
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
こんな方におすすめ!
- Pythonによるクロス集計表の作成手順を解説した記事です。
- クロス集計表作成メソッドや引数を駆使して、目的に応じた集計表が作成できるようになります。
目次
クロス集計表とは
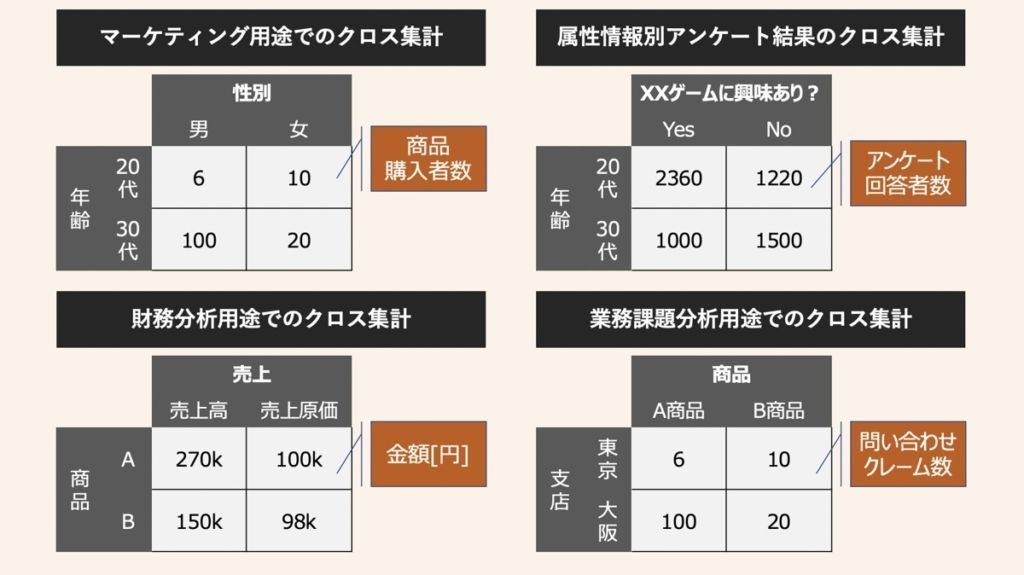
クロス集計とは異なる2つ以上の情報をかけ合わせて集計する方法です。上図のように、アンケート結果等のマーケティング用途に利用されたり、財務や業務に適用される等様々な側面で用いられています。
【Python実践】クロス集計表を作成
実際にPythonでクロス集計表を作成してみましょう。具体的に下記の手順でプログラミングしていきます。
- データ読込
- pandas.crosstab()メソッドでクロス集計表作成
- 引数を駆使して多様な目的に応じたクロス集計表作成
データ読込
クロス集計表を作成する上で必要なデータを読み込みます。今回はサンプルとして下記を記述してみましょう。
import pandas as pd
from io import StringIO
# クロス集計表を作成するためのデータ
csv_data = \
'''
名前 性別 年齢 出身 結婚
田中 女 20代 関東 未婚
佐藤 女 30代 関西 未婚
山田 男 30代 関西 既婚
高橋 男 40代 関東 未婚
田口 女 30代 関東 既婚
伊藤 女 30代 九州 既婚
大野 男 30代 関東 未婚
松永 男 40代 関東 既婚
入江 女 50代 九州 既婚
'''
# データフレーム
df = pd.read_table(StringIO(csv_data),sep='\s+')Pandas.crosstabメソッドでクロス集計表作成
クロス集計表はPandasライブラリのcrosstab()メソッドを用いて作成します。まずは、下記に示すような最小限必要な引数を指定し、集計表を作成してみましょう!
pandas.crosstab(index, columns)
# 第一引数:行の項目(index)
# 第二引数: 列の項目(columns)具体的なクロス集計表作成例を示します。
クロス集計|行「年齢」 vs 列「出身地」
pd.crosstab(df["年齢"], df["出身"])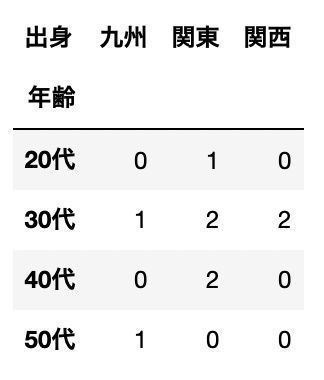
クロス集計|行「性別」 vs 列「出身」
pd.crosstab(df["性別"], df["出身"])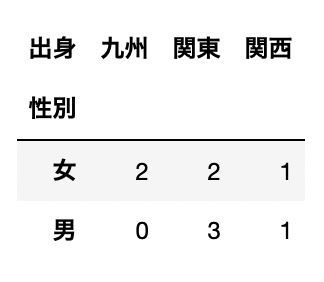
クロス集計|行「性別 × 年齢」 vs 列「出身」
pd.crosstab([df["性別"],df["年齢"]], df["出身"])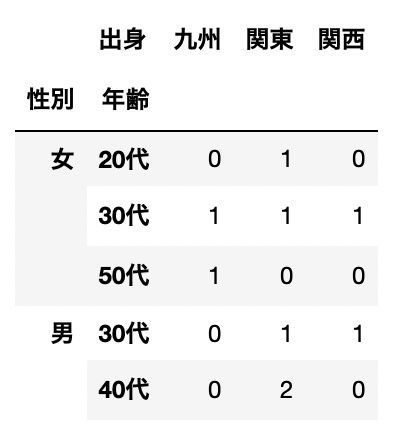
クロス集計|行「性別 × 年齢」 vs 列「出身 × 結婚」
pd.crosstab([df["性別"],df["年齢"]], [df["出身"], df["結婚"]])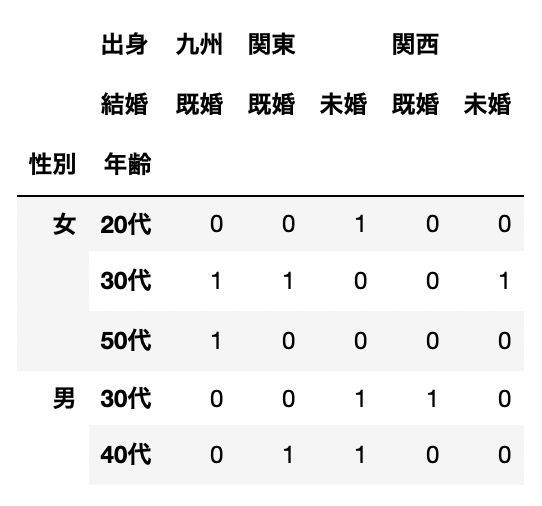
【Python実践】引数を駆使して目的に応じたクロス集計表を作成
続いてcrosstab()メソッドの引数を理解し、分析の目的に合わせてクロス集計表を加工できるようになりましょう。crosstab()メソッドに全ての引数を与えた場合、下記のように記述できます。
pandas.crosstab(index,
columns,
values=None,
rownames=None,
colnames=None,
aggfunc=None,
margins=False,
margins_name='All',
dropna=True,
normalize=False
)Pandas.crosstabメソッドの引数一覧
スクロールできます
| 引数名 | 概要 | デフォルト |
|---|---|---|
| index | 行の項目 | 必須 |
| columns | 列の項目 | 必須 |
| values | 関数(aggfunc)で処理する値 | None |
| rownames | 行の名前 | None |
| colnames | 列の名前 | None |
| aggfunc | 関数 | None |
| margins | 小計表示要否 | False |
| margins_name | 小計の名前 | “All” |
| dropna | 全ての値がnullの列の削除要否 | True |
| normalize | 最大1最小0での正規化要否 | False |
データの準備
前述で紹介した引数の中でよく使うものを用いてクロス集計表を加工してみます。引き続き作成に用いるデータとして下記を利用しますため、予め記述しておきましょう。
import pandas as pd
from io import StringIO
# クロス集計表を作成するためのデータ
csv_data = \
'''
名前 性別 年齢 出身 結婚
田中 女 20代 関東 未婚
佐藤 女 30代 関西 未婚
山田 男 30代 関西 既婚
高橋 男 40代 関東 未婚
田口 女 30代 関東 既婚
伊藤 女 30代 九州 既婚
大野 男 30代 関東 未婚
松永 男 40代 関東 既婚
入江 女 50代 九州 既婚
'''
# データフレーム
df = pd.read_table(StringIO(csv_data),sep='\s+')クロス集計|小計(margins)を指定
pd.crosstab(df["年齢"], df["出身"], margins=True, margins_name="小計")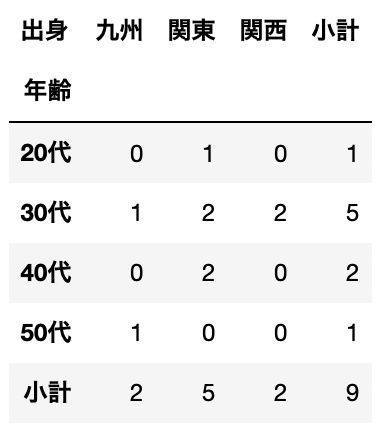
クロス集計|正規化処理を指定(normalize=True:総計が1になるよう正規化)
pd.crosstab(df["年齢"], df["出身"], normalize=True, margins=True, margins_name="小計")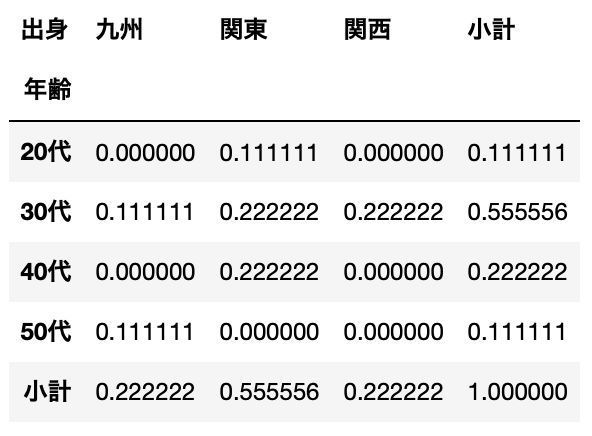
クロス集計|正規化処理を指定(normalize=”index”:行の小計が1になるよう正規化)
pd.crosstab(df["年齢"], df["出身"], normalize="index", margins=True)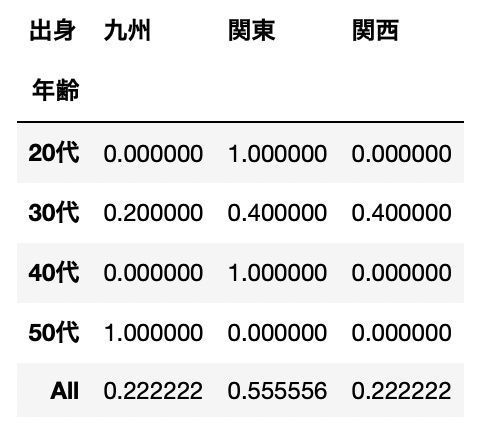
クロス集計|正規化処理を指定(normalize=”columns”:列の小計が1になるよう正規化)
pd.crosstab(df["年齢"], df["出身"], normalize="columns", margins=True)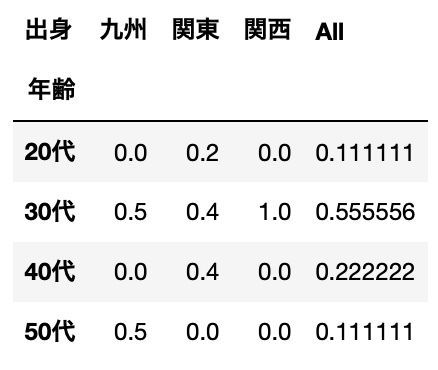
【参考】Pythonでのデータ前処理・分析・可視化
当サイトではPythonを用いた「データ前処理手法」「データ分析」「グラフや表を用いた可視化」手法について幅広く解説しております。AI・機械学習にも応用できる内容となっておりますため、興味がある方は併せてご確認下さい。
Pythonを活用したデータ処理・分析手法一覧



【参考】Pythonとは・できること一覧
Pythonでできること・副業案件の探し方
「Pythonで実現できるお役立ち情報」を多数配信中!Python習熟者向けに「おすすめのPython副業・フリーランス案件の探し方」についてもご紹介してます。
最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
