
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- 多層化されたニューラルネットワークの学習を行う際に考慮すべき「勾配消失問題」について解説!
- 「ニューラルネットワークの学習方法」「勾配消失問題はと何か?」「勾配消失が起こらないための対策」を理解したい方向け!
ニューラルネットワークにおける処理の流れ
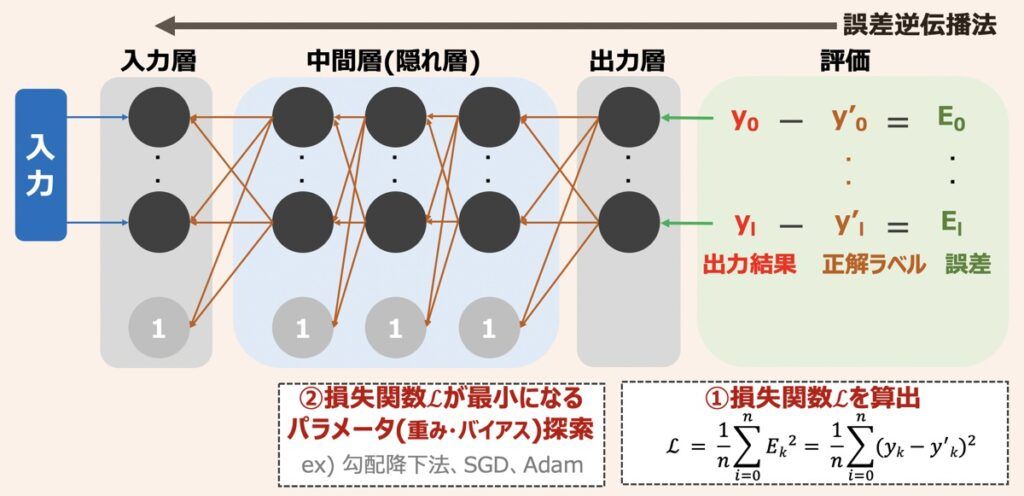
ニューラルネットワークの学習では、まず出力層から得られた出力結果が正解ラベルと比較され、出力結果と正解ラベルの差である誤差が算出されます。続いて、各出力結果から得られた誤差の総和(損失関数)を求めます。ニューラルネットワークではこの損失関数を最小化することが学習と位置付けられています。求められた損失関数の値をもとにパラメーター(重みやバイアス等)を更新していくのですが、その更新手段として損失関数の勾配が用いられ、損失関数の最小値を探索していくことになります。このような学習方法を「誤差逆伝播法」と言います。
ここで損失関数を最小化するための理論は下記で詳しく解説しています。
【ディープラーニング】損失関数とパラメータ探索アルゴリズム徹底解説|勾配降下法・学習率・局所最適解と大域最適解問題
ニューラルネットワーク最適化問題を扱う際に理解すべき損失関数(誤差)を最小化する仕組みとパラメータ探索アルゴリズムの役割について解説します。アルゴリズムは勾配降下法を題材としながら、最適化問題で考慮すべき学習率や局所解問題にも触れ、最後に多様な探索アルゴリズムを紹介します。
勾配消失問題とは
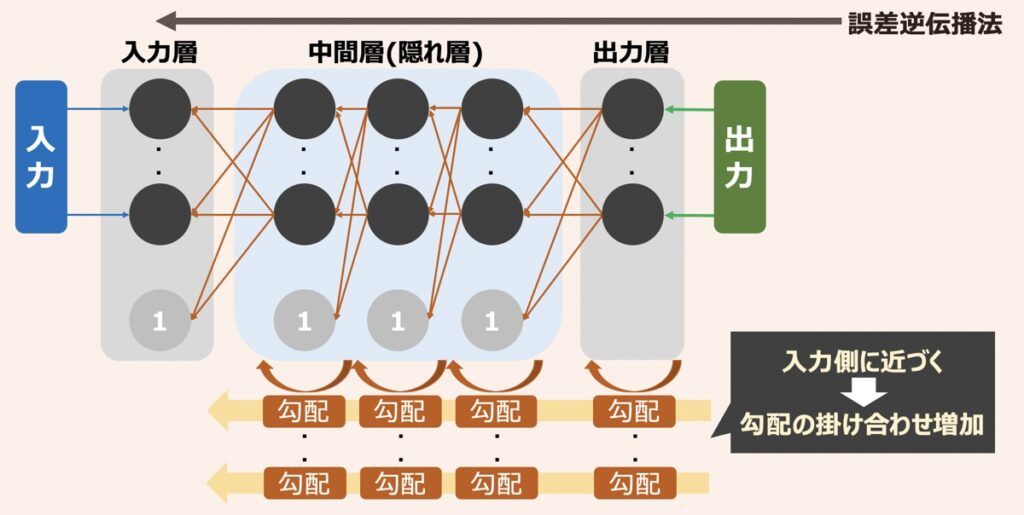
各層のパラメータを更新しながら誤差を最小化していくために勾配を用います。誤差伝播法において、勾配は上図のように伝播するイメージです。ここでポイントは出力側から入力側に近づくにつれて次々と勾配が掛け合わされていくという点です。
「勾配消失問題とは、各層の勾配で小さい値が続いた場合、入力側付近の勾配はゼロと見なされてしまい、学習がうまく進まなくなってしまう問題」のことを言います。
浅い層のニューラルネットワークを構築する上で、勾配消失問題が深刻になることはほとんどありません。一方で、何層も多層化されたニューラルネットワークを構築する際はこの問題への対応が必要です。
活性化関数による勾配消失対策

勾配消失問題を引き起こす原因の1つとして、活性化関数があります。例えばシグモイド関数を利用した場合、勾配[∂f(x)/∂x]を計算すると、最大値が0.25であると分かります。これを多層ニューラルネットワークに適用すると勾配消失が起こりやすいことを意味します。近年活性化関数には、ReLU関数を用いるのが一般的となっています。
その他勾配消失問題の対策として、「損失関数を最小化するためのパラメータ探索アルゴリズムの選択」や「XavierやHeの初期値を用いて重みを初期化する」等があります。上述のReLU関数を用いる際はHeの初期値を用いるのが好ましいと言われます。
【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
