
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- OpenAI(ChatGPTサービス提供会社)が提供するAPIを用いて、誹謗中傷やセクシャルコンテンツ等の問題発言を検出するモデルをPythonで構築する方法が知りたい。
【OpenAI】ChatGPTとは?
ChatGPTとは、OpenAIが開発した対話型チャットボットのモデルです。ChatGPTの名前は、GPT-3という第3世代の生成言語モデルに由来しています。
ChatGPTのモデルには、人工知能(AI)が搭載されており、人間の発話に対して自然なやり取りを可能にしています。また、英語をはじめ、中国語、日本語、フランス語など複数言語を認識し、人間らしく応答できるのも特徴的です。
さらに、ChatGPTではチャットの他に、画像生成など近年多様な機能がリリースされてます。以下、ChatGPTで代表するGPTモデルおよびOpenAIが提供するAPI機能一覧を示します。
- チャット機能
- テキストから画像を生成
- オーディオを文字起こし
- Python、SQL、JavaScript等のコードを理解
- 問題あるネガティブ発言検出
- テキスト文章のベクトル変換
【参考】OpenAI社のAPI利用方法
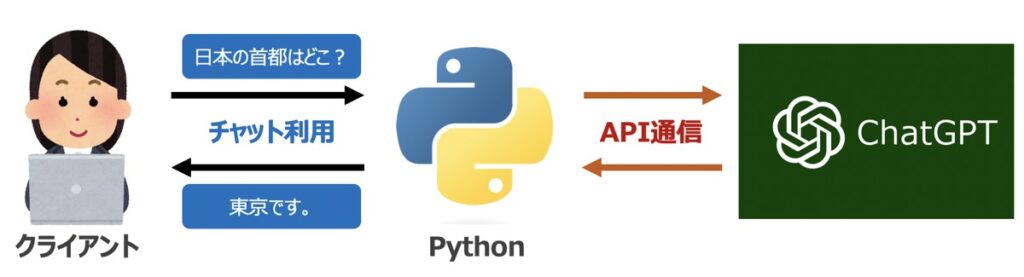
本記事ではChatGPTを用いたPythonプログラミングについて解説します。その際、Open AIが提供するAPI情報が必要になります。「ChatGPTの概要」および「API情報の取得手順」については、こちらの記事で詳しく解説しています。
【参考】ChatGPTを詳しく学びたい方向けの学習講座
ChatGPTを詳しく学びたい方向けに安価で学べるオンライン講座も併せてご紹介します。
【OpenAI】Moderationモデルとは?
Modelationとは、誹謗中傷やセクシャルコンテンツを含んだセンシティブで安全でない文章を検出できる深層学習モデルです。
Moderationに渡した入力テキストが、次に示すセンシティブなカテゴリに該当するか確認することができます。
- hate
- hate/threatening
- self-harm
- sexual
- sexual/minors
- violence
- violence/graphic
センシティブな発言であるかどうかは、OpenAI社のUsage Policiesに反していないかを基準に判定されます。
Moderationの代表モデル一覧
Moderationでは次のようなモデルが展開されています。
| 代表モデル | 概要 |
|---|---|
| text-moderation-latest | 最も高性能なModelationモデル。text-moderation-stableと比較し、わずかに精度も高い。 |
| text-moderation-stable | text-moderation-latestとほぼ同等の能力を有したわずかに古いモデル。 |
【Python × OpenAI】Moderationモデルの作成方法
実際にPythonとOpenAI社が提供するAPIを用いて問題発言を検知するModerationモデルを作成します。
【実践】Pythonライブラリ読込
Pythonプログラムの先頭にライブラリとAPI認証情報を記述します。
前述で紹介したOpenAIのサイトで取得できるシークレットキーを入力しましょう。
from openai import OpenAI
import pandas as pd
API_Key = "<APIシークレットキーをここに入力>"【実践】Moderationモデル作成
問題発言を検知するModerationモデルを実装します。以下のコードを記述しましょう。
# ======================================================================
# 関数作成
# ======================================================================
# テキスト内容変換
def text_henkan(text):
text = str(text).replace("True","該当").replace("False","-")
return text
# Moderationモデル
def moderation_inspect(text):
# クライアント
client = OpenAI(api_key = API_Key)
# moderation
moderation = client.moderations.create(
input = text, # 入力テキスト
)
# 結果カテゴリ
categories = moderation.results[0].categories
# データフレームに変換
df = pd.DataFrame({"嫌悪":text_henkan(categories.hate),
"険悪/脅迫":text_henkan(categories.hate_threatening),
"自傷":text_henkan(categories.self_minus_harm),
"セクシャル":text_henkan(categories.sexual),
"セクシャル/未成年者":text_henkan(categories.sexual_minors),
"暴力":text_henkan(categories.violence),
"暴力/グラフィック":text_henkan(categories.violence_graphic),
},
index=["表現内容"])
return df【実践】Moderationモデル実行
前述の関数を用いてModerationモデルを実行します。
コード
# ======================================================================
# 関数実行
# ======================================================================
# 入力テキスト
text = "I want to kill them"
# 関数実行
moderation_inspect(text)出力イメージ
入力テキストが以下の表現内容に該当する場合、「該当」と出力されます。
# 出力
print(moderation_inspect(text))
# 出力イメージ
# 嫌悪 険悪/脅迫 自傷 セクシャル セクシャル/未成年者 暴力 暴力/グラフィック
# 表現内容 - - - - - 該当 -【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
