
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
Pythonでアソシエーション分析・レコメンド機能の作成に興味がある
Eclatを採用したアソシエーション分析手法について詳しく知りたい
Eclatとは|アソシエーション分析
Python用いてEclatアルゴリズムによるアソシエーション分析を実践する方法について解説します。
アソシエーション分析とは
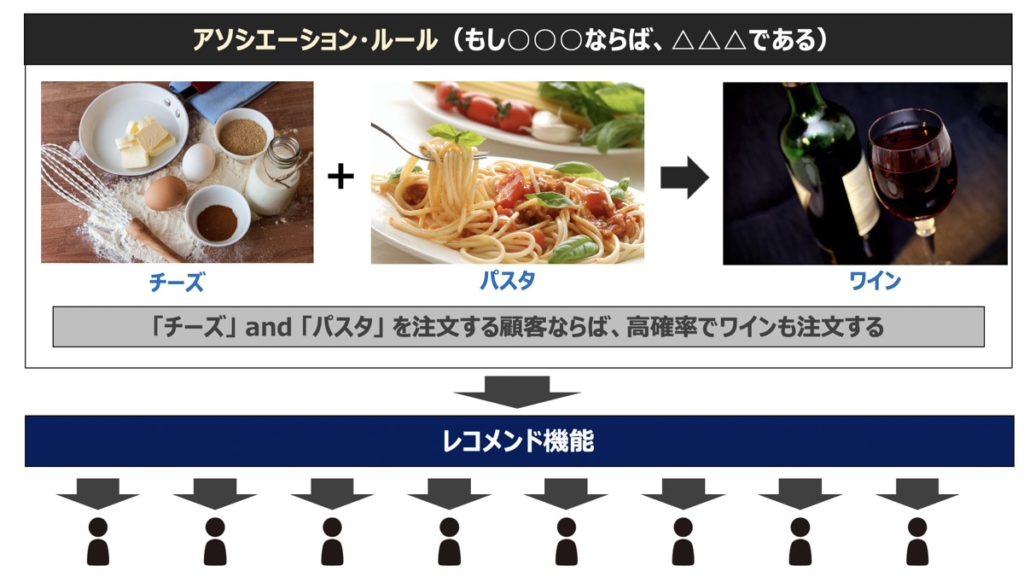
アソシエーション分析とは、大量のデータから「もしAであれば、Bであろう」という有効な傾向をアソシエーション・ルールとして取り出し、マーケティング等のあらゆるビジネス領域に応用するデータマイニング手法です。
アソシエーション分析の概要や評価指標を詳しく知りたい方向けに以下の記事も配信しています。
アソシエーション分析・バスケット分析(併売)とは|マーケティング領域で有効なレコメンド手法を徹底解説
アソシエーション・バスケット分析について詳しく知りたい方向けに、それぞれの分析概要・用途・評価指標(Support, Confidence, Lift)・レコメンド機能との位置付けなど幅広く解説します。
Eclatとは
Eclatとは、アソシエーション分析を実践するためのアルゴリズムを指します。
アソシエーション分析アルゴリズムには、代表的なAprioriをはじめ、EclatやFP Growthがよく用いられます。
Eclat vs Apriori
AprioriとEclatは、アソシエーション・ルール抽出時の検索アルゴリムが異なります。
Eclat アルゴリズムは、設定値として与える最小supportの減少に伴うよる性能悪化がApriori より小さいというメリットがある反面、頻出アイテム(商品・サービス)数が多いとき場合、計算性能が悪化すると指摘されています。
Python環境でAprioriアルゴリズムを用いてアソシエーション分析モデルを作成する方法は、下記の記事で解説しています。
【Python×Apriori】アソシエーション・バスケット分析実践法|マーケティングレコメンド手法への応用支援
Python環境でのアソシエーション分析・レコメンド機能の作成に興味がある方向けに、Aprioriアルゴリズムを採用したアソシエーション分析手法を解説します。
Eclat vs FP Growth
EclatとFP Growthにおける性能面での大きな違いはないと言われています。それぞれのモデル作成に用いる引数が異なる程度です。
【Python】Eclat採用のアソシエーション分析手順
分析手順
Eclatを用いたアソシエーション分析に際して、以下の手順でプログラミングします。
- データセットの説明
- データの準備
- データの加工
- モデル学習
- アソシエーション・ルールの決定
Python環境の構築
本記事では「pyECLAT」というPythonライブラリを用います。事前にインストールしておきましょう。
pip install pyECLAT【Python】Eclat採用のアソシエーション分析を実践
実際にEclat採用のアソシエーション分析を実践していきましょう!
データセットの説明
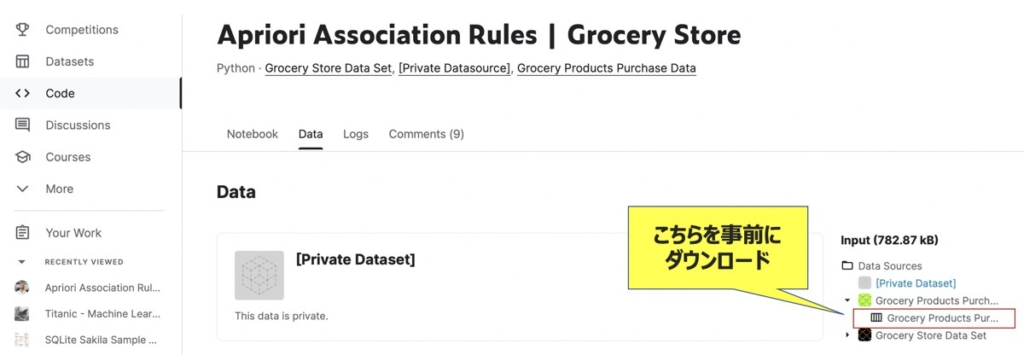
KaggleのApriori Association Grocery Storeにアクセスし、Grocery Products Purchase.csv.xlsをダウンロードしましょう。
これは、あるスーパーマーケットにおける購買データであり、今回こちらを分析対象データとして用います。
このデータセットをもとに、スーパーマーケットで売られている商品の組み合わせに対してアソシエーション分析を適用します。最終的に強い関係性を示す(高頻度で一緒に購入される)商品の組み合わせをアソシエーション・ルールとして抽出することが目的です。
データの準備
前述したデータセットをPython環境で操作するために、以下を実行します。
コード
import matplotlib.pyplot as plt
import pandas as pd
# データセット
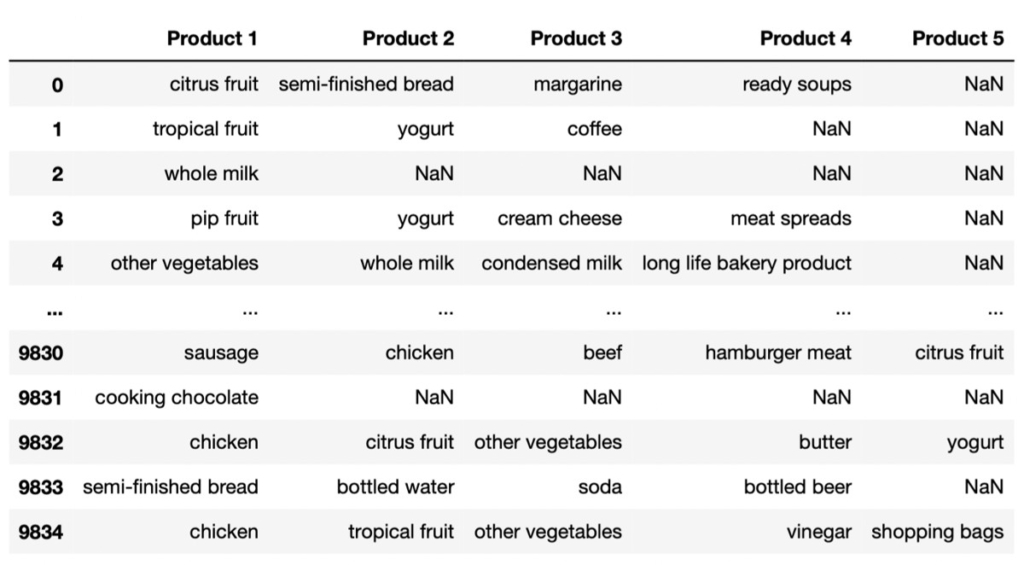
data = pd.read_csv('Grocery Products Purchase.csv.xls', header=None)データイメージ(df)
データ加工
後述ではアソシエーション分析用のモデルを作成し、そのモデルにインプットデータを渡すことで評価結果を取得し、最終的なアソシエーション・ルールの決定に利用します。
ここで、Eclatのモデルに渡すインプットデータの形式は「トランザクション型」にする必要があるため、前述のデータセットをトランザクション型のデータ形式に変換するコードを実行します。
コード
# レコード数
record_len = len(data)
# カラム数
column_len = len(data.columns)
# トランザクション形式に加工
transactions = []
for i in range(record_len):
# データをリスト型に変更
values = [str(data.values[i,j]) for j in range(column_len)]
values_notnull = []
for check in values:
if check != 'nan':
values_notnull.append(check)
transactions.append(values_notnull)データ加工後イメージ(df)
# 出力
print(transactions)
# 出力イメージ
# [['beef'],
# ['frankfurter', 'rolls/buns', 'soda'],
# ['chicken', 'tropical fruit'],
# ['butter', 'sugar', 'fruit/vegetable juice', 'newspapers'],
# ['fruit/vegetable juice'],
# ['packaged fruit/vegetables'],
# ['chocolate'],
# ['specialty bar'],
# ['other vegetables'],
# ['butter milk', 'pastry'],
# ['whole milk'],
# ['tropical fruit','cream cheese','processed cheese','detergent','newspapers'],
# ['tropical fruit','root vegetables','other vegetables','frozen dessert','rolls/buns','bathroom cleaner']]
Eclatモデル作成・アソシエーションルールの決定
前述で取得したトランザクション型のデータを利用し、Eclatアルゴリズムを用いたアソシエーション分析モデルを作成します。
モデル作成
Eclatアルゴリズムのモデルを構築するにはmy_eclat()メソッドを用いて次のように実行します。
from pyECLAT import ECLAT
# 引数情報
min_support = 0.01 # 出力する結果のsupprt最小値
min_n_products = 2 # 最小の商品組み合わせ数
max_length = max([len(x) for x in transactions]) # 出力するアソシエーション・ルール数
# create an instance of eclat
my_eclat = ECLAT(data=data, verbose=True)
# Eclat
rule_indices, rule_supports = my_eclat.fit(min_support=min_support,
min_combination=min_n_products,
max_combination=max_length
)引数情報
my_eclat()メソッドで用いた引数は以下の意味になります。
| 引数情報 | 概要 |
|---|---|
| min_support | 出力結果のSupport最小値 |
| min_combination | 出力結果の最小の商品組み合わせ数 |
| max_combination | 出力結果のアソシエーション・ルール数 |
アソシエーション・ルールの決定
上記で得られた結果を出力し、最適なアソシエーションルールを抽出してみましょう!
コード
print(rule_supports)
# 出力イメージ
# {'potato chips & beer': 0.45, 'cheese & wine': 0.35}【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
