
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- 特徴量スケーリング(Feature Scaling)について詳しく知りたい!
- Pythonで特徴量スケーリングを実施する方法が知りたい!
【機械学習】特徴量スケーリング(Feature Scaling)とは
特徴量のスケーリングとは、機械学習モデルを構築する上で広く用いられるデータの前処理手法であり、「特徴量が取りうる値の範囲を変える・異なる特徴量同士の尺度を統一すること」を意味します。
特徴量スケーリングの重要性
機械学習モデルを構築する上で特徴量のスケーリングは実施した方が良い場合としなくても良い場合があります。その見分け方は「特徴量の尺度の違いが機械学習アルゴリズムに影響を与えるかどうか」で判断できます。
下記の概念図をもとにイメージを掴んでみましょう。
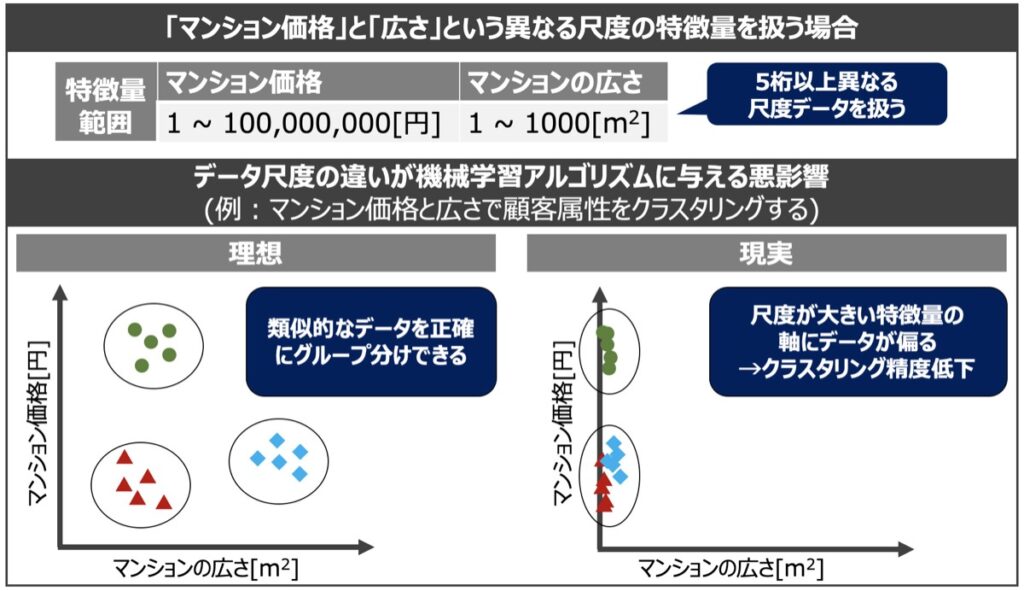
上図では教師なし学習であるクラスタリングを例に挙げています。概念的な例ですが、図の理想・現実を比較すると特徴量の尺度の違いによって異なるグループ分けになっていることが分かります。
クラスタリングや教師あり学習のk近傍方(KNN)・勾配降下法のように、データ間で計算された距離がアルゴリズムに適用される手法は、特徴量スケーリングを実施した前と後で学習モデルの精度改善が期待できるため、特徴量スケーリングが重要と言えるのです。
一方で、決定木やランダムフォレストといった機械学習アルゴリズムのように、特徴量の尺度の違いが学習モデルに影響を及ぼさないものは、Feature Scalingが不要と言えます。
特徴量スケーリングの代表的手法
代表的な手法として下記があります。以下1つずつ特徴を見ていきましょう!
- 正規化(normalization)
- 標準化(standardization)
正規化(Normalization)
正規化とは特徴量を最小値0, 最大値1の範囲に変換することを意味します。
特定の特徴量を正規化する際、下記の計算を実行します。この方法はmin-maxスケーリングとも呼ばれます。
- : i番目の変数
- : 正規化された変数
- :の最小値
- :の最大値
標準化(Standardization)
標準化とは特徴量の平均値を0、標準偏差を1となるように変換することを意味します。
計算方法は下記のように示されます。
- : i番目の変数
- : 標準化された変数
- :の平均値
- :の標準偏差
【データの前処理】正規化と標準化の使い分け
多くの機械学習アルゴリズムに対して特徴量スケーリングを適用する場合、標準化を行う方が実用的と言われています。理由は標準化の場合、外れ値に関する有益情報を保持できるためです。
正規化の場合は、最大・最小値をもとにスケーリングするため、外れ値の影響によって偏ったスケーリングになることがあります。そのため正規化は、最大値及び最小値が決まっている場合によく利用されます。
標準化と正規化の違いを視覚的に理解するためには下記の表が役立ちます。簡易な0~5の数値からなるサンプルデータをスケーリングした結果を示しています。
| サンプルデータ | 正規化 | 標準化 |
|---|---|---|
| 0.00 | 0.00 | -1.46 |
| 1.00 | 0.20 | -0.88 |
| 2.00 | 0.40 | -0.29 |
| 3.00 | 0.60 | 0.29 |
| 4.00 | 0.80 | 0.88 |
| 5.00 | 1.00 | 1.46 |
【Python】scikit-learnによる特徴量スケーリング(Feature Scaling)
実際にscikit-learnを用いてPythonプログラミングを実行します。下記アプローチに従って実行することとします。
- データセットを準備
- 正規化・標準化
データセットを準備
データセットの例として下記を活用します。地域・性別・年齢・貯金額という属性情報によって、投資経験に特徴が表れるかを示したものです。適時コードを実行してみましょう。
コード
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from io import StringIO
# データセットを準備
csv_data = \
'''
Region,Sex,Age,Deposit,Investment
Tokyo,Male,21,200000,No
Osaka,Female,25,2400000,No
Tokyo,Female,30,3200000,Yes
Fukuoka,Male,46,4600000,No
Osaka,Male,57,6500000,Yes
Osaka,Female,60,12000000,Yes
Fukuoka,Male,44,8000000,No
Saitama,Female,18,100000,No
'''
df = pd.read_csv(StringIO(csv_data))
print(df)初期データイメージ
| Region (地域) |
Sex (性別) |
Age (年齢) |
Savings (貯金額[円]) |
Investment (投資経験) |
|
|---|---|---|---|---|---|
| 0 | Tokyo | Male | 21 | 200000 | No |
| 1 | Osaka | Female | 25 | 2400000 | No |
| 2 | Tokyo | Female | 30 | 3200000 | Yes |
| 3 | Fukuoka | Male | 46 | 4600000 | No |
| 4 | Osaka | Male | 57 | 6500000 | Yes |
| 5 | Osaka | Female | 60 | 12000000 | Yes |
| 6 | Fukuoka | Male | 44 | 8000000 | No |
| 7 | Saitama | Female | 18 | 100000 | No |
特徴量の正規化
特徴量(Age・Savings)をmin-maxスケーリングした場合を示します。下記のように記述してみましょう。
コード
# min-maxスケーリング
from sklearn.preprocessing import MinMaxScaler
# インスタンス
minmax_sc = MinMaxScaler()
# AgeとSavingsを正規化
X = df.loc[:, 'Age':'Savings']
# 演算・データ変換
X = minmax_sc.fit_transform(X)
# 正規化後のデータ出力
df_norm = df.copy()
df_norm.loc[:, 'Age':'Savings'] = X
print(df_norm)正規化後出力イメージ
| Region (地域) |
Sex (性別) |
Age (年齢) |
Savings (貯金額[円]) |
Investment (投資経験) |
|
|---|---|---|---|---|---|
| 0 | Tokyo | Male | 0.07 | 0.01 | No |
| 1 | Osaka | Female | 1.67 | 0.19 | No |
| 2 | Tokyo | Female | 0.29 | 0.26 | Yes |
| 3 | Fukuoka | Male | 0.67 | 0.37 | No |
| 4 | Osaka | Male | 0.92 | 0.53 | Yes |
| 5 | Osaka | Female | 1.00 | 1.00 | Yes |
| 6 | Fukuoka | Male | 0.62 | 0.66 | No |
| 7 | Saitama | Female | 0.00 | 0.00 | No |
上記コード個別解説
min-maxスケーリングは、scikit-learnライブラリに実装されているMinMaxScalerクラスを用い、下記のようにインスタンスを生成して実行します。
# min-maxスケーリング
from sklearn.preprocessing import MinMaxScaler
# インスタンス
minmax_sc = MinMaxScaler()インスタンス生成後、fit_transform()関数に特徴量を渡して正規化します。
# AgeとSavingsを正規化
X = df.loc[:, 'Age':'Savings']
X = minmax_sc.fit_transform(X)ここでfit_transform()関数とは、特徴量をスケーリングするために必要な統計情報を計算するfit()関数と、fit()関数で計算した結果をもとにデータ変換(正規化)するtransform()関数が一体となったものです。
特徴量の標準化
特徴量(Age・Savings)を標準化した場合を示します。下記のようにコードを記述してみましょう。
コード
from sklearn.preprocessing import StandardScaler
# インスタンス (平均=0, 標準偏差=1)
standard_sc = StandardScaler()
# AgeとSavingsを標準化
X = df.loc[:, 'Age':'Savings']
X = standard_sc.fit_transform(X)
# 標準化後のデータ出力
df_std = df.copy()
df_std.loc[:, 'Age':'Savings'] = X
print(df_std)標準化後出力イメージ
| Region (地域) |
Sex (性別) |
Age (年齢) |
Savings (貯金額[円]) |
Investment (投資経験) |
|
|---|---|---|---|---|---|
| 0 | Tokyo | Male | -1.08 | -1.16 | No |
| 1 | Osaka | Female | -0.83 | -0.58 | No |
| 2 | Tokyo | Female | -0.50 | -0.37 | Yes |
| 3 | Fukuoka | Male | -0.55 | -0.01 | No |
| 4 | Osaka | Male | 1.27 | 0.49 | Yes |
| 5 | Osaka | Female | 1.47 | 1.93 | Yes |
| 6 | Fukuoka | Male | 0.42 | 0.89 | No |
| 7 | Saitama | Female | -1.29 | -1.19 | No |
上記コード個別解説
標準化には、scikit-learnのStandardScaler()クラスを用い、下記のインスタンスを生成して実行しています。
from sklearn.preprocessing import StandardScaler
# インスタンス
standard_sc = StandardScaler()【参考】Pythonでのデータ前処理・分析・可視化
当サイトではPythonを用いた「データ前処理手法」「データ分析」「グラフや表を用いた可視化」手法について幅広く解説しております。AI・機械学習にも応用できる内容となっておりますため、興味がある方は併せてご確認下さい。
Pythonを活用したデータ処理・分析手法一覧



【参考】Pythonとは・できること一覧
最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
