
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- Pythonでアソシエーション分析・レコメンド機能の作成に興味がある
- Aprioriアルゴリズムを採用したアソシエーション分析手法について詳しく知りたい
Aprioriとは|アソシエーション分析
本記事ではPython環境でAprioriアルゴリズムによるアソシエーション分析の実践法を詳しく解説します。
アソシエーション分析とは
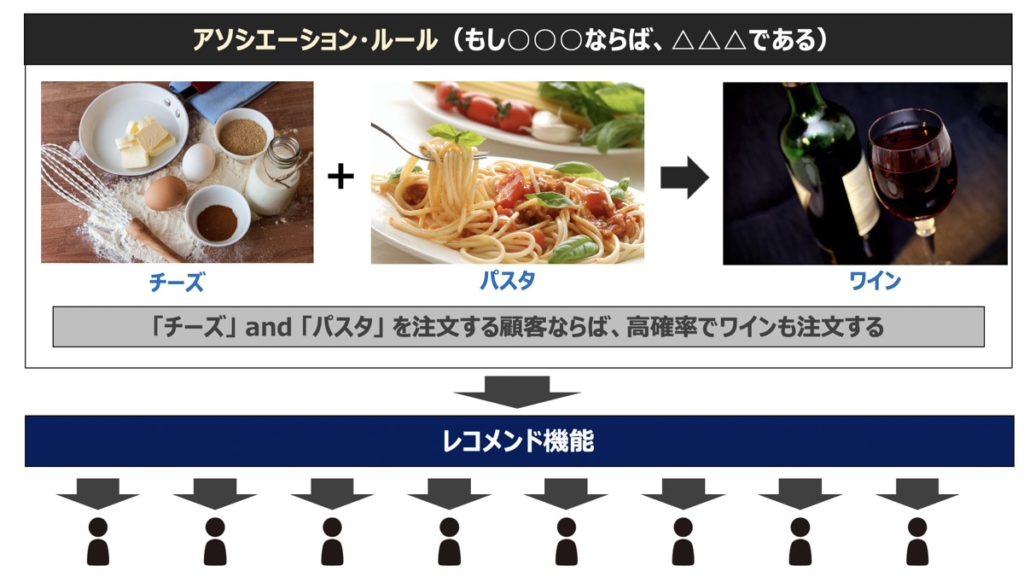
アソシエーション分析とは、大量のデータから「もしAであれば、Bであろう」という有効な傾向をアソシエーション・ルールとして取り出し、マーケティング等のあらゆるビジネス領域に応用するデータマイニング手法です。
本記事では上記詳しい内容は割愛しています。アソシエーション分析の概要や評価指標について詳しく知りたい方はこちらをご覧ください。
アソシエーション分析・バスケット分析(併売)とは|マーケティング領域で有効なレコメンド手法を徹底解説
アソシエーション・バスケット分析について詳しく知りたい方向けに、それぞれの分析概要・用途・評価指標(Support, Confidence, Lift)・レコメンド機能との位置付けなど幅広く解説します。
Aprioriとは
Aprioriとは、アソシエーション分析を実践するためのアルゴリズムを指します。
Aprioriは「頻出アイテム(商品・サービス)の組み合わせを検出し、アソシエーションルールを決定するための評価指標(Support、Confidence、Liftなど)を算出する機能」を有した最も有名なアソシエーション分析アルゴリズムの1つです。
【Python】Apriori採用のアソシエーション分析手順
分析手順
Aprioriアルゴリズムを用いたアソシエーション分析に際して、下記の手順でプログラムを構築していきます。
- データセットの説明
- データの準備
- データの加工
- モデル学習
- アソシエーション・ルールの決定
Python環境の構築
本記事では「mlxtend」というアソシエーション分析を可能にするPythonライブラリを利用します。事前にインストールしておきましょう。
pip install mlxtend【Python】Apriori採用のアソシエーション分析を実践
それでは実際にアソシエーション分析実践のためのプログラムを構築していきます。
データセットの説明
KaggleのApriori Association Grocery Storeにアクセスし、Grocery Products Purchase.csv.xlsをダウンロードしましょう。
これは、あるスーパーマーケットにおける購買データであり、今回こちらを分析対象データとして用います。
このデータセットをもとに、スーパーマーケットで売られている商品の組み合わせに対してアソシエーション分析を適用します。最終的に強い関係性を示す(高頻度で一緒に購入される)商品の組み合わせをアソシエーション・ルールとして抽出することが目的です。
データの準備
前述したデータセット読込のために、次のようなコードを実行します。
コード
import matplotlib.pyplot as plt
import pandas as pd
# データセット
data = pd.read_csv('Grocery Products Purchase.csv.xls')データイメージ(data)
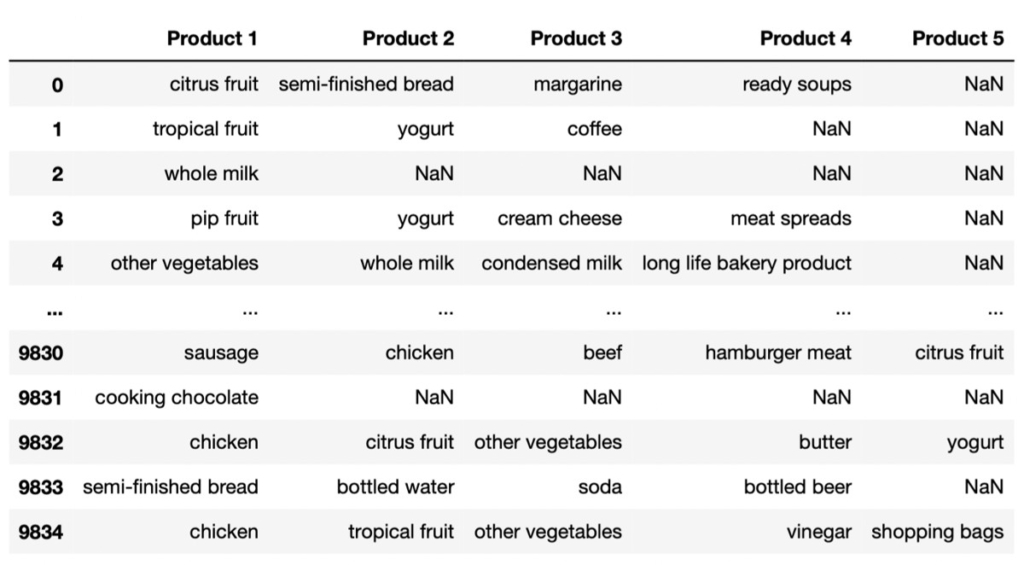
最左のインデックス番号が顧客番号だと考えましょう。顧客番号毎に購入した商品が列として掲載されています。例えば、0番目の顧客であれば、1つ目の商品として「citrus fruit」を購入し、2つ目の商品として「semi-finished bread」を購入したことを意味します。
データ加工|トランザクション形式データセットに変換
後述ではアソシエーション分析用のモデルを構築し、そのモデルにインプットデータを渡すことで、最終的にアソシエーション・ルールを抽出します。ここで、アソシエーションモデルに渡すインプットデータの形式は「トランザクション型」または「テーブル型」という制約があるため、以下に示すデータ加工プログラムを通じて、データ形式を変換しましょう。
前述のデータセットをトランザクション型のデータ形式に変換する方法を以下に示します。
コード
# レコード数
record_len = len(data)
# カラム数
column_len = len(data.columns)
# トランザクション形式に加工
transactions = []
for i in range(record_len):
# データをリスト型に変更
values = [str(data.values[i,j]) for j in range(column_len)]
values_notnull = []
for check in values:
if check != 'nan':
values_notnull.append(check)
transactions.append(values_notnull)トランザクション型データ変換後の出力イメージ
# 結果出力
print(transactions)
# 出力イメージ
# [['citrus fruit', 'semi-finished bread', 'margarine', 'ready soups'],
# ['tropical fruit', 'yogurt', 'coffee'],
# ['whole milk'],
# ['pip fruit', 'yogurt', 'cream cheese', 'meat spreads'],
# ['other vegetables','whole milk','condensed milk','long life bakery product'],
# ['whole milk', 'butter', 'yogurt', 'rice', 'abrasive cleaner'],
# ['rolls/buns'],
# ['other vegetables','UHT-milk','rolls/buns','bottled beer','liquor (appetizer)'],
# ['potted plants'],
# ['whole milk', 'cereals'],
# ['tropical fruit','other vegetables','white bread','bottled water','chocolate'],]上記コード実行により、商品の購入履歴がトランザクションのリスト型として出力されるようになります。
データ加工|テーブル形式データセットに変換
アソシエーション分析モデルに対して、今回は「テーブル型」のインプットデータを渡すこととします。テーブル型とは、データセットの列項目が商品名として表され、各種列項目の値が購入有無による真偽値として表されたデータフレームを指します。
前述で得られたトランザクション型のデータセットをさらに「テーブル型」に変換しましょう。
コード
from mlxtend.preprocessing import TransactionEncoder
# データをテーブル形式に加工
te = TransactionEncoder()
te_array = te.fit(transactions).transform(transactions)
df = pd.DataFrame(te_array, columns=te.columns_)データ加工後イメージ(df)
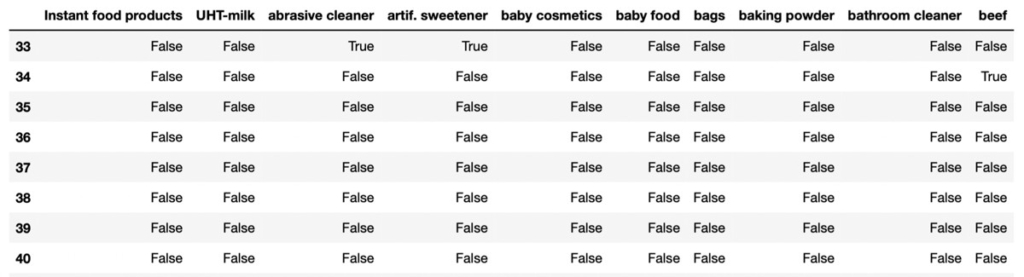
上記のコードを実行すると、データフレームのカラムに商品名が入り、トランザクション番号(index)毎に購入された商品が真偽値(True/False)で表示された結果が得られます。
Aprioriモデル作成・評価
前述で取得したテーブル型のデータセットを用いて、Aprioriによるアソシエーション分析モデルを作成します。
モデル作成|itemsets・support算出
まずはじめに、商品の組み合わせ別に支持度(Support)を算出します。以下を実行しましょう。
Apriori
from mlxtend.frequent_patterns import apriori
freq_items = apriori(df, # データフレーム
min_support = 0.01, # 支持度(support)の最小値
use_colnames = True, # 出力値のカラムに購入商品名を表示
max_len = None, # 生成されるitemsetsの個数
verbose = 0, # low_memory=Trueの場合のイテレーション数
low_memory = False, # メモリ制限あり&大規模なデータセット利用時に有効
)出力イメージ
# 結果出力
freq_items = freq_items.sort_values("support", ascending = False).reset_index(drop=True)
print(freq_items)
# 出力イメージ
# support itemsets
# 0 0.255516 (whole milk)
# 1 0.193493 (other vegetables)
# 2 0.183935 (rolls/buns)
# 3 0.174377 (soda)
# 4 0.139502 (yogurt)
# 5 0.110524 (bottled water)
# 6 0.108998 (root vegetables)
# 7 0.104931 (tropical fruit)
# 8 0.098526 (shopping bags)
# 9 0.093950 (sausage)
# 10 0.088968 (pastry)
# 11 0.082766 (citrus fruit)
# 12 0.080529 (bottled beer)
# 13 0.079817 (newspapers)
# 14 0.077682 (canned beer)mlxtend.frequent_patterns.apriori()メソッドを用いることで、商品の組み合わせ(itemsets)別に支持度(support)を算出できます。
引数情報
mlxtend.frequent_patterns.apriori()メソッドで用いた引数は次のような意味を持ちます。
| 引数情報 | 概要 | デフォルト |
|---|---|---|
| df | 列名に商品名、値に真偽値をもつデータフレームを指定 | – |
| min_support | 結果として生成されるデータのSupport最小値 | 0.5 |
| use_colnames | Trueの場合、itemsetsを商品名称で表示 Falseの場合、itemsetsを商品番号で表示 | False |
| max_len | 結果として生成されるデータのitemsetsの最小個数 | None |
| verbose | low_memory=Trueかつverbose>=1場合のイテレーション数 | 0 |
| low_memory | メモリ制限あり&大規模なデータセットの際に有効 Trueの時、itemsetsの検索制限を設けてメモリ容量を節約 | False |
モデル作成|アソシエーション・ルール決定に用いる評価値算出
上記で得られた結果をもとに、アソシエーション・ルールを抽出するための評価値を取得します。
以下のコードを実行しましょう。
from mlxtend.frequent_patterns import association_rules
# アソシエーション・ルール抽出
df_rules = association_rules(freq_items, # supportとitemsetsを持つデータフレーム
metric = "confidence", # アソシエーション・ルールの評価指標
min_threshold = 0.1, # metricsの閾値
)出力イメージ
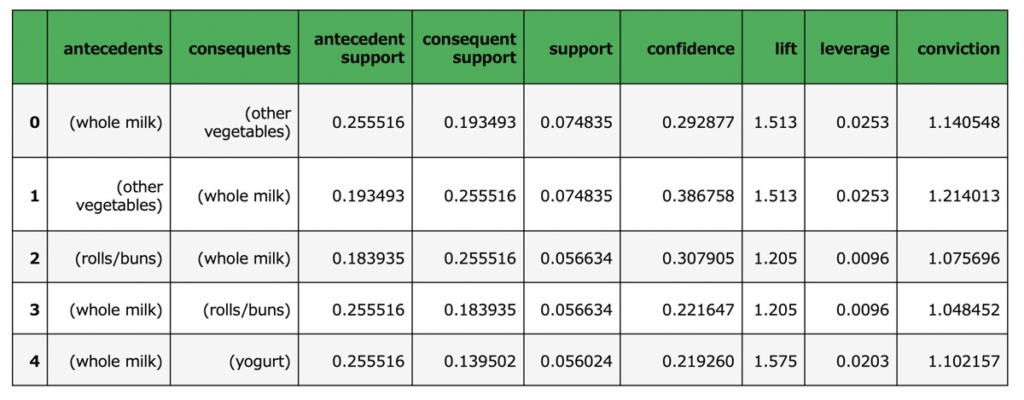
mlxtend.frequent_patterns.association_rules()メソッド用いることで、アソシエーション・ルールの決定するための評価指標が算出できます。
| データ項目 | 項目概要 |
|---|---|
| antecedents | 前提条件(事象A) |
| consequents | 結果(事象B) |
| antecedent support | 全体の中で、事象Aが占める割合(=事象Aの期待信頼度) |
| consequent support | 全体の中で、事象Bが占める割合(=事象Bの期待信頼度) |
| support | 全体の中で、事象Aと事象Bの組み合わせが占める割合 |
| confidence | 事象Aを含むデータの中で、事象Bが占める確率 |
| lift | lift = confidence/consequent support |
| leverage | 事象Aと事象Bの観測頻度と、事象Aと事象Bが独立している場合に予想される頻度の差 leverage=0は完全な独立性を示す |
| conviction | convictionが高い場合、事象Bが事象Aとの相互性が高いことを指す。 |
引数情報
mlxtend.frequent_patterns.association_rules()メソッドで用いる引数は以下になります。
| 引数情報 | 概要 |
|---|---|
| freq_items | itemsetsとsupportを項目に持つデータフレーム |
| metric | アソシエーション・ルールを評価するための項目。以下が指定可能。 ・’support’ ・’confidence’ ・’lift’ ・’leverage’ ・’conviction’ |
| min_threshold | metricsの閾値 |
アソシエーション・ルールの決定
アソシエーション分析モデルより得られた結果をもとにデータを抽出し、最終的なアソシエーション・ルールを決定します。
そのための抽出条件として今回は信頼度>0.2かつリフト値>3.0を設定することとします。
コード
results = df_rules[(df_rules['confidence'] > 0.2) & # 信頼度
(df_rules['lift'] > 3.0)] # リフト値出力結果表
# 結果出力
print(results.loc[:,["antecedents","consequents","confidence","lift"]])
# 出力イメージ
# antecedents consequents confidence lift
# 162 (beef) (root vegetables) 0.331395 3.040367
# 301 (other vegetables, tropical fruit) (root vegetables) 0.342776 3.144780
# 302 (root vegetables, tropical fruit) (other vegetables) 0.584541 3.020999
# 414 (citrus fruit, other vegetables) (root vegetables) 0.359155 3.295045
# 415 (citrus fruit, root vegetables) (other vegetables) 0.586207 3.029608
# 443 (yogurt, other vegetables) (whipped/sour cream) 0.234192 3.267062 上記の結果において、例えば162行目を見ると、「beef」を購入する顧客は「root vegatables」を普通より3倍高い確率で購入していることが分かりました。
レコメンド機能実装やクロスセルを促す際は「もし顧客がbeefを購入する場合、root vegetablesをいくつかレコメンドする」というアソシエーション・ルールが適用できそうですね。
実際のアソシエーション分析では、分析の目的や得られた結果に合わせてアソシエーション・ルールを設定するようにしましょう。
【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
