
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- アンサンブル学習「XGBoost」のアルゴリズムを活用して機械学習モデルを構築検討中。
- グリッドサーチによるハイパーパラメータチューニングを行い、XGBoostモデルの予測性能を高めたい!
【機械学習】XGBoostとは
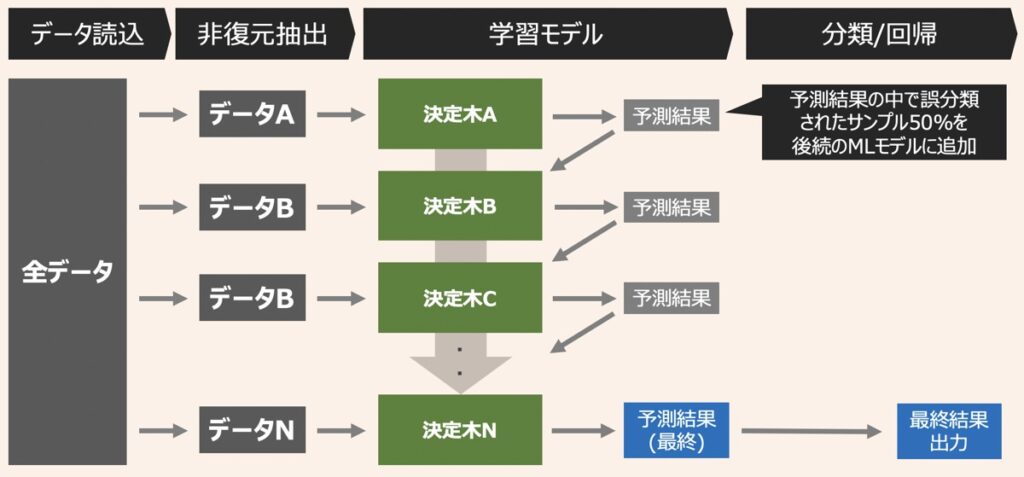
XGBoost(eXtreme Gradient Boosting)とは、アンサンブル学習を代表するアルゴリズムの一つであり、ブースティングと決定木を組み合わせで構成されています。
アンサンブル学習およびXGBoostの具体的内容についてはこちらの記事で解説しています。
【AI・機械学習】アンサンブル学習とは|バギング・ブースティング・スタッキングの仕組みやアルゴリズム解説
機械学習における「アンサンブル学習」について詳しく知りたい方向けに「アンサンブル学習の仕組み」と代表的手法「バギング」「スタッキング」「ブースティング」についてそれぞれ解説します。
【機械学習】XGBoostとは?|Pythonで分類モデルを実装する方法解説
アンサンブル学習の代表的アルゴリズムである「XGBoost」について詳しく知りたい方向けに、「XGBoostの概要」および「Pythonでの実装方法」を解説します。
グリッドサーチとは|ハイパーパラメータ探索メソッド
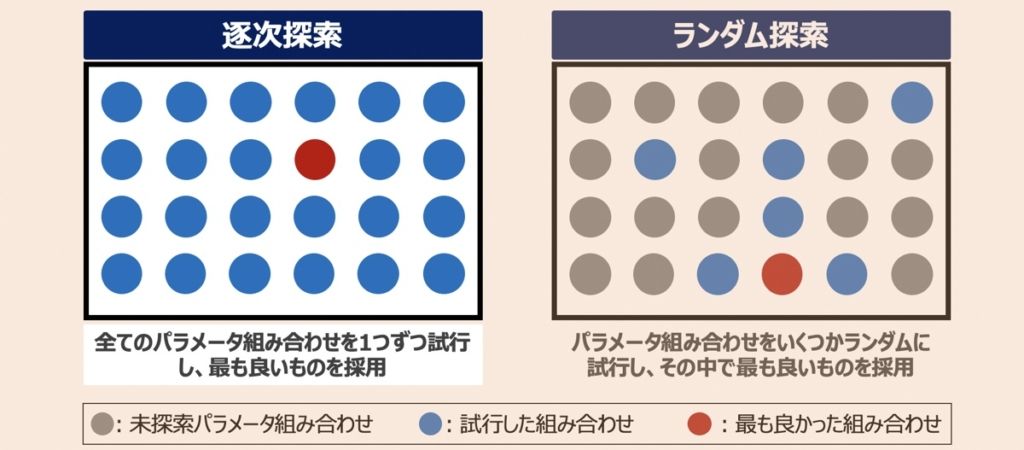
グリッドサーチとは、ハイパーパラメータ探索手法を指します。探索対象のパラメータ候補を列挙し、その全ての組み合わせを照らし合わせ、最適な組み合わせを見つけ出すのが特徴的です。
本記事では、グリッドサーチをもとにXGBoostモデルのハイパーパラメーターチューニングを実施する方法について解説します。
ハイパーパラメーターチューニングの概要について詳しく知りたい方はこちらの記事をご覧下さい。
【AI・機械学習】ハイパーパラメータとは・モデルチューニングの最適化手法(グリッドサーチ・ベイズ最適化等)を徹底解説
機械学習における「ハイパーパラメータの概要・最適化手法」の解説記事です。本記事読了後は、ハイパーパラメータとは何か理解できるとともに、要所に応じた最適なチューニング方法(グリッドサーチ・ランダムサーチ・ベイズ最適化等)を把握できるようになるでしょう。
【Python実践】グリッドサーチでXGBoostモデルのパラメータチューニング
XGBoostモデルの構築とグリッドサーチによるハイパーパラメーターチューニングをPythonで実践する方法について解説します。下記の手順で進めます。
- データセットの説明
- データの準備
- モデル学習・グリッドサーチによるハイパーパラメータチューニング
- 性能評価
データセットの説明

データセットには、機械学習のサンプルデータとして有名なIris(アヤメ)データセットを活用します。3種類のアヤメ(Iris Setosa, Iris Versicolor, Iris Virginica)があり、それぞれ50サンプルずつ(合計150サンプル)用意されているデータです。このアヤメの名前を目的変数として利用します。また、説明変数にはアヤメの計測値である萼片(sepals)と花びら(petals)の長さと幅の4つを利用します。
データの準備
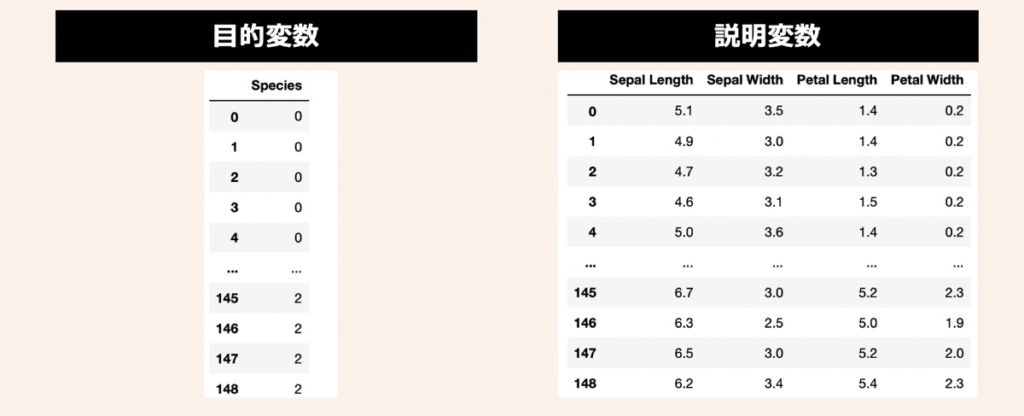
まず、前述したアヤメのデータセットを準備します。上記目的変数と説明変数をPandas形式で取り扱うために、下記のコードをPythonファイルの先頭に配置し、実行してみましょう。
# ============================================================
# データセットの準備
# ============================================================
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
# データロード
iris = datasets.load_iris()
# 説明変数
X = iris.data
X = pd.DataFrame(X, columns=["Sepal Length", "Sepal Width", "Petal Length", "Petal Width"])
# 目的変数
Y = iris.target
Y = iris_target = pd.DataFrame(Y, columns = ["Species"])
# 学習データとテストデータ分割
X_train,X_test,Y_train,Y_test = train_test_split(X,Y, test_size=0.3, shuffle=True, random_state=3)【モデル学習】グリッドサーチによるハイパーパラメータチューニング
モデル学習プロセスでは、まず、XGBoostに用いるパラメータセットparametersとモデルインスタンスmodelを用意します。続いて、パラメータとインスタンスをグリッドサーチGridSearchCV()メソッドに渡すことで、ハイパーパラメータ探索を開始しています。以下、コードを実行してみましょう。
# ============================================================
# モデル学習 & ハイパーパラメータチューニング
# ============================================================
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
# XGBoostの可変パラメータ(探索したいパラメータ候補を自由に設定)
parameters = {
'learning_rate': [0.2,0.6,1], # 過学習防止を目的とした学習率
'max_depth': [3,6,9], # 決定木の深さの最大値
'reg_lambda':[0.5,1], # L2正則化のペナルティ項
}
# XGBoost分類モデルのインスタンス
model = XGBClassifier()
# グリッドサーチ
grid_search = GridSearchCV(estimator = model, # モデルインスタンス
param_grid = parameters, # チューニングするパラメータ
scoring = "accuracy", # スコアリング方法
)
# 演算実行
grid_search.fit(X_train, Y_train) 上記を実行後、grid_search.best_params_を実行すると、探索で得られた最適なXGBoostのパラメータ候補が確認できます。この結果を用いて後述でモデル再学習を行います。
# グリッドサーチの結果から得られたbestパラメータ出力
print('Best params are: {}'.format(grid_search.best_params_))
# 出力イメージ
# Best params are: {'learning_rate': 0.6, 'max_depth': 3, 'reg_lambda': 0.5}【モデル再学習】最適なパラメータでXGBoost分類モデル構築
前述で得られた最適なパラメータ組み合わせ結果をもとにモデルを再学習します。以下を実行しましょう。
# ============================================================
# モデル再学習
# ============================================================
# XGBoost分類モデルのインスタンス
model = XGBClassifier(learning_rate = grid_search.best_params_['learning_rate'], # 過学習防止を目的とした学習率
max_depth = grid_search.best_params_['max_depth'], # 決定木の深さの最大値
reg_lambda = grid_search.best_params_['reg_lambda'], # L2正則化のペナルティ項
)
# モデル学習
model.fit(X_train,Y_train)性能評価
再学習モデルの性能評価です。参考として正解率・再現率・適合率を確認できるコードを示します。
# ============================================================
# 性能評価
# ============================================================
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
# 推論
Y_pred = model.predict(X_test)
# 性能評価
print("正解率: " + str(round(accuracy_score(Y_test,Y_pred),3)))
print("適合率: " + str(round(precision_score(Y_test,Y_pred, average="macro"),3)))
print("再現率: " + str(round(recall_score(Y_test,Y_pred, average="macro"),3)))
# 出力結果
# 正解率: 0.978
# 適合率: 0.978
# 再現率: 0.976【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
