common.by import By # ← Selenium 4 対応のため追加
from time import sleep
import pandas as pd
title = []
contents = []
points = []
links = []
for j in range(len(pages)):
try:
# カテゴリページ(スマホ)
URL = f'{smartphone_url}&page={pages[j]}?page={pages[j]}'
browser.get(URL)
# ポイ活リスト
elem = browser.find_element(By.CLASS_NAME, "main").find_element(By.CLASS_NAME, "result")
p_lists = elem.find_elements(By.TAG_NAME, "li")
# データ取得
for i in range(len(p_lists)):
# 各種情報取得
p_title = p_lists[i].find_element(By.CLASS_NAME, "result-title").text
p_content = p_lists[i].find_element(By.CLASS_NAME, "result-desc").text
p_point = p_lists[i].find_element(By.CLASS_NAME, "result-price").text
p_link = p_lists[i].find_element(By.TAG_NAME, "a").get_attribute("href")
# リストに格納
title.append(p_title)
contents.append(p_content)
points.append(p_point)
links.append(p_link)
# 待機時間
sleep(5)
except:
print("該当ページなし")
break
# ブラウザを閉じる
browser.quit()
# ======================================================
# テーブルデータ化
# ======================================================
# データフレーム
data = pd.DataFrame()
data["タイトル"] = title
data["URL"] = links
data["概要"] = contents
data["獲得ポイント"] = points
# 重複削除
data.drop_duplicates(subset='タイトル', keep="first", inplace=True)エクセルとしてデータ抽出
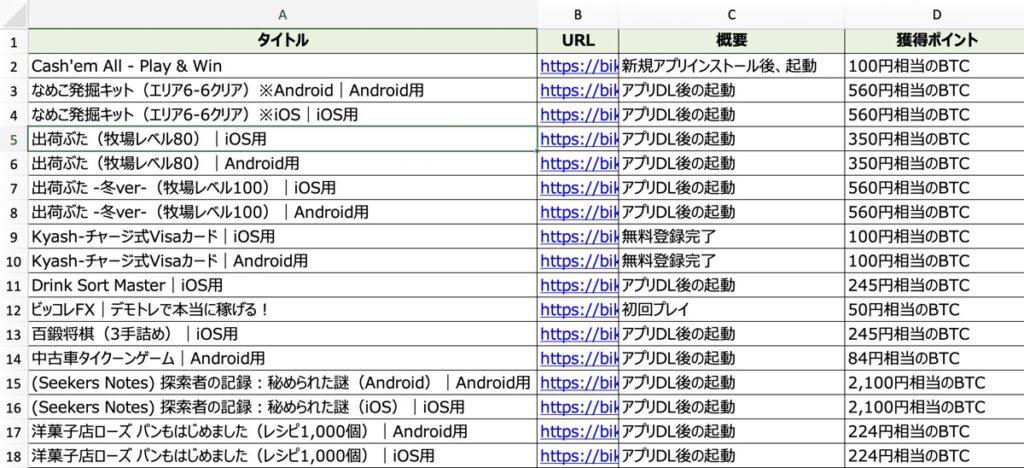
最後に取得した案件情報を上図のようにエクセルにまとめた上でファイルを保存するコードを示します。
# ======================================================
# エクセル保存
# ======================================================
data.to_excel("ビッコレ_ポイ活内容一覧.xlsx",index=False)【Python】ポイ活案件の自動取得コード全量
最後に、本日ご紹介したプログラムの全量を以下に示します。
# ======================================================
# 会員情報
# ======================================================
user_mail = "登録したメールアドレス"
password = "パスワード"
# ======================================================
# ライブラリ
# ======================================================
# 待機時間
from time import sleep
# データ処理
import pandas as pd
# Selenium
from selenium import webdriver
from selenium.webdriver.support.ui import Select
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
# Chrome Driver
from webdriver_manager.chrome import ChromeDriverManager
# ======================================================
# ログイン
# ======================================================
# ブラウザインスタンス
browser = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
# リンクを開く
browser.get("https://bikkore.jp/login")
# メールアドレス入力
browser.find_element(By.NAME, "email").send_keys(user_mail)
# パスワード
browser.find_element(By.NAME, "password").send_keys(password)
# ログインボタン
browser.find_element(By.CLASS_NAME, "login-submit-btn").find_element(By.TAG_NAME, "button").click()
sleep(8)
# ======================================================
# URL設定情報
# ======================================================
# カテゴリ番号
category = "8"
smartphone_url = f"https://bikkore.jp/matter/category/{category}"
# ページ数
pages = ["","2","3","4","5","6"]
# ======================================================
# データ取得
# ======================================================
title = []
contents = []
points = []
links = []
for j in range(len(pages)):
try:
# カテゴリページ(スマホ)
URL = f'{smartphone_url}&page={pages[j]}?page={pages[j]}'
browser.get(URL)
# ポイ活リスト
elem = browser.find_element(By.CLASS_NAME, "main").find_element(By.CLASS_NAME, "result")
p_lists = elem.find_elements(By.TAG_NAME, "li")
# データ取得
for i in range(len(p_lists)):
# 各種情報取得
p_title = p_lists[i].find_element(By.CLASS_NAME, "result-title").text
p_content = p_lists[i].find_element(By.CLASS_NAME, "result-desc").text
p_point = p_lists[i].find_element(By.CLASS_NAME, "result-price").text
p_link = p_lists[i].find_element(By.TAG_NAME, "a").get_attribute("href")
# リストに格納
title.append(p_title)
contents.append(p_content)
points.append(p_point)
links.append(p_link)
# 待機時間
sleep(5)
except:
print("該当ページなし")
break
# ブラウザを閉じる
browser.quit()
# ======================================================
# テーブルデータ化
# ======================================================
# データフレーム
data = pd.DataFrame()
data["タイトル"] = title
data["URL"] = links
data["概要"] = contents
data["獲得ポイント"] = points
# 重複削除
data.drop_duplicates(subset='タイトル', keep="first", inplace=True)
# ======================================================
# エクセル保存
# ======================================================
data.to_excel("ビッコレ_ポイ活内容一覧.xlsx", index=False)
【参考】Python×Selenium関連記事
当サイトでは、Seleniumに関する記事を多数配信しております。
【参考】Pythonを活用した様々なお役立ち情報

当サイトではPythonを活用した様々なお役立ち情報を配信しています。
Pythonでできること・仕事に応用
「Pythonで実現できることを知りたい」「Pythonスキルを仕事で活かしたい」方はこちら!
Python✖️AI・機械学習
Python活用の最大メリットの1つであるAI・機械学習について詳しく知りたい方はこちら!

Python✖️投資自動化(仮想通貨)
Pythonはフィンテックとの相性が良く、その中でも仮想通貨自動売買タスクは近年注目度の高い領域です。フィンテック・投資に興味がある方はこちら!

