
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- OpenAIが提供するGPTモデルについてそれぞれ特徴を知りたい。
- Pythonで最新のGPTモデル一覧を確認する方法が知りたい。
【OpenAI】ChatGPTとは?
ChatGPTとは、OpenAIが開発した対話型チャットボットのモデルです。ChatGPTの名前は、GPT-3という第3世代の生成言語モデルに由来しています。
ChatGPTのモデルには、人工知能(AI)が搭載されており、人間の発話に対して自然なやり取りを可能にしています。また、英語をはじめ、中国語、日本語、フランス語など複数言語を認識し、人間らしく応答できるのも特徴的です。
さらに、ChatGPTではチャットの他に、画像生成など近年多様な機能がリリースされてます。以下、ChatGPTで代表するGPTモデルおよびOpenAIが提供するAPI機能一覧を示します。
- チャット機能
- テキストから画像を生成
- オーディオを文字起こし
- Python、SQL、JavaScript等のコードを理解
- 問題あるネガティブ発言検出
- テキスト文章のベクトル変換
【参考】OpenAI社のAPI利用方法
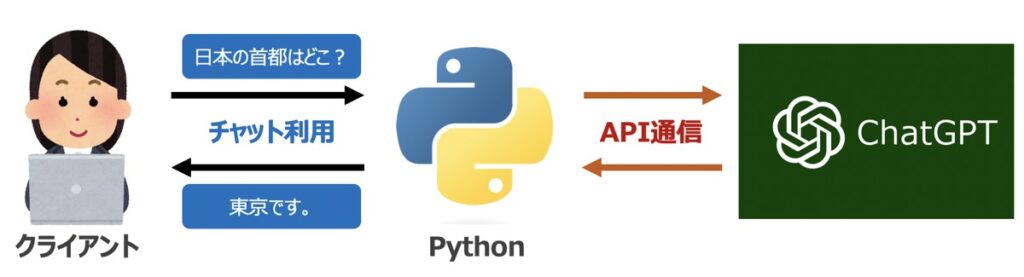
本記事ではChatGPTを用いたPythonプログラミングについて解説します。その際、Open AIが提供するAPI情報が必要になります。「ChatGPTの概要」および「API情報の取得手順」については、こちらの記事で詳しく解説しています。
【参考】ChatGPTを詳しく学びたい方向けの学習講座
ChatGPTを詳しく学びたい方向けに安価で学べるオンライン講座も併せてご紹介します。
【OpenAI】ChatGPTの言語モデルセット種類一覧
OpenAI API は、多様な機能と価格帯を備えたモデルがリリースされています。ChatGPTのモデルは、現在大きく分けて8つあります。以下、それぞれ特徴を確認しましょう。
| モデル種類 | 概要 |
|---|---|
| GPT-4 | GPT-3.5を改良し、自然言語、画像、コードを理解できる、マルチモーダルな大規模言語モデル |
| GPT-3.5 | GPT-3を改良し、自然言語やコードを理解できる大規模言語モデル |
| GPT-3 | 自然言語やコードを理解できる大規模言語モデル |
| DALL-E | 自然言語からデジタル画像を生成・編集できる深層学習モデル |
| Whisper | 音声をテキスト変換可能(Speech to Text)な深層学習モデル |
| Embedding | 埋め込み (ベクトル表現) を生成可能な深層学習モデル |
| Moderation | 誹謗中傷等のセンシティブで安全でない文章を検出できる深層学習モデル |
| Codex | コードの理解に特化した言語生成型の深層学習モデル |
以下、1つずつみていきましょう!
GPT-4
GPT-4(Generative Pre-trained Transformer 4)とは、OpenAIが開発したテキスト生成機能有するマルチモーダルな大規模言語モデルです。
GPT-3.5よりも幅広い一般知識を習得し、問題解決能力が改善されています。画像を読み取り、その内容を説明できる次世代のAI言語モデル(マルチモーダルモデル)という特徴があります。
GPT-4でできること
GPT-4では次のようなことが実現可能です。
- 画像入力して、その内容に紐づく文章を生成できる
- 最大25,000単語からなる文章を入力すると、その応答文が生成できる
GPT-4の代表モデル一覧
GPT-4では次のようなモデルが展開されています。
| 代表モデル | 概要 |
|---|---|
| gpt-4o | 高精度な自然言語処理能力を持ち、文脈理解や生成の質が向上したモデル。これにより、ユーザーとの対話がより自然でスムーズになり、さまざまなアプリケーションでの活用が期待されている。 |
| gpt-4o-mini | gpt-4oより精度は落ちるものの、処理速度が飛躍的に向上したモデル。 |
GPT-3.5
GPT-3.5(Generative Pre-trained Transformer 3.5)とは、OpenAIが開発したテキスト生成機能有する大規模言語モデルです。GPT-4の次に高性能なモデルです。
GPT-3.5の代表モデル一覧
GPT-3.5では次のようなモデルが展開されています。
| 代表モデル | 概要 |
|---|---|
| gpt-3.5-turbo | GPT-3.5において最も高性能なモデル。 コストは、text-davinci-003と比べて1/10も安価。 |
| text-davinci-003 | gpt-3.5-turboの次に高性能なモデル。 |
| text-davinci-002 | text-davinci-003と同様の機能を提供。言語学習の方法が、強化学習ではなく、教師ありファインチューニングを採用しているのが特徴。 |
【参考】PythonでGPT-3.5利用
PythonとOpenAIのAPIを用いてGPT-3.5モデルを利用する方法について、以下用途別に解説しています。
【参考】ChatGPTを詳しく学びたい方向けの学習講座
ChatGPTを詳しく学びたい方向けに安価で学べるオンライン講座も併せてご紹介します。
GPT-3
GPT-3は自然言語を理解して生成できる大規模言語モデルです。
現在では、より強力なGPT-3.5世代のモデルに取って代わられました。 現在、利用可能なモデルはオリジナルの GPT-3ベースモデル (davinci、curie、ada、babbage) です。
DALL-E
DALL-Eは、自然言語からデジタル画像を生成・編集する深層学習モデルです。
DALL-Eの代表モデル一覧
DALL-Eでは次のようなモデルが展開されています。
| 代表モデル | 概要 |
|---|---|
| DALL-E-3 | OpenAIが提供するAPIから利用できるDALL-Eの最新版。クリエイティブに富んだ解像度の高い画像を出力できる点が特徴。 |
【参考】PythonでDALL-E利用
PythonとOpenAIのAPIを用いてDALL-Eの画像生成モデルを実装する方法についても解説しています。

Whisper
Whisperとは、音声情報をテキスト情報に変換するSpeech to Textという機能を備えた深層学習モデルです。
Whisperは、Web上で収集された68万時間分の多言語音声データをもとに学習した音声認識モデルであり、高い精度で音声をテキスト変換することができます。
Whisperの代表モデル一覧
Whisperでは次のようなモデルが展開されています。
| 代表モデル | 概要 |
|---|---|
| whisper-1 | whisper-v2-largeモデルを現在APIを通じて、whisper-1というモデル名で利用が可能。多言語音声認識、音声翻訳、言語識別を実行できる。 |
【参考】PythonでWhisper利用
PythonとOpenAIのAPIを用いてWhisperモデルを利用する方法も解説しています。

Embedding
Embeddingとは、単語や文章等の自然言語の構成要素をベクトル表現に変換するモデルです。
Embeddingは複数の文章をベクトル変換することで、例えば2つの文章間の関連性を測定することができます。
Embeddingを応用することで、関連する文章の「検索」をはじめ、機械学習モデルタスクである「クラスタリング」「レコメンド」「異常検出」「分類」にも展開することができます。
Embeddingの代表モデル一覧
Embeddingでは次のようなモデルが展開されています。
| 代表モデル | 概要 |
|---|---|
| text-embedding-ada-002 | 現在推奨されている、Embeddingsモデルです。 |
PythonでEmbedding利用
PythonとOpenAIのAPIを用いてEmbeddingモデルを利用する方法も解説しています。

Moderation
Modelationとは、誹謗中傷やセクシャルコンテンツを含んだセンシティブで安全でない文章を検出できる深層学習モデルです。
Moderationに渡した入力テキストが、次に示すセンシティブなカテゴリに該当するか確認することができます。d
- hate
- hate/threatening
- self-harm
- sexual
- sexual/minors
- violence
- violence/graphic
Moderationの代表モデル一覧
Moderationでは次のようなモデルが展開されています。
| 代表モデル | 概要 |
|---|---|
| text-moderation-latest | 最も高性能なModelationモデル。text-moderation-stableと比較し、わずかに精度も高い。 |
| text-moderation-stable | text-moderation-latestとほぼ同等の能力を有したわずかに古いモデル。 |
PythonでModeration利用
PythonとOpenAIのAPIを用いてModerationモデルを利用する方法も解説しています。

Codex
Codexとは、コードの理解に特化した言語生成型の深層学習モデルです。GitHubの自然言語と数十億の公開コードを用いてトレーニングされています。
Codexは、Pythonコードの理解が最も得意とされており、その他にもJavaScript、Go、Perl、PHP、Ruby、Swift、TypeScript、SQL、Shellを含む12以上の言語に対しても堪能です。
Codexの代表モデル一覧
Codexでは、次のようなモデルが展開されています。
| Codex代表モデル | 概要 |
|---|---|
| code-davinci-002 | 最も高性能なCodexモデル。特に自然言語からコードへの変換を得意としている。コードの補完だけでなく、コード内への挿入も可能。 |
| code-davinci-001 | code-davinci-002より以前のモデル |
| code-cushman-002 | code-davinciの次に高性能であり、わずかに高速な処理が可能。この処理速度の利点は、リアルタイムなアプリケーションに適している。 |
【OpenAI】Pythonで最新のGPTモデル情報を一括取得する
ここまでOpenAIが提供するGPTモデル種類とそれぞれに対する代表モデルを紹介しました。これらのモデルが全てではなく、GPTモデルは日々最新モデルがアップデートされています。
最後にOpenAIが提供するAPIとPythonを用いて、その時点でのGPTモデル一覧を全て取得する方法について解説したいと思います。
Pythonライブラリ読込
はじめに、Pythonプログラムの先頭にライブラリとAPI認証情報を記述します。
Organization IDとシークレットキーもそれぞれ入力しましょう。
import pandas as pd
from datetime import datetime
from openai import OpenAI
API_Key = "<APIシークレットキーをここに入力>"最新のGPTモデル情報を全て取得
最新のGPTモデル情報を一括取得可能なコードを記述します。
# モデルリスト取得
client = OpenAI(api_key=API_Key)
model_list = client.models.list().data
model_num = len(model_list)
# リスト
created_at_list = [datetime.fromtimestamp(data.created) for data in model_list]
model_id_list = [data.id for data in model_list]
object_list = [data.object for data in model_list]
owned_by_list = [data.owned_by for data in model_list]
# データフレーム
df = pd.DataFrame({
"created": created_at_list,
"model_id": model_id_list,
"object": object_list,
"owned_by": owned_by_list,
})
# 並び替え
df = df.sort_values("作成日", ascending=False).reset_index(drop=True)
# Excelとして保存
df.to_excel("chatgpt-model-list.xlsx", index=False)こちらんコードを実行することで、後述の表に示すような結果が出力できます。
【参考】OpenAI リリース中の全GPTモデル一覧
最後に、OpenAIがリリース中のGPTモデル一覧を示します。
こちらの出力結果は前述のPythonプログラムを実行することで取得可能です。
| 作成日 | モデルID | オブジェクト名 | 所有 |
|---|---|---|---|
| 2023-11-11 07:53:21 | canary-whisper | model | system |
| 2023-11-09 10:22:15 | canary-tts | model | system |
| 2023-11-04 08:18:53 | tts-1-hd-1106 | model | system |
| 2023-11-04 08:14:01 | tts-1-1106 | model | system |
| 2023-11-04 06:13:35 | tts-1-hd | model | system |
| 2023-11-03 06:15:48 | gpt-3.5-turbo-1106 | model | system |
| 2023-11-03 05:33:26 | gpt-4-1106-preview | model | system |
| 2023-11-02 12:15:17 | gpt-4-vision-preview | model | system |
| 2023-11-01 09:22:57 | dall-e-2 | model | system |
| 2023-11-01 05:46:29 | dall-e-3 | model | system |
| 2023-09-08 06:34:32 | gpt-3.5-turbo-instruct-0914 | model | system |
| 2023-08-25 03:23:47 | gpt-3.5-turbo-instruct | model | system |
| 2023-08-22 01:16:55 | babbage-002 | model | system |
| 2023-08-22 01:11:41 | davinci-002 | model | system |
| 2023-06-28 01:13:31 | gpt-4 | model | openai |
| 2023-06-28 01:13:30 | gpt-4-0314 | model | openai |
| 2023-06-13 01:54:56 | gpt-4-0613 | model | openai |
| 2023-06-13 01:30:34 | gpt-3.5-turbo-0613 | model | openai |
| 2023-05-31 04:17:27 | gpt-3.5-turbo-16k-0613 | model | openai |
| 2023-05-11 07:35:02 | gpt-3.5-turbo-16k | model | openai-internal |
| 2023-04-20 06:49:11 | tts-1 | model | openai-internal |
| 2023-03-01 14:52:43 | gpt-3.5-turbo-0301 | model | openai |
| 2023-03-01 03:56:42 | gpt-3.5-turbo | model | openai |
| 2023-02-28 06:13:04 | whisper-1 | model | openai-internal |
| 2022-12-17 04:01:39 | text-embedding-ada-002 | model | openai-internal |
| 2022-11-28 10:40:35 | text-davinci-003 | model | openai-internal |
| 2022-04-29 04:01:50 | curie-similarity | model | openai-dev |
| 2022-04-29 04:01:50 | ada-code-search-text | model | openai-dev |
| 2022-04-29 04:01:50 | babbage-search-document | model | openai-dev |
| 2022-04-29 04:01:49 | text-search-curie-query-001 | model | openai-dev |
| 2022-04-29 04:01:49 | text-search-curie-doc-001 | model | openai-dev |
| 2022-04-29 04:01:49 | babbage-code-search-text | model | openai-dev |
| 2022-04-29 04:01:49 | text-search-babbage-doc-001 | model | openai-dev |
| 2022-04-29 04:01:49 | babbage-code-search-code | model | openai-dev |
| 2022-04-29 04:01:49 | davinci-search-document | model | openai-dev |
| 2022-04-29 04:01:49 | curie-search-query | model | openai-dev |
| 2022-04-29 04:01:49 | text-search-babbage-query-001 | model | openai-dev |
| 2022-04-29 04:01:49 | babbage-search-query | model | openai-dev |
| 2022-04-29 04:01:49 | davinci-similarity | model | openai-dev |
| 2022-04-29 04:01:48 | curie-search-document | model | openai-dev |
| 2022-04-29 04:01:47 | code-search-babbage-text-001 | model | openai-dev |
| 2022-04-29 04:01:47 | text-search-ada-doc-001 | model | openai-dev |
| 2022-04-29 04:01:47 | text-similarity-curie-001 | model | openai-dev |
| 2022-04-29 04:01:47 | code-search-ada-code-001 | model | openai-dev |
| 2022-04-29 04:01:47 | ada-similarity | model | openai-dev |
| 2022-04-29 04:01:47 | code-search-ada-text-001 | model | openai-dev |
| 2022-04-29 04:01:47 | code-search-babbage-code-001 | model | openai-dev |
| 2022-04-29 04:01:47 | ada-search-document | model | openai-dev |
| 2022-04-29 04:01:45 | davinci-search-query | model | openai-dev |
| 2022-04-29 04:01:45 | babbage-similarity | model | openai-dev |
| 2022-04-29 04:01:45 | text-similarity-davinci-001 | model | openai-dev |
| 2022-04-29 04:01:45 | text-search-davinci-query-001 | model | openai-dev |
| 2022-04-29 04:01:45 | ada-code-search-code | model | openai-dev |
| 2022-04-29 04:01:45 | text-similarity-babbage-001 | model | openai-dev |
| 2022-04-29 04:01:45 | text-search-davinci-doc-001 | model | openai-dev |
| 2022-04-29 04:01:45 | ada-search-query | model | openai-dev |
| 2022-04-29 04:01:45 | text-search-ada-query-001 | model | openai-dev |
| 2022-04-29 04:01:45 | text-similarity-ada-001 | model | openai-dev |
| 2022-04-14 05:08:04 | text-davinci-002 | model | openai |
| 2022-04-14 05:08:04 | code-davinci-edit-001 | model | openai |
| 2022-04-13 09:19:39 | text-davinci-edit-001 | model | openai |
| 2022-04-08 05:40:43 | text-curie-001 | model | openai |
| 2022-04-08 05:40:43 | text-babbage-001 | model | openai |
| 2022-04-08 05:40:42 | davinci-instruct-beta | model | openai |
| 2022-04-08 05:40:42 | curie-instruct-beta | model | openai |
| 2022-04-08 05:40:42 | text-ada-001 | model | openai |
| 2022-04-08 05:40:42 | text-davinci-001 | model | openai |
| 2022-04-08 04:31:14 | davinci | model | openai |
| 2022-04-08 04:31:14 | curie | model | openai |
| 2022-04-08 04:07:29 | babbage | model | openai |
| 2022-04-08 03:51:31 | ada | model | openai |
【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
