
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- AI・機械学習理論および実装方法の習得に興味あり。
- 「XGBoost」を採用した分類モデルをPythonで実装する方法が知りたい。
XGBoost(eXtreme Gradient Boosting)とは?
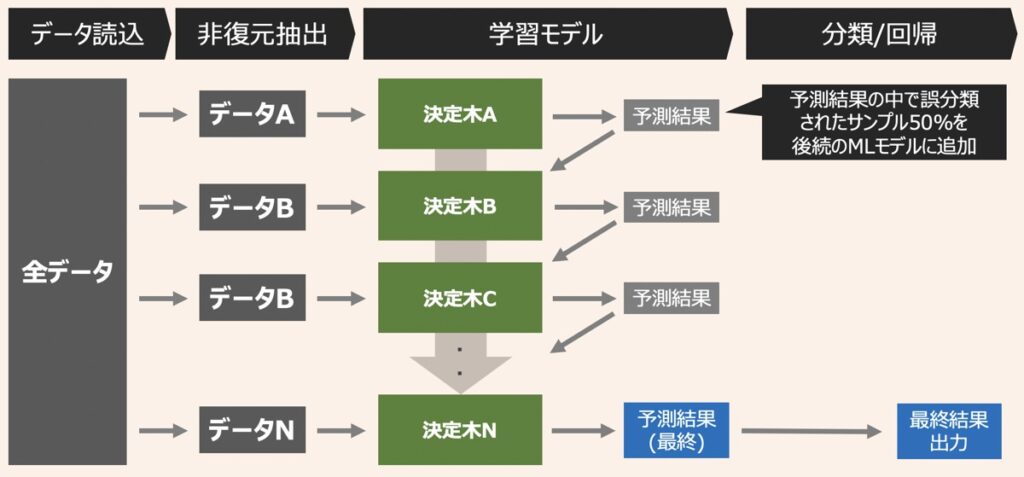
XGBoost(eXtreme Gradient Boosting)とは、アンサンブル学習を代表するアルゴリズムの一つであり、ブースティングと決定木を組み合わせで構成されています。
ブースティングとは、複数の弱い機械学習モデル(弱学習器)を直列に組み合わせ、高性能な予測モデル構築を目指した学習手法です。このブースティングの手法において、弱学習器に決定木を採用している点がXGBoostの特徴と言えます。
XGBoostでは、決定木Aをもとに1回目の予測結果を出力します。続いて、トレーニングデータの正解ラベルと予測結果の差をもとに、誤差(残差)を算出します。さらに、この誤差を後続の決定木Bに渡します。この時決定木Bは、決定木Aで得られた誤差を修正するために、誤差も正解ラベルとして用い、2回目の予測結果を出力します。このような学習プロセスをN回繰り返すことで、新しい決定木が古い決定木の欠点を穴埋めしながら予測性能を高めていくのです。
最終的な予測結果は1回目の予測結果にその後の予測結果をN倍して足し合わせたものになります。この定数Nを何にするかによって学習結果が変わるため、実装の際は留意が必要です。
アンサンブル学習およびブースティングの概要について詳しく知りたい方はこちらの記事をご覧ください。
【AI・機械学習】アンサンブル学習とは|バギング・ブースティング・スタッキングの仕組みやアルゴリズム解説
機械学習における「アンサンブル学習」について詳しく知りたい方向けに「アンサンブル学習の仕組み」と代表的手法「バギング」「スタッキング」「ブースティング」についてそれぞれ解説します。
Pythonライブラリインストール|XGBoost
XGBoostをPython環境での利用に際して、次のライブラリをインストールしておく必要があります。
pip install xgboost【Python】XGBoost分類モデルの実装方法
Python環境下でXGBoost分類モデルを構築する方法を解説します。以下の手順に従っていきます。
- データセットの説明
- データの準備
- モデル学習
- 決定木の可視化
- モデル推論
- モデル評価
データセットの説明

データセットには、機械学習のサンプルデータとして有名なIris(アヤメ)データセットを活用します。3種類のアヤメ(Iris Setosa, Iris Versicolor, Iris Virginica)があり、それぞれ50サンプルずつ(合計150サンプル)用意されているデータです。このアヤメの名前を目的変数として利用します。また、説明変数にはアヤメの計測値である萼片(sepals)と花びら(petals)の長さと幅の4つを利用します。
データの準備
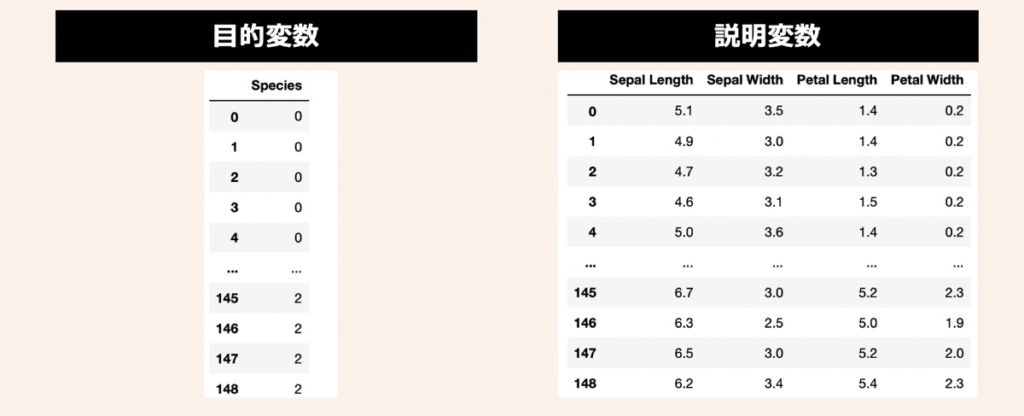
まず、前述したアヤメのデータセットを準備します。上記目的変数と説明変数をPandas形式で取り扱うために、次のようなコードを先頭に配置し、実行してみましょう。この時、データセットは学習用とテスト用で事前に分割しておきます。
# ============================================================
# データセットの準備(Sckit-learnで提供されているアヤメのデータを利用)
# ============================================================
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
# データロード
iris = datasets.load_iris()
# 説明変数
X = iris.data
X = pd.DataFrame(X, columns=["Sepal Length", "Sepal Width", "Petal Length", "Petal Width"])
# 目的変数
Y = iris.target
Y = iris_target = pd.DataFrame(Y, columns = ["Species"])
# 学習データとテストデータ分割
X_train,X_test,Y_train,Y_test = train_test_split(X,Y, test_size=0.3, shuffle=True, random_state=3)モデル学習
前述で用意した学習用のデータセットを活用し、XGBoostの分類モデルを作成します。次のようなコードを実行しましょう。
コード
# ============================================================
# モデル学習
# ============================================================
import xgboost
from xgboost import XGBClassifier
# XGBoost分類モデルのインスタンス
model_XGB = XGBClassifier(booster="gbtree", # ブースター種類(ツリーモデル:gbtree or dart, 線形モデル:gblinear)
learning_rate=1, # 過学習防止を目的とした学習率
min_split_loss=0, # 決定木の葉ノード追加に伴う損失減少の下限値
max_depth=6, # 決定木の深さの最大値
min_child_weight=1, # 決定木の葉に必要な重みの下限
subsample=1, # 各決定木においてランダム抽出されるサンプル割合
sampling_method="uniform", # サンプリング方法
colsample_bytree=1, # 各決定木でランダムに設定される説明変数の割合
colsample_bylevel=1, # 決定木が深さ単位で分割される際に利用する説明変数の割合
reg_lambda=1, # L2正則化のペナルティ項
reg_alpha=0, # L1正則化のペナルティ項
tree_method="auto", # ツリー構造アルゴリズム
process_type="default", # 実行するブースティングプロセス
grow_policy="depthwise", # 新しい葉ノードを木に追加する際の制御ポリシー
max_leaves=0, # 追加する葉ノードの最大数
objective="reg:squarederror", # 学習プロセスで最小化を目指す損失関数
num_round=9, # ブースティング回数(=作成する決定木の本数)
)
# モデル学習
model_XGB.fit(X_train, Y_train)出力イメージ
モデル学習後、次のような出力結果が得られます。
# XGBClassifier(base_score=0.5, booster='gbtree', callbacks=None,
# colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,
# early_stopping_rounds=None, enable_categorical=False,
# eval_metric=None, gamma=0, gpu_id=-1, grow_policy='depthwise',
# importance_type=None, interaction_constraints='', learning_rate=1,
# max_bin=256, max_cat_to_onehot=4, max_delta_step=0, max_depth=6,
# max_leaves=0, min_child_weight=1, min_split_loss=0, missing=nan,
# monotone_constraints='()', n_estimators=100, n_jobs=0,
# num_parallel_tree=1, objective='multi:softprob', predictor='auto',
# process_type='default', ...)引数情報|XGBClassifier()
XGBoostのモデル学習では、XGBClassfier()メソッドを活用します。以下、代表的な引数を示します。詳細はXGBoost公式ドキュメントが参考になります。
| 引数名 | 意味 | デフォルト値 |
|---|---|---|
| booster | ブースター種類 ・”gbtree”(ツリーモデル) ・”dart”(ツリーモデル) ・”gblinear”(線形モデル) | gbtree |
| learning_rate | 過学習防止を目的に利用する学習率。小さい程モデルの分類性能は向上するが、過学習の可能性も高まる。 | 0.3 |
| min_split_loss | 決定木の葉ノード追加に伴う損失減少の下限値。 | 0 |
| max_depth | 決定木の深さの最大値。大きい程複雑なモデルができ、分類性能は向上するが、過学習の可能性も高まる。 | 6 |
| min_child_weight | 決定木の葉に必要な重みの下限。重みの合計が指定の値未満の場合、それ以上決定木が分割されなくなる。下限が大きい程シンプルな決定木となり、過学習抑制に効果あり。 | 1 |
| subsample | 各決定木においてランダム抽出されるサンプル(標本)の割合。例えば、0.5と設定した場合、50%のトレーニングデータを活用して学習を行う。値が、小さい程過学習の抑制が可能だが、保守的なモデルとなる。 | 1 |
| sampling_method | 学習データのサンプリング方法。 | “uniform” |
| colsample_bytree | 各決定木でランダムに利用される説明変数の割合。値を1未満に設定すると、説明変数を全て使わず、ランダムに抽出されたもののみを使用。 | 1 |
| colsample_bylevel | 決定木が深さ単位で分割される際に利用する説明変数の割合。 | 1 |
| reg_lambda | L2正則化のペナルティ項。 | 1 |
| reg_alpha | L1正則化のペナルティ項。 | 0 |
| tree_method | XGBoostで使用されるツリー構造アルゴリズム | “auto” |
| scale_pos_weight | 正負の重みのバランス制御。不均衡なクラスの場合に有効。 | 1 |
| process_type | 実行するブースティングプロセス | “default” |
| grow_policy | 新しい葉ノードを木に追加する際の制御ポリシー。 | “depthwise” |
| max_leaves | 追加する葉ノードの最大数。 | 0 |
| objective | 学習時に最小化を目指す損失関数。 | “reg:squarederror” |
| eval_metic | テストデータに対する評価指標。デフォルト値はobjectiveで設定した損失関数によって自動的に決定される。 | objectiveにより異なる |
| num_round | ブースティング回数(作成する決定木の本数)。XGBoostのコンソール版でのみ有効な引数。 | – |
決定木の可視化
作成したXGBoostモデルの決定木を可視化し、分岐の中身を確認します。
ツリー構造可視化(dtreeviz)
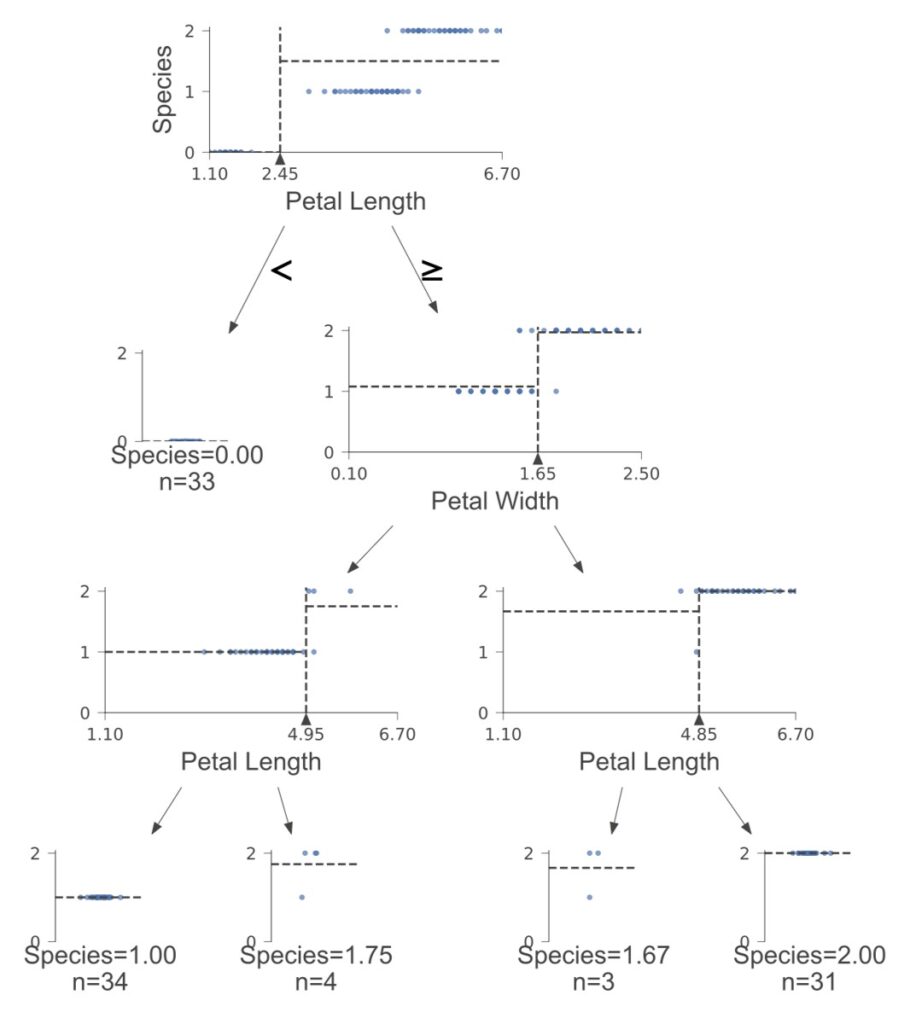
決定木は、dtreevizを用いて可視化できます。決定木可視化の際は、dtreevizのインストール手順を事前に対応しておきましょう。
# ============================================================
# 可視化
# ============================================================
from dtreeviz.trees import dtreeviz
from IPython.display import SVG
# 決定木の分岐可視化
viz = dtreeviz(model_XGB, # モデル
x_data=X_train, # 説明変数(DataFrame)
y_data=Y_train["Species"], # 正解ラベル(Series)
target_name="Species", # 正解ラベルのカラム名
feature_names=X_train.columns.tolist(), # 説明変数項目名
tree_index=0, # 可視化する決定木のインデックス
)
# svg形式で保存
viz.save("xgboost.svg")
# 分岐可視化
SVG(filename="xgboost.svg")ツリー構造可視化(plot_tree)
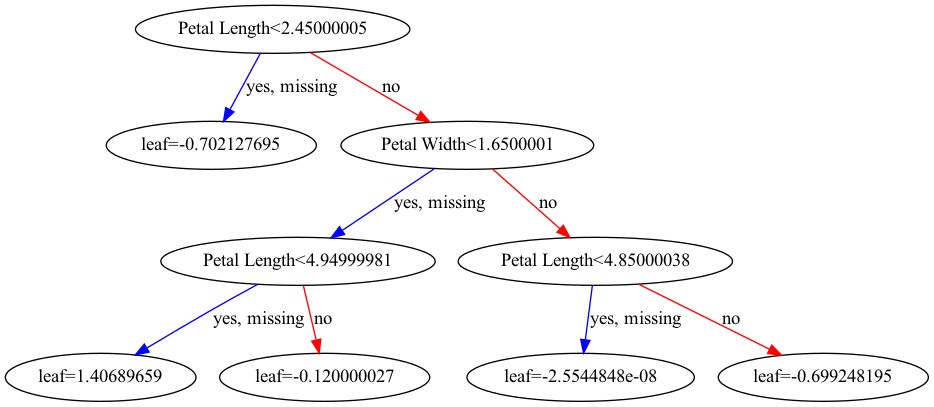
XGBoostには、plot_treeという関数があり、こちらを用いて決定木の構造を可視化することもできます。
# ============================================================
# 可視化
# ============================================================
import matplotlib.pyplot as plt
# 可視化する決定木のインデックス
index_tree = 1
# 可視化設定
tree_plot = xgboost.plot_tree(model_XGB, # モデル
num_trees=index_tree, # 可視化する決定木のインデックス
figsize=(20, 15) # 画像サイズ
)
# グラフ表示
plt.show()
# 画像保存
picture = xgboost.to_graphviz(model_XGB, # モデル
num_trees=index_tree, # 可視化する決定木のインデックス
figsize=(20, 15) # 画像サイズ
)
picture.render("xgb_tree_plot",view=True,format='png')【Python】XGBoost分類モデルによる推論・性能評価
前述で作成したXGBoostの分類モデルをもとに推論および性能評価する方法を解説します。
モデル推論
前述で作成したモデルのもとに予測結果を出力します。predict()メソッドを用いて次のように実行してみましょう。
# ============================================================
# 推論
# ============================================================
Y_pred_XGB = model_XGB.predict(X_test)
# 出力
print(Y_pred_XGB)
# 出力イメージ
# [0 0 0 0 0 2 1 0 2 1 1 0 1 1 2 0 1 2 2 0 2 2 2 1 0 2 2 1 1 1 0 0 2 1 0 0 2 0 2 1 2 1 0 0 2]モデル性能評価
最後に、今回作成したモデルの性能評価を行います。分類モデルの評価として、正解率・再現率・適合率をそれぞれ算出してみましょう。
コード
# ============================================================
# 性能評価
# ============================================================
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
# 推論
Y_pred_XGB = model_XGB.predict(X_test)
# 性能評価
print("正解率: " + str(round(accuracy_score(Y_test,Y_pred_XGB),3)))
print("適合率: " + str(round(precision_score(Y_test,Y_pred_XGB, average="macro"),3)))
print("再現率: " + str(round(recall_score(Y_test,Y_pred_XGB, average="macro"),3)))
# 出力結果
# 正解率: 0.978
# 適合率: 0.978
# 再現率: 0.976【参考】分類モデルの評価方法
機械学習分類モデルの評価指標について詳しく知りたい方はこちらの記事をご覧ください。
【AI・機械学習】分類モデルの性能評価および評価指標の解説|正解率・適合率・再現率・F値・特異度・偽陽性率
機械学習における分類モデルの性能評価方法について解説します。本記事読了いただくことで、機械学習の集計データに基づきモデルを多様な角度から評価することができるようになります。
【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
