
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- カテゴリー変数のエンコーディングについて詳しく知りたい。
- ワンホットエンコーディングとラベルエンコーディングをPythonで実行する方法が知りたい。
【機械学習基礎】カテゴリー変数とは
カテゴリー変数とは、身長や年齢のように数値で表せる変数ではなく、グループ・属性(色・国など)を分類する用途で示される変数を指します。
また、カテゴリー変数は「名義変数」と「順序変数」で分けることができます。
| 変数名 | 概要 | 事例 |
|---|---|---|
| 数値変数 | 数値で構成された変数 | ・身長 ・年齢 |
| 名義変数 | 並び替えや順序付けができないカテゴリー変数 | ・色(赤、青、緑) ・国(日本、アメリカ、中国) |
| 順序変数 | 並び替えや順序付けが可能なカテゴリー変数 | ・Tシャツのサイズ(S、M、L) |
【機械学習基礎】エンコーディングとは
機械学習アルゴリズムにカテゴリー変数を正しく解釈させ、精度の高い学習モデルを構築するには、事前にカテゴリー変数の値を数値に変換することが求められます。その処理過程をエンコーディングといいます。
順序変数のエンコーディング
以下各カテゴリ変数の処理について解説します。まず、順序変数の場合は単純な大小関係を整数値で示すように変換します。
| 順序変数(例) | 項目値 | 項目値(エンコーディング) |
|---|---|---|
| Tシャツのサイズ | S,M,L | S→0、M→1、L→2 |
| ご飯の量 | 並盛り、大盛り | 並盛り→0、大盛り→1 |
| 学校 | 小学校、中学校、高校 | 小学校→0、中学校→1 、高校→2 |
名義変数のエンコーディング
一方で、順序や並び替えの概念がない名義変数はどのように数値化処理するのでしょうか?
ポイントは「名義変数は順序変数と同じ規則で数値変換しないこと」です。
例えば、カラー(色)という値は順序を持たないが、「黒→0、赤→1」のように数値変換すると、機械学習アルゴリズムは赤が黒より大きいと解釈するのです。このような間違った解釈はモデル精度の低下を引き起こす原因となってしまいます。
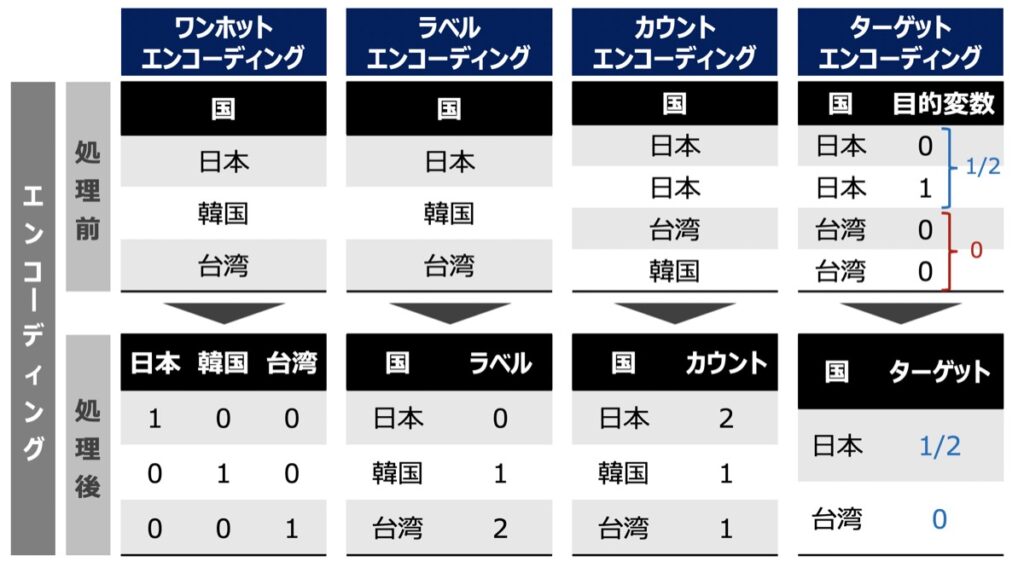
名義変数を正しく数値化して機械学習アルゴリズムに適応するには、下記のようなエンコーディング手法を用います。以下それぞれのエンコーディング手法の特徴とイメージを示します。
名義変数のエンコーディング種類一覧
| エンコーディング手法 | 概要 |
|---|---|
| ワンホット表現 | ・「列の名前」=「カテゴリ名」と指定した新規の列を作成 ・列名とカテゴリ項目値が一致した行は「1」それ以外は「0」を割り当てる |
| ラベル表現 | ・各カテゴリー項目値に対して一つの数字を割り当て ・最も単純な手法 |
| カウント表現 | ・カテゴリー項目値の登場回数を割り当てる |
| ターゲット表現 | ・カテゴリ項目値別に目的変数の平均値を計算し、その結果をカテゴリ項目値に割り当てる |
エンコーディング処理イメージ
【Python実践】カテゴリー変数のエンコーディング
ここからは実際のPythonコーディング例も用いて、カテゴリーデータのエンコーディング手法を解説します。
エンコーディングは代表的なラベルエンコーディングおよびワンホットエンコーディングを取り扱います。
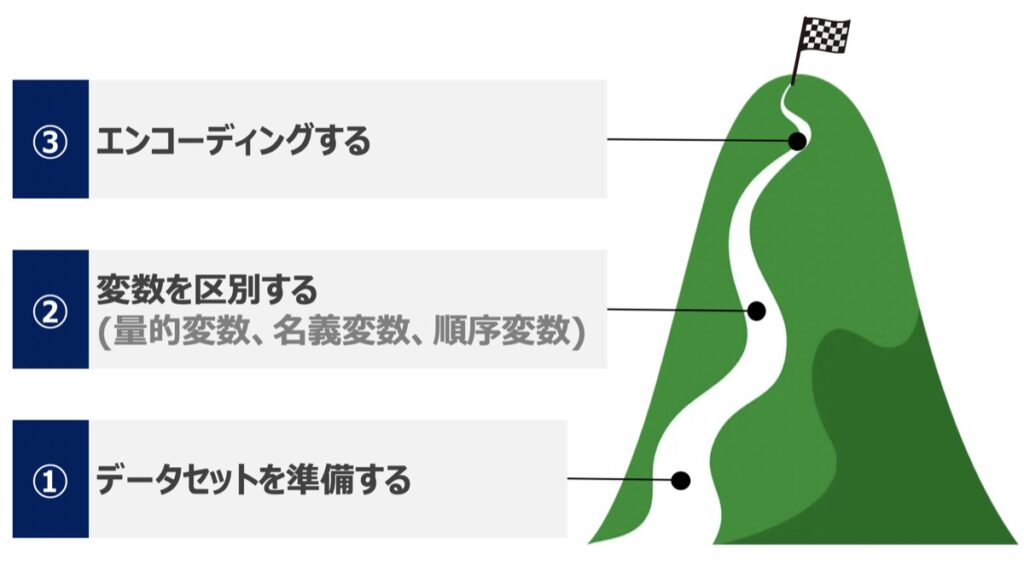
データセットを準備する
はじめに、Python実行環境上にデータを準備します。今回は地域・性別・年齢・貯金額に基づき、投資経験に特徴が表れるかを示したデータセットを用意します。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from io import StringIO
# データセットを準備
csv_data = \
'''
Region,Sex,Age,Deposit,Investment
Tokyo,Male,21,200000,No
Osaka,Female,25,2400000,No
Tokyo,Female,30,3200000,Yes
Fukuoka,Male,46,4600000,No
Osaka,Male,57,6500000,Yes
Osaka,Female,60,12000000,Yes
Fukuoka,Male,44,8000000,No
Saitama,Female,18,100000,No
'''
df = pd.read_csv(StringIO(csv_data))
print(df)| Region (地域) |
Sex (性別) |
Age (年齢) |
Savings (貯金額[円]) |
Investment (投資経験) |
|
|---|---|---|---|---|---|
| 0 | Tokyo | Male | 21 | 200000 | No |
| 1 | Osaka | Female | 25 | 2400000 | No |
| 2 | Tokyo | Female | 30 | 3200000 | Yes |
| 3 | Fukuoka | Male | 46 | 4600000 | No |
| 4 | Osaka | Male | 57 | 6500000 | Yes |
| 5 | Osaka | Female | 60 | 12000000 | Yes |
| 6 | Fukuoka | Male | 44 | 8000000 | No |
| 7 | Saitama | Female | 18 | 100000 | No |
変数を区別する
変数に応じてどのような処理が最適か判断するために、変数をグループ分けします。今回のデータ例では下記のように分類できます。
- 数値変数:Age(年齢)、Savings(貯金額)
- 名義変数:Region(地域)、Sex(性別)、Investment(投資経験)
- 順序変数:なし
今回は名義変数に該当するカテゴリー変数に対してエンコーディングを適用します。
【Python実践】エンコーディング(Encoding)
前述で用意したデータを用いてワンホットエンコーディングおよびラベルエンコーディングを実践する方法を解説します。
ワンホットエンコーディング(One Hot Encoding)|ダミー変数の作成
One Hot エンコーディングでは、名義変数が持つ一意な値ごとにダミー変数として列を生成することを意味します。
以下Region(地域)にOne Hot エンコーディングを適用するコードとその処理結果を示します。
コード
# Pandasのget_dummies()関数を利用
Region = pd.get_dummies(df["Region"])
print(Region)エンコーディング処理結果
ワンホットエンディーング処理前
| Region(地域) | |
|---|---|
| 0 | Tokyo |
| 1 | Osaka |
| 2 | Tokyo |
| 3 | Fukuoka |
| 4 | Osaka |
| 5 | Osaka |
| 6 | Fukuoka |
| 7 | Saitama |
ワンホットエンコーディング処理後
| Fukuoka | Osaka | Saitama | Tokyo | |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 1 | 0 | 0 |
| 2 | 0 | 0 | 0 | 1 |
| 3 | 1 | 0 | 0 | 0 |
| 4 | 0 | 1 | 0 | 0 |
| 5 | 0 | 1 | 0 | 0 |
| 6 | 1 | 0 | 0 | 0 |
| 7 | 0 | 0 | 1 | 0 |
上記の場合、Fukuoka、Osaka、 Saitama、Tokyoという4つの新しいダミー変数の列が生成されました。
このように新たな4つの変数の組み合わせによってRegion(地域)を特定できるようする変換処理こそOne Hot エンコーディングの特徴と言えます。
ワンホットエンコーディング(One Hot Encoding)|多重共線性の対応
One Hotエンコーディングを適用する場合、「多重共線性」という問題に注意する必要があります。
多重共線性とは学習モデルに用いる説明変数同士で相関係数が高い場合、数値的に不安定な予測を引き起こしてしまうことを指します。(学習モデルの逆行列の計算に基づくものであり今回詳細は割愛します。)
多重共線性を回避するためには「One Hotエンコーディングで生成した列を1つ削除する」だけで良いです。今回の例だと、Fukuoka=0, Osaka=0, Saitama=0と観測された場合、Region(地域)は必然的にTokyoと判断できるため、ダミー変数を1つ削除したところでRegion(地域)の情報が消失することはありません。
get_dummyies()関数を使用する場合、drop_first=Trueとして引数を渡すと、最初の列を削除できます。
コード
Region = pd.get_dummies(df["Region"],drop_first=True)
print(Region)出力結果
| Osaka | Saitama | Tokyo | |
|---|---|---|---|
| 0 | 0 | 0 | 1 |
| 1 | 1 | 0 | 0 |
| 2 | 0 | 0 | 1 |
| 3 | 0 | 0 | 0 |
| 4 | 1 | 0 | 0 |
| 5 | 1 | 0 | 0 |
| 6 | 0 | 0 | 0 |
| 7 | 0 | 1 | 0 |
ワンホットエンコーディング(One Hot Encoding)|scikit-learnによる処理
One Hotエンコーディングは、scikit-learnのpreprocessingモジュールに実装されたOneHotEncoderクラスを用いて実行することもできます。その場合下記のように実行します。
コード
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
# ワンホットエンコーディングのインスタンス生成
OE = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [0])], remainder='passthrough')
# データ変換
df1_values = np.array(OE.fit_transform(df.iloc[:,:].values))
print(df1_values) 出力結果
# 出力結果
# array([[0.0, 0.0, 0.0, 1.0, 'Male', 21, 200000, 'No'],
# [0.0, 1.0, 0.0, 0.0, 'Female', 25, 2400000, 'No'],
# [0.0, 0.0, 0.0, 1.0, 'Female', 30, 3200000, 'Yes'],
# [1.0, 0.0, 0.0, 0.0, 'Male', 46, 4600000, 'No'],
# [0.0, 1.0, 0.0, 0.0, 'Male', 57, 6500000, 'Yes'],
# [0.0, 1.0, 0.0, 0.0, 'Female', 60, 12000000, 'Yes'],
# [1.0, 0.0, 0.0, 0.0, 'Male', 44, 8000000, 'No'],
# [0.0, 0.0, 1.0, 0.0, 'Female', 18, 100000, 'No']], dtype=object)エンコーディングのインスタンスは下記のように記述しました。引数は[エンコードする列番号]とremainder=’passthrough’を渡します。reminderとは数値変換を対象としない列の処理を指定するものです。原則’passthrough’と記載することで変換しない列はそのままの状態を保持するようにします。
# ワンホットエンコーディングのインスタンス生成
OE = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [エンコードする列番号])], remainder='passthrough')データの変換(エンコーディングを適用)するには、演算処理に担当するfit関数()とデータ変換処理を担当するtransform()関数を用います。今回はそれら要素を兼ね備えたfit_transform()関数を用いてデータ変換しています。
# データ変換
df1_values = np.array(OE.fit_transform(df.iloc[:,:].values))ラベルエンコーディング(Label Encoding)|scikit-learnによる処理
続いてLabelエンコーディングについて解説します。カテゴリ変数の項目数に応じて連番を渡すデータ変換方法であり、One hotエンコーディングと異なり、新しく生成される変数は1つのみで良い特徴があります。今回はSex(性別)にLabelエンコーディングを適用します。
コード
from sklearn.preprocessing import LabelEncoder
# インスタンス
LE = LabelEncoder()
# Label エンコーディング
LE.fit_transform(df["Sex"].values)
# データ変換
df["Sex_Encoding"] = LE.fit_transform(df["Sex"].values)
print(df)出力結果
ラベルエンコーディング前
| Sex(性別) | |
|---|---|
| 0 | Male |
| 1 | Female |
| 2 | Female |
| 3 | Male |
| 4 | Male |
| 5 | Female |
| 6 | Male |
| 7 | Female |
ラベルエンコーディング後
| Sex(性別) | Sex_Encoding | |
|---|---|---|
| 0 | Male | 1 |
| 1 | Female | 0 |
| 2 | Female | 0 |
| 3 | Male | 1 |
| 4 | Male | 1 |
| 5 | Female | 0 |
| 6 | Male | 1 |
| 7 | Female | 0 |
【Python】エンコーディング用の全量コード
最後に本日学習したエンコーディング手法をもとに、データ処理したコードの全量と出力結果を示します。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from io import StringIO
from sklearn.preprocessing import LabelEncoder
"""
1. データセットを準備
"""
csv_data = \
'''
Region,Sex,Age,Savings,Investment
Tokyo,Male,21,200000,No
Osaka,Female,25,2400000,No
Tokyo,Female,30,3200000,Yes
Fukuoka,Male,46,4600000,No
Osaka,Male,57,6500000,Yes
Osaka,Female,60,12000000,Yes
Fukuoka,Male,44,8000000,No
Saitama,Female,18,100000,No
'''
df = pd.read_csv(StringIO(csv_data))
"""
2. One Hot Encoding
"""
# One Hot Encoding
Region = pd.get_dummies(df["Region"],drop_first=True)
# Regionの列削除
df1= df.drop(["Region"],axis=1)
# DataFramae 結合&新規生成
df1 = pd.concat([Region,df1],axis=1)
"""
3. Label Encoding
"""
df2 = df1.copy()
# Label Encoding: Sex(性別)
LE1 = LabelEncoder()
LE1.fit_transform(df1["Sex"].values)
df2["Sex"] = LE1.fit_transform(df1["Sex"].values)
# Label Encoding: Investment(投資経験)
LE2 = LabelEncoder()
LE2.fit_transform(df1["Investment"].values)
df2["Investment"] = LE2.fit_transform(df1["Investment"].values)【参考】Pythonでのデータ前処理・分析・可視化
当サイトではPythonを用いた「データ前処理手法」「データ分析」「グラフや表を用いた可視化」手法について幅広く解説しております。AI・機械学習にも応用できる内容となっておりますため、興味がある方は併せてご確認下さい。
Pythonを活用したデータ処理・分析手法一覧



【参考】Pythonとは・できること一覧
最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
