
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- 機械学習の教師なし学習について知りたい!
- 階層的クラスタリングの概要とPythonを用いたプログラミング手法が知りたい!
クラスタリングとは
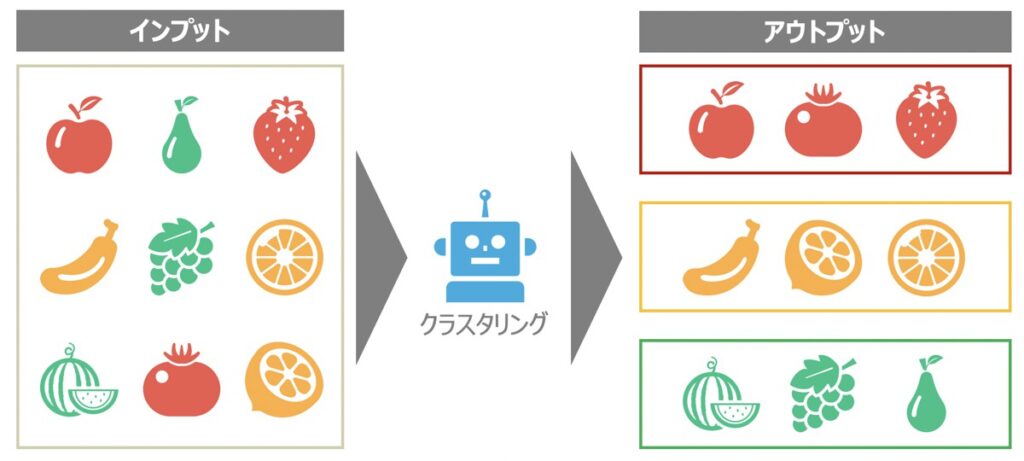
クラスタリングとは、機械学習の教師なし学習に該当するもので、類似するサンプルデータを部分集合(クラスター)として分割することを指します。
データから隠れた構造を見つけ出すことに役立つクラスタリングは、マーケティング活動におけるセグメント分析やレコメンドエンジンのアルゴリズム等に広く利用されています。
【参考】教師なし学習

教師あり学習とは、「正解」の用意されたデータをもとに学習が行われるアルゴリズムを指します。一方、教師なし学習は「正解」データを与えずに行うアルゴリズムであり、代表的なものにクラスタリングが該当します。
教師なし学習のアルゴリズムに大量のデータを与えると、アルゴリズム自身がデータを探索し、データの構造やパターンを抽出・分類してくれるのが特徴的です。
クラスタリングの用途例
- 様々な映画・音楽・書籍を同じグループにまとめる
- 趣味・嗜好が同じ顧客別にグループ分けする
階層的クラスタリング(Hierarchical Clustering)とは
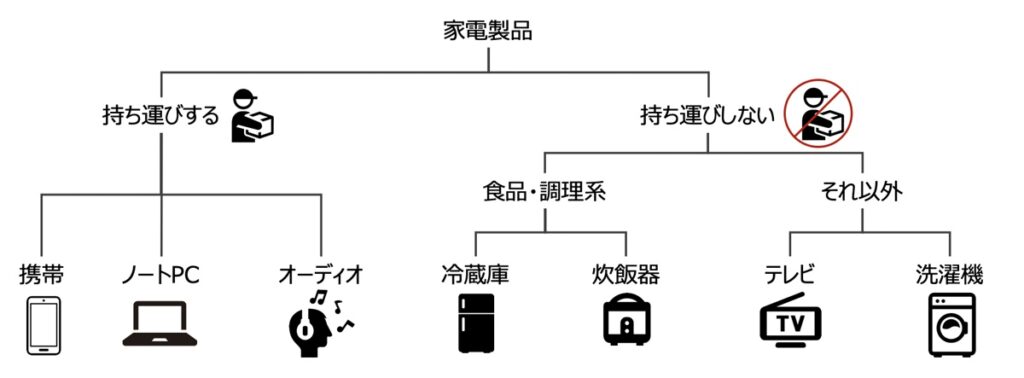
階層的クラスタリングとは、最も類似する(または最も類似しない)サンプルデータの組み合わせを見つけ出し、順番にグループ分けしていく手法です。
階層的クラスタリングのアルゴリズムのメリットとして、樹形図(デンドログラム)をプロットできることがあります。樹形図とは二分木で階層的クラスタリングを可視化したものであり、サンプルデータの直感的理解に役立ちます。
階層的クラスタリングの種類
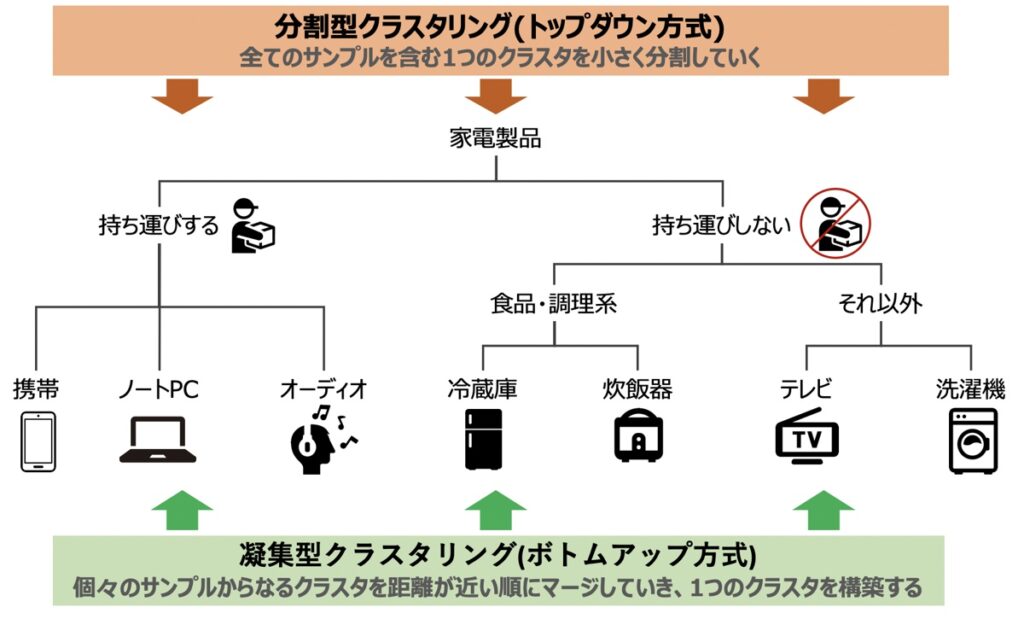
階層クラスタリングには、「分散型」と「凝集型」の2種類の手法があります。
それぞれの特徴を見てみましょう。
| 分散型 | ・トップダウン方式 ・はじめに全てのサンプルを含む1つのクラスタを定義し、最も類似しないサンプルの組み合わせから順により細かなクラスタへ分割していく |
|---|---|
| 凝集型 | ・ボトムアップ方式 ・個々のサンプルを1つのクラスターとして捉え、最も類似するサンプルの組み合わせから順に、より大きなクラスターになるよう連結していく |
階層的クラスタリングの原理・実行手順
階層的クラスタリングでは実際にどのような計算方法でサンプルがグループ分けされていくのでしょうか?
以下階層的クラスタリングの凝集型を例とし、実行手順を見ていきましょう!
- 各サンプルを単一のクラスターとみなし、全てのクラスター間のユークリッド距離を計算
- クラスター間の距離に基づき、クラスターを連結
- クラスター情報を更新し、ユークリッド距離を再計算
- クラスターが最終的に1つになるまで(2)(3)を繰り返す
ユークリッド距離に基づくクラスター間距離の計算
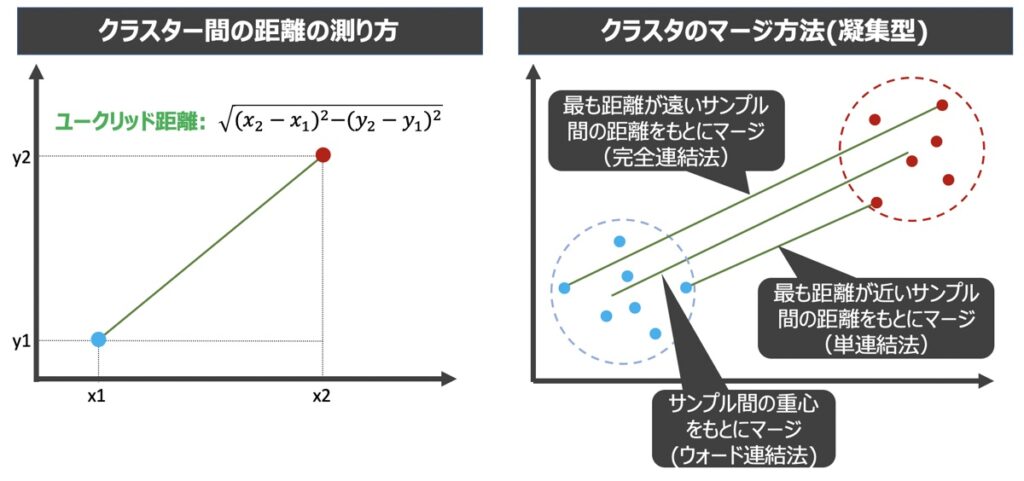
クラスター間の距離は、ユークリッド距離の計算手法に基づき算出されます(上図左)。距離計算に用いるサンプル2点の座標は、クラスターの連結法によって異なります(上図右)。
【参考】クラスター連結方法
クラスターの連結法として代表的な4つの手法を以下紹介します。
| 連結法 | 概要 | メリット | デメリット |
|---|---|---|---|
| 単連結法 | 最も近いサンプル同士の距離をクラスタ間の距離として採用しクラスタ同士を連結 | 計算負荷が小さい | 分類精度は外れ値の影響を受ける |
| 完全連結法 | 最も遠いサンプル同士の距離をクラスタ間の距離として採用しクラスタ同士を連結 | 計算負荷が小さい | 分類精度は外れ値の影響を受ける |
| ウォード連結法 | クラスタ内誤差平方和の合計の増加量が最小となるクラスタ同士を連結 | 分類精度は外れ値・データのばらつきによる影響を受けづらい | 他の連結法と比べて計算負荷が大きい |
| 平均連結法 | 2つのクラスタに含まれるサンプルすべての組み合わせにおいて距離を計算し、その最小距離の平均をもとにクラスタ同士を連結 | 分類精度は外れ値・データのばらつきによる影響を受けづらい | 他の連結法と比べて計算負荷が大きい |
【参考】樹形図作成の流れ
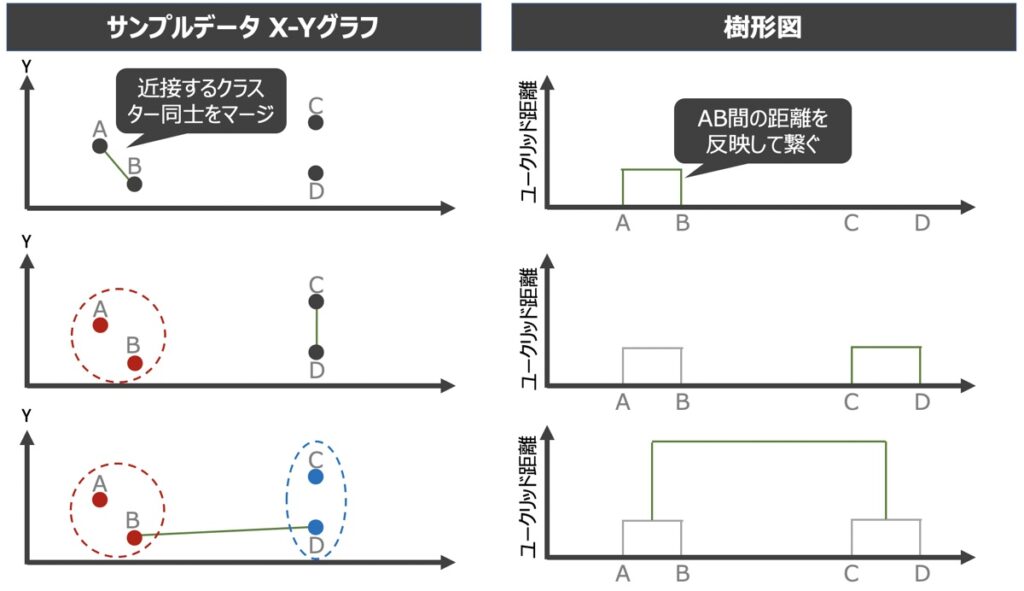
階層クラスタリング実行過程において、樹形図は上図の流れで作成されていきます。クラスターが最終的に1つになると、樹形図が完成と言えます。
【Python】階層クラスタリングによるモデル構築実践
階層クラスタリングの実行にあたり、ここからは実際にコード記載方法を紹介します。今回の例では、凝集型のクラスタリングを採用します。
クラスタリングモデル構築手順
クラスタリングモデルの構築は下記の手順で実施します。
- データの準備・理解
- 最適なクラスターの数を見つけるための樹形図の作成
- クラスター数の決定・モデル学習
- クラスター可視化
データの準備・理解
本記事では「顧客属性別の居住マンション価格に関するデータセット」を用いており、顧客の年収とマンションにかかる費用で顧客をグループ分けすることします。下記のコードを事前に実行しておきましょう。
サンプルデータ
コード
import numpy as np
import pandas as pd
df = pd.read_csv("sample_data.csv")
print(df.tail())csvファイル出力結果例
| 性別 | 年齢 | 職業 | 年収[万円] | マンション費用[万/月] |
|---|---|---|---|---|
| 男 | 32 | 商社 | 700 | 12 |
| 女 | 26 | 公務員 | 350 | 4 |
最適なクラスターの数を見つけるための樹形図の作成
続いてクラスタリングのモデル構築に先駆け、最適なクラスター数を調査します。先程読み込んだデータセットをもとに樹形図を描いてみましょう!下記を記述します。
コード
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# クラスタリング軸設定(年収vsマンション費用)
X = df.iloc[:, [3, 4]].values
# 樹形図作成用インスタンス
dendrogram = sch.dendrogram(sch.linkage(X, method = 'ward'))
# 樹形図可視化
plt.title('Dendrogram')
plt.xlabel('Salary vs Apartment Cost')
plt.ylabel('Euclidean distances')
plt.show()出力結果
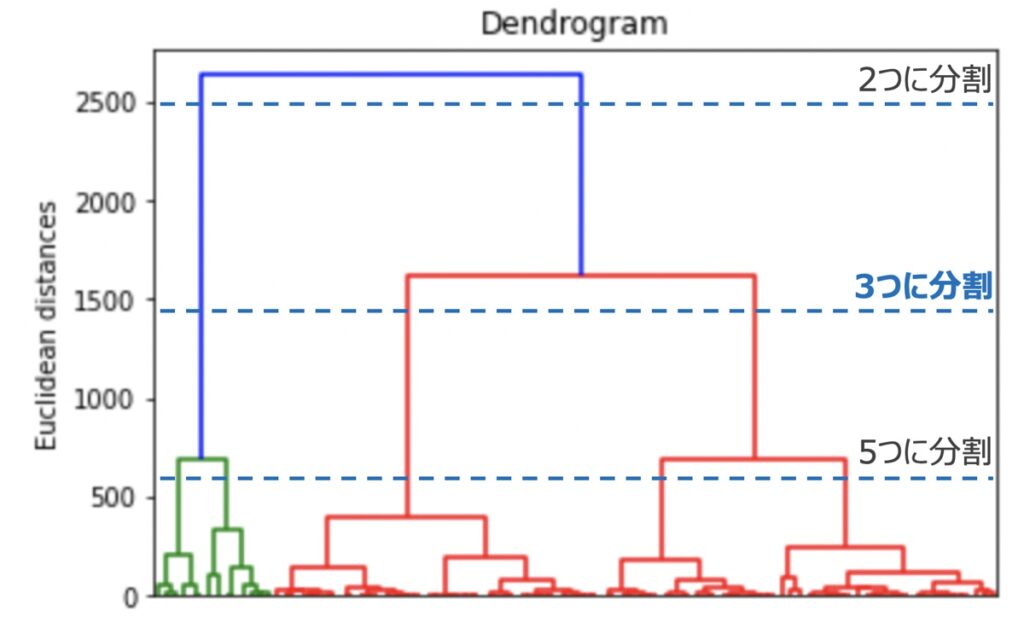
上記コードを実行すると上図の樹形図が得られます。scipy.cluster.hierarchyクラスからインスタンスを生成することで、樹形図を作成しました。ここでインスタンス内のlinkage()メソッドとはデータ間の距離を計算し繋がりを作る役割を有します。今回は連結方法としてウォード連結法を渡して距離計算するために、method=”ward”としています。
import scipy.cluster.hierarchy as sch
# 樹形図作成用インスタンス
dendrogram = sch.dendrogram(sch.linkage(X, method = 'ward'))樹形図を観察すると、今回のサンプルデータの場合は3つのクラスターで分割するのが良いと推察できます。そのため、下記で実施するモデル学習はクラスター数=3と指定することとします。
モデル学習
scikit-learnのAgglomerativeClusteringクラスを用いてクラスタリングモデルを構築します。
コード
from sklearn.cluster import AgglomerativeClustering
# モデル訓練
hir_clus = AgglomerativeClustering(n_clusters = 3, # クラスター数
metric = 'euclidean', # 距離のパラメーター
linkage = 'ward', # クラスター連結法(ward|complete|average|single)
)
y_hir_clus = hir_clus.fit_predict(X)階層クラスタリングに用いる引数一覧
ここでモデル構築のために第一引数にクラスター数((n_clusters)、第二引数に距離のパラメーター(affinity)、第三引数にクラスター連結法(linkage)を指定しました。
| 引数 | 概要 | デフォルト値 |
|---|---|---|
| n_clustersint | クラスター数 | 2 |
| metric | 距離のパラメーター | ‘euclidean’ |
| linkage | クラスター連結法(ward|complete|average|single) | ‘ward’ |
| distance_thresholdfloat | 距離の閾値(指定した閾値を超過した場合、クラスターは連結しない) | None |
モデル学習によって予測されたクラスター結果は、下記を実行すると確認できます。
print(y_hir_clus)
# 出力結果
# array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 2, 2, 2, 2, 2, 2, 2, 2,
# 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0,2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
# 2, 2, 2, 1, 2, 2, 1,1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])クラスター可視化
最後に構築したクラスタリングモデルを用いてクラスターを可視化します。下記を記載しましょう。
コード
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
# クラスターの配列情報
cluster_labels = np.unique(y_hir_clus) # 一意なクラスター要素
n_clusters = cluster_labels.shape[0] # 配列の長さ
# 可視化
for i in range(len(cluster_labels)):
color = cm.jet(float(i) / n_clusters)
plt.scatter(X[y_hir_clus == i, 0],
X[y_hir_clus == i, 1],
s = 50,
color = color,
label = 'Cluster'+str(i)
)
plt.title('Clusters of customers')
plt.xlabel('Salary')
plt.ylabel('Apartment Cost')
plt.legend(loc="best")
plt.show()出力結果
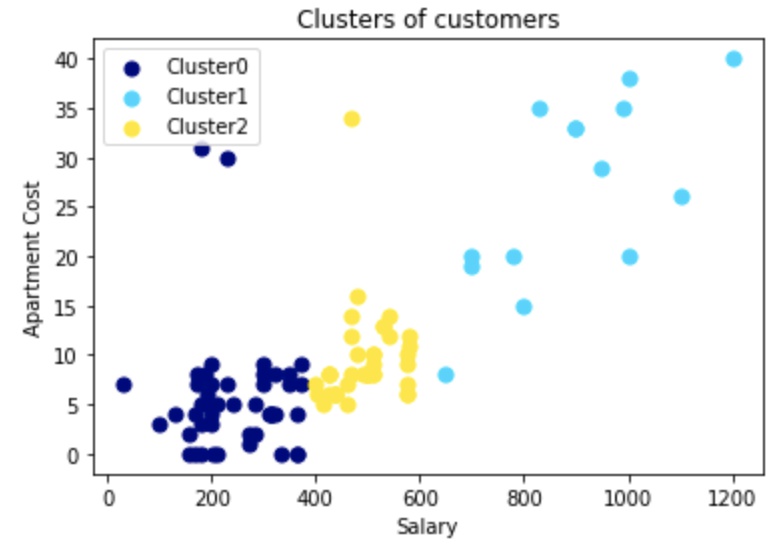
【参考】クラスター分析の学習におすすめの教材
最後までご覧いただきありがとうございました。クラスタリングは教師なし学習の代表的手法であり、データにある隠れた規則性を見出すのに非常に有効な手法です。
以下本日の学習ポイントまとめです。
最後に、Pythonを用いたクラスター分析についてもっと学習したい方向けにおすすめ教材を紹介します。興味のある方は是非ご覧下さい。


【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
