
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- Pythonのscikit-learnを用いて決定木の分類モデルを構築したい。
- 決定木の学習済みモデルを可視化・推論・性能評価する方法が知りたい。
【AI・機械学習】決定木(ディシジョンツリー)とは?

決定木とは「YES or NO」や「100以上 or 100未満」のように、2つの分岐する回答が得られる条件によって予測を行う方法を指します。決定木アルゴリズムは、人間の思考プロセスに近い方法であるため、結果が分かりやすく、説明性が高いという点が特徴的です。
上図を見てみましょう。決定木は、一番上のデータグループから成る根(Root)ノードをはじめ、枝分かれ部分を指す枝(Branch)ノード、最終的な決定木の分類を指す葉(Leaves)ノードで構成されます。また、あるノードに対して分岐前のノードを親ノード、分岐後のノードを子ノードと呼びます。さらに、決定木の枝となる分岐ラインをエッジと呼びます。
決定木のさらなる詳しい概要はこちらの記事でまとめていますので併せてご覧ください。
【機械学習】決定木とは?|概要・種類(分類木・回帰木)・Python実装方法
AI・機械学習・データサイエンス・アナリティクス・RPA自動化・デジタルマーケティング・フィンテック等の最新デジタル技術を幅広く配信
【Python】scikit-learnで決定木の分類モデル実装
Python環境下でscikit-learnという機械学習ライブラリを用い、決定木モデルを構築する方法を解説します。
モデル構築は、以下の手順に従っていきます。
- データセットの説明
- データの準備
- モデル学習
- 決定木の可視化
- モデル推論
- モデル評価
データセットの説明

データセットには、機械学習のサンプルデータとして有名なIris(アヤメ)データセットを活用します。3種類のアヤメ(Iris Setosa, Iris Versicolor, Iris Virginica)があり、それぞれ50サンプルずつ(合計150サンプル)用意されているデータです。このアヤメの名前を目的変数として利用します。また、説明変数にはアヤメの計測値である萼片(sepals)と花びら(petals)の長さと幅の4つを利用します。
データの準備
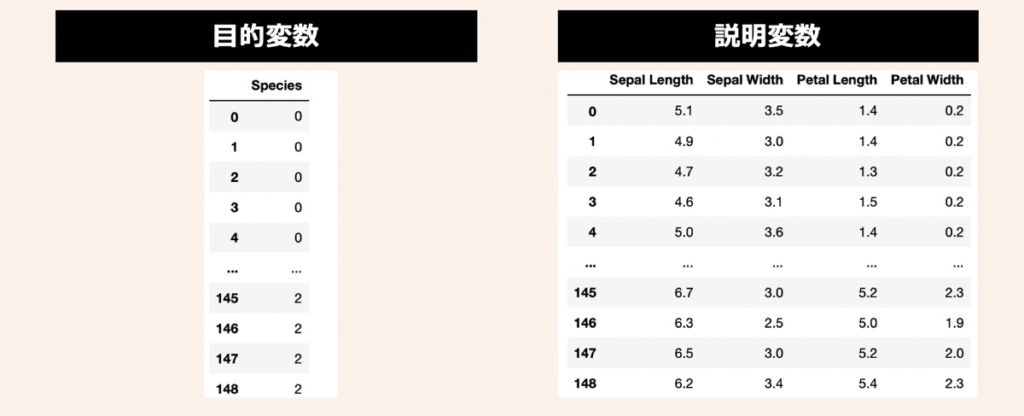
まず、前述したアヤメのデータセットを準備します。上記目的変数と説明変数をPandas形式で取り扱うために、下記のコードを実行してみましょう。
# =================================================
# データ読込
# =================================================
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
# データロード
iris = datasets.load_iris()
# 説明変数
X = iris.data
X = pd.DataFrame(X, columns=["Sepal Length", "Sepal Width", "Petal Length", "Petal Width"])
# 目的変数
Y = iris.target
Y = pd.DataFrame(Y, columns = ["Species"])
# 学習データとテストデータ分割
X_train,X_test,Y_train,Y_test = train_test_split(X,Y, test_size=0.3, shuffle=True, random_state=3)モデル学習
前述で定義した学習データX_train, Y_trainを活用し、分類木モデルを構築します。以下コードを実行しましょう。
# =================================================
# モデル学習
# =================================================
from sklearn.tree import DecisionTreeClassifier
# 決定木インスタンス
tree_model = DecisionTreeClassifier(criterion='gini', # 不純度の計測指標
splitter='best', # 各ノードの分割方法
max_depth=None, # 決定木の深さの最大値
min_samples_split=2, # 枝の分岐作成に必要な最低データ数
min_samples_leaf=1, # 葉ノードの作成に必要な最低データ数
min_weight_fraction_leaf=0.0, # 各葉ノードに必要なデータの割合の最小値
max_features=None, # 分割時に利用する特徴数の最大値
random_state=None, # 乱数シード
max_leaf_nodes=None, # 作成する葉ノードの最大値
min_impurity_decrease=0.0, # ノードの分割実行するための不純度の最小減少度
class_weight=None, # 各クラスラベルに対する重み
ccp_alpha=0.0 # コスト複雑度枝刈りのパラメータ
)
# モデル学習
tree_model.fit(X_train,Y_train)引数情報
決定木の分類モデル作成に用いたDecisionTreeClassifier()メソッドの引数情報を以下に示します。
| 引数名 | 意味 | デフォルト値 |
|---|---|---|
| criterion | 不純度の計算指標。ジニ係数を利用する “gini” または情報量エントロピーを利用する “entropy” を指定。 | “gini” |
| splitter | 各ノードの分割方法 | “best” |
| max_depth | 決定木の深さの最大値。大きい程複雑なモデルができ、分類性能は向上するが、過学習の可能性も高まる。 | None |
| min_samples_split | ノードを分岐に必要なデータの最小値。サンプルが最小値を下回った場合、葉ノードとなる | 2 |
| min_samples_leaf | 葉ノードの作成に必要なデータ数の最小値。指定した値以上のデータ数を持たない葉ノードは作られない | 1 |
| min_weight_fraction_leaf | 各葉ノードに必要なデータの割合の最小値 | 0 |
| max_features | 分割時に利用する特徴数の最大値 | None |
| random_state | 乱数のシード | None |
| max_leaf_nodes | 作成する葉ノードの最大値 | None |
| min_impurity_decrease | 決定木の成長の早期停止するための剪定パラメータ。不純度が指定の値より減少した場合、ノードを分岐し、不純度が指定の値より減少しなければ分岐を抑制。 | 0 |
| class_weight | 各クラスラベルに対する重み | None |
| ccp_alpha | 剪定パラメータ(コスト複雑度枝刈り)ccp_alpha の値が大きいほど剪定されるノード数が増えるため、シンプルなツリーが形成される | 0 |
【Python】Graphvizを用いて決定木を可視化
前述でモデル学習した決定木の分類モデルを用いてツリー構造を可視化します。
- データセットの説明
- データの準備
- モデル学習
- 決定木の可視化
- モデル推論
- モデル評価
【事前準備】Graphvizのインストール
後述の決定木可視化コード利用に際してgraphvizおよびdtreevizのインストールが必要です。
graphviz
pip install graphvizdtreeviz
dtreevizのインストールは、dtreevizのインストール手順を参照下さい。
【graphviz】ツリー構造可視化
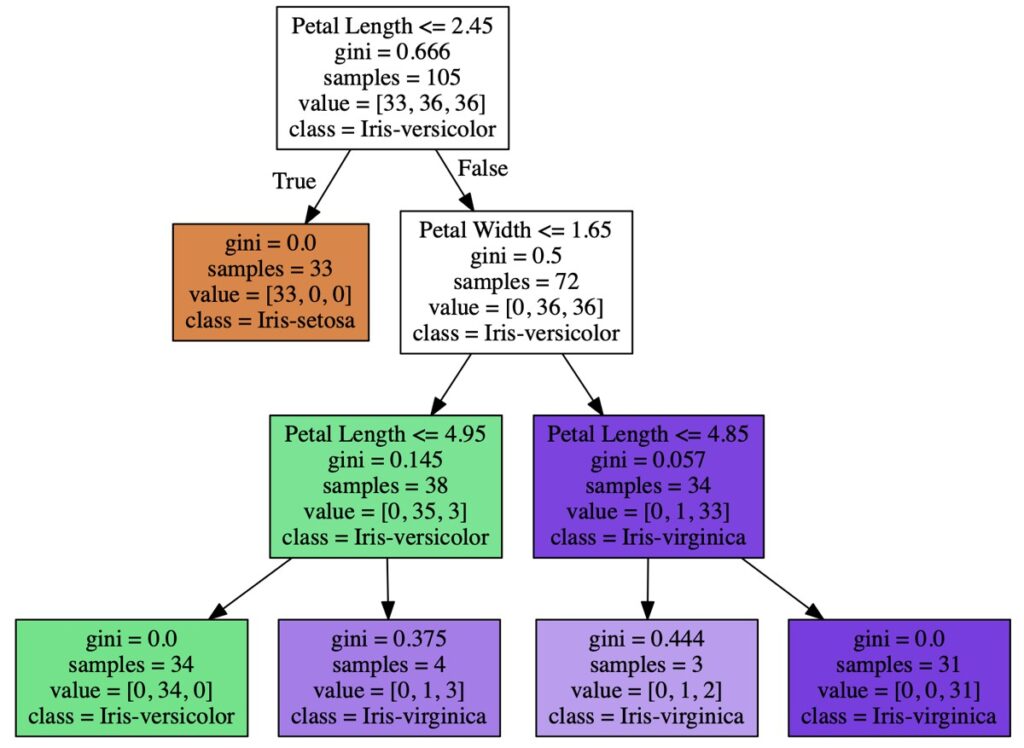
graphvizを用いて上図のようなツリー構造を可視化する場合、以下のコードを実行します。
# =================================================
# 可視化
# =================================================
import graphviz
from sklearn import tree
# 可視化設定
viz = tree.export_graphviz(tree_model, # 決定木モデル
feature_names=X_train.columns.tolist(), # 説明変数項目名
class_names=["Iris-setosa","Iris-versicolor","Iris-virginica"], # 正解ラベル名
filled=True, # 枠内の色塗り有無
)
# グラフ描画
graph = graphviz.Source(viz, format="png")
graph【dtreeviz】ツリー構造可視化
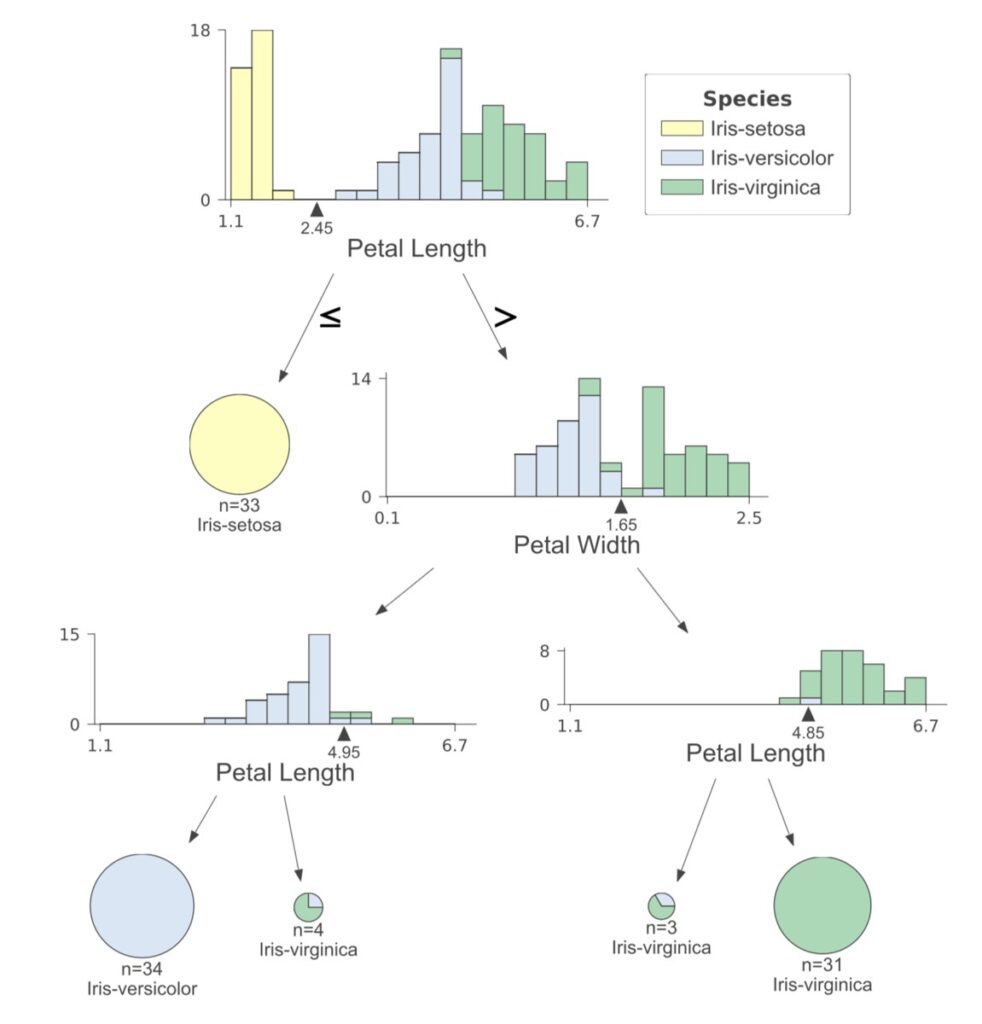
dtreevizを用いて上図のようなツリー構造を可視化する場合、以下のコードを実行します。
# =================================================
# 可視化
# =================================================
from dtreeviz.trees import *
# 可視化設定
viz = dtreeviz(tree_model, # 決定木モデル
X_train, # 説明変数(dataframe形式)
Y_train["Species"], # 正解ラベル(Series形式)
feature_names = X_train.columns.tolist(), # 説明変数項目名
target_name = "Species", # 正解ラベル項目名
class_names = ["Iris-setosa","Iris-versicolor","Iris-virginica"] # 正解ラベル名
)
# 可視化
display(viz)【Python】決定木モデルによる推論・性能評価
前述で作成した分類モデルを用いた推論および性能評価方法について解説します。
- データセットの説明
- データの準備
- モデル学習
- 決定木の可視化
- モデル推論
- モデル評価
モデル推論
前述で作成したモデルの推論結果について観察してます。テスト用データX_testをpredict()メソッドに渡し、予測結果を観察します。
# =================================================
# 推論
# =================================================
Y_pred_tree = tree_model.predict(X_test)
# 出力
print(Y_pred_tree)
# 出力イメージ
# [0 0 0 0 0 2 1 0 2 1 1 0 1 1 2 0 1 2 2 0 2 2 2 1 0 2 2 1 1 1 0 0 2 1 0 0 2 0 2 1 2 1 0 0 2]モデル性能評価
作成したモデルの性能評価を行います。今回は正解率と混合行列を出力した例を示します。正解率の結果は約97.8%となりました。
コード
import numpy as np
from sklearn.metrics import accuracy_score, confusion_matrix
# 推論
Y_pred_tree = tree_model.predict(X_test)
# 混合行列
cf_mat = confusion_matrix(Y_test, Y_pred_tree)
# 出力
print(f'正解率: {accuracy_score(Y_test, Y_pred_tree)}')
print('混合行列')
print(cf_mat)
# 出力イメージ
# 正解率: 0.978
# 混合行列
# [[17 0 0]
# [ 0 13 1]
# [ 0 0 14]]【参考】分類モデルの評価方法
【AI・機械学習】分類モデルの性能評価および評価指標の解説|正解率・適合率・再現率・F値・特異度・偽陽性率
機械学習における分類モデルの性能評価方法について解説します。本記事読了いただくことで、機械学習の集計データに基づきモデルを多様な角度から評価することができるようになります。
【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
