
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- Python経由でSnowflake上に外部データをロードしたい
- PythonのPandas DataFrameを変換し、Snowflakeのテーブルに取り込むためのプログラミング方法が知りたい
Snowflake(スノーフレーク)とは

Snowflakeとは、クラウド上で動作するSaas型のデータウェアハウスです。Snowflakeをもとにサイロ化されたデータを一元管理でき、データアクセス性とデータ利活用の双方を効率化することができます。
Snowflakeには次のような特徴があります。
1. クラウドネイティブ
Snowflakeは、クラウド上で動作するデータクラウドです。
Amazon Web Services(AWS)、Microsoft Azure、Google Cloud Platform(GCP)のいずれかのクラウドプロバイダーにホストされています。
2. マルチクラウド
Snowflakeは、AWS、Azure、GCPのいずれかのクラウドプラットフォームでホストされているため、ユーザーは自身のビジネスニーズに応じて異なるプラットフォームが選択可能です。
3. ストレージとコンピューティングの分離
Snowflakeは、ストレージとコンピューティングを分離しています。これにより、必要に応じてストレージとコンピューティングのリソースを独立して拡張できます。
4. ユーザー管理
Snowflakeは、ロールベースのアクセス制御を提供しています。
データ利用のユースケースや会社の部門・チーム単位でのアクセス管理も可能です。
5. パフォーマンス
Snowflakeは、高速かつスケーラブルなパフォーマンスを提供しています。ストレージとコンピューティングの分離により、必要に応じてリソースを拡張できます。そのため、データ処理能力とコストというトレードオフな関係も考慮し、状況に応じたパフォーマンスの最適化も可能です。
6. データセキュリティ
Snowflake上のデータは暗号化され、セキュリティの高い状態で保管されています。
また、指定のユーザー・ロールがのみデータアクセス可能とする機能やデータマスキング機能などセキュリティ対策に特化した機能も多数提供されています。
【参考】Snowflakeの学習におすすめの教材

Sowflakeについて詳しく学びたい方向けに、おすすめの学習講座をご紹介します。現時点で英語版が多いもののUdemyでは多数の優良教材が用意されています。
【Snowflake】Pythonワークシート経由でテーブルにレコード追加
次に示す手順に従い、SnowflakeのPythonワークシートからSnowflakeで定義されたテーブルにレコードを追加します。以下、1つずつ見ていきましょう!
- 【参考】データセットの説明
- 【事前準備】SQLワークシートを開き、データベース・スキーマ・テーブルを作成
- 【事前準備】Anaconda Pythonパッケージの有効化
- 【事前準備】Pythonワークシートを開き、スクリプト実行設定を定義
- 【実践】Pythonワークシートを開き、テーブルにレコードを追加
- 【実践】SQLワークシートを開き、正常にレコードが追加された確認
データセットの説明

データセットには、機械学習のサンプルデータとして有名なIris(アヤメ)データセットを活用します。3種類のアヤメ(Iris Setosa, Iris Versicolor, Iris Virginica)があり、それぞれ50サンプルずつ(合計150サンプル)用意されているデータです。このアヤメの名前を目的変数として利用します。また、説明変数にはアヤメの計測値である萼片(sepals)と花びら(petals)の長さと幅の4つを利用します。
【事前準備】SQLワークシートを開き、データベース・スキーマ・テーブルを作成
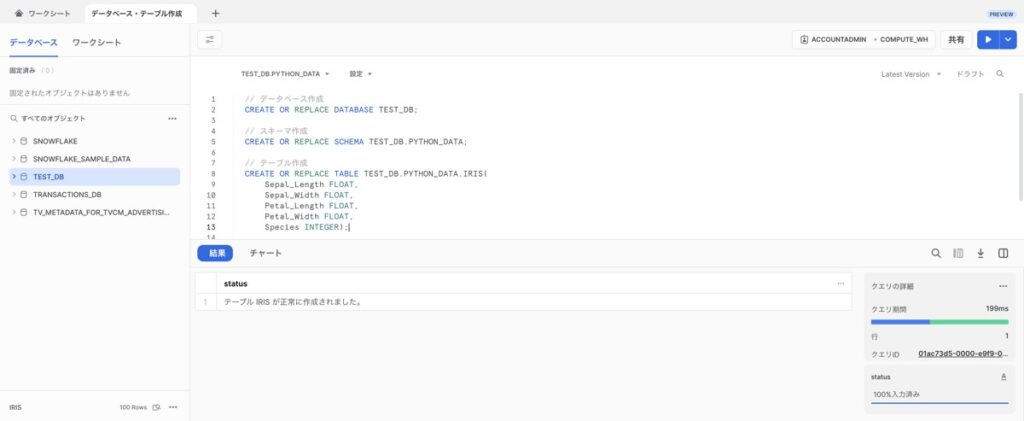
前述に示したアヤメのデータを格納するためのデータベースおよびテーブルをSnowflake上に作成します。
SQLワークシートを開き、以下のコードを実行しましょう。今回の例では、データベースTEST_DBのスキーマPYTHON_DATAにあるテーブルIRISにレコードを追加することとします。
// データベース作成
CREATE OR REPLACE DATABASE TEST_DB;
// スキーマ作成
CREATE OR REPLACE SCHEMA TEST_DB.PYTHON_DATA;
// テーブル作成
CREATE OR REPLACE TABLE TEST_DB.PYTHON_DATA.IRIS(
Sepal_Length FLOAT,
Sepal_Width FLOAT,
Petal_Length FLOAT,
Petal_Width FLOAT,
Species INTEGER
);【事前準備】Anaconda Pythonパッケージの有効化
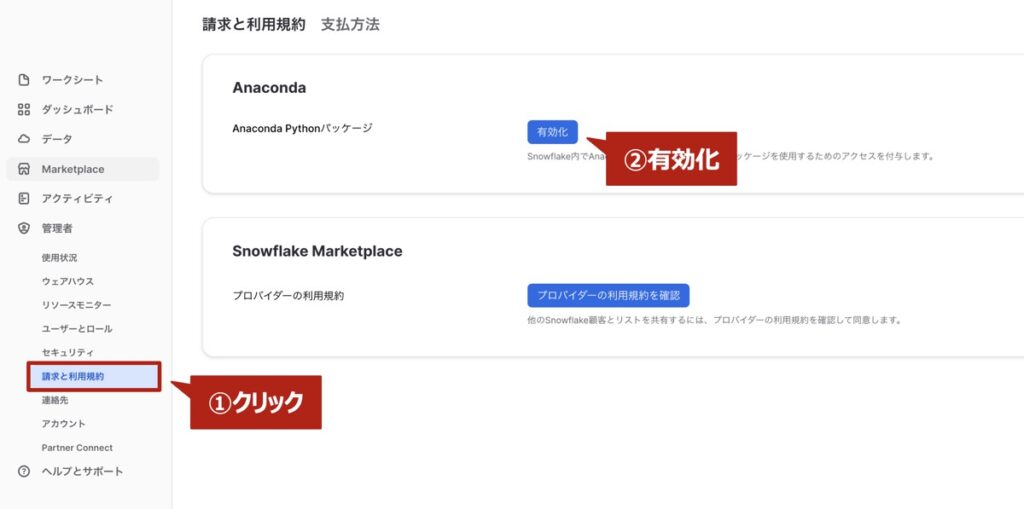
Pythonワークシート経由でSnowflakeのデータベースにレコードを追加する場合、Python外部ライブラリを使用することがあります。
その中でAnacondaが提供する外部ライブラリは、Snowflake画面の「管理者 > 請求と利用規約」タグを開き、「Anaconda Pythonパッケージ」を有効化することで利用できるようになります。
【事前準備】Pythonワークシートを開き、スクリプト実行設定を定義
ここからPythonコードを記述するワークシートを開いて中身を編集していきます。Pythonワークシート上ではじめにすべきは、以下3つになります。それぞれ対応しましょう。
【設定①】データベース・スキーマの指定
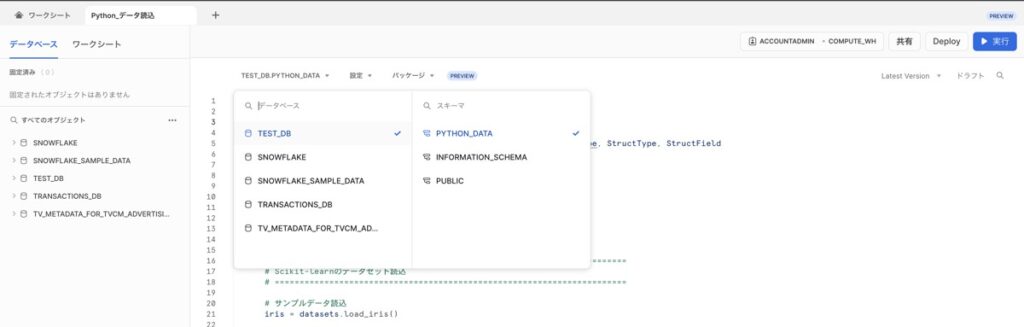
前述のSQLワークシートで作成したデータベース・スキーマを指定します。
【設定②】ハンドラー・ReturnTypeの指定
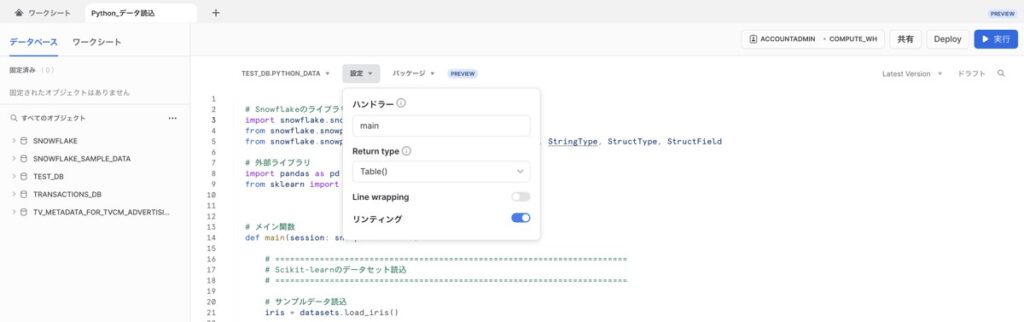
Pythonワークシートの▶︎実行ボタンを押下した時に、実行される関数をハンドラーに指定します。今回はデフォルトのmainのままで問題なしです。また、関数の戻り値のデータ型をTable()に指定しましょう。
【設定③】パッケージの追加指定
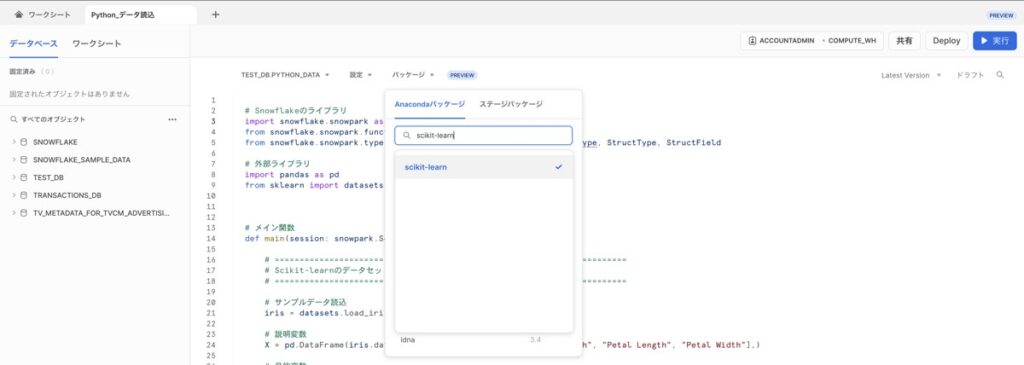
今回はPythonライブラリのscikit-learnを用いてサンプルデータを用意し、Snowflakeのテーブルに対して追加することとします。そのため、パッケージ検索画面でscikit-learnにはチェックを入れておきましょう。
【実践】Pythonワークシートを開き、テーブルにレコードを追加
前述のPythonスクリプト実行設定を定義したワークシートに対して、次のようなコードを入力し、Snowflakeのテーブルにレコードを追加することとします。
コード
# Snowflakeのライブラリ
import snowflake.snowpark as snowpark
from snowflake.snowpark.functions import col
from snowflake.snowpark.types import IntegerType, FloatType, StringType, StructType, StructField
# 外部ライブラリ
import pandas as pd
from sklearn import datasets
# メイン関数
def main(session: snowpark.Session):
# =======================================================================
# Scikit-learnのデータセット読込
# =======================================================================
# サンプルデータ読込
iris = datasets.load_iris()
# 説明変数
X = pd.DataFrame(iris.data, columns=["Sepal Length", "Sepal Width", "Petal Length", "Petal Width"],)
# 目的変数
Y = pd.DataFrame(iris.target, columns=["Species"])
# 上記結合
df_pandas = pd.concat([X,Y],axis=1)
# =======================================================================
# Snowflakeのデータフレームに変換
# =======================================================================
# スキーマ作成
schema = StructType([StructField("Sepal_Length", FloatType()),
StructField("Sepal_Width", FloatType()),
StructField("Petal_Length", FloatType()),
StructField("Petal_Width", FloatType()),
StructField("Species", IntegerType()),
])
# データフレーム(Snowflake)
df_snowflake = session.create_dataframe(df_pandas.values.tolist()[0:100], # 説明変数
schema, # フィールド名
)
# =======================================================================
# データベースにレコード追加
# =======================================================================
df_snowflake.write.mode("overwrite").save_as_table("TEST_DB.PYTHON_DATA.IRIS")
return df_snowflakeコードの詳細解説
Scikit-learnのデータセット読込
今回の例では、scikit-learnのアヤメデータセットを読み込むコードを記述しています。
加えて、df_pandasというPandasのデータフレーム形式でデータを用意しています。
# =======================================================================
# Scikit-learnのデータセット読込
# =======================================================================
# サンプルデータ読込
iris = datasets.load_iris()
# 説明変数
X = pd.DataFrame(iris.data, columns=["Sepal Length", "Sepal Width", "Petal Length", "Petal Width"],)
# 目的変数
Y = pd.DataFrame(iris.target, columns=["Species"])
# 上記結合
df_pandas = pd.concat([X,Y],axis=1)今回の例ではscikit-learnで取得したデータを利用しましたが、APIやスクレイピング等の用途が決まっている場合、そちらのデータ取得方法に変更すると良いでしょう。
Snowflakeのデータフレームに変換(スキーマ作成)
Pandas形式のデータフレームをSnowflakeで扱えるようにするために、各種フィールドのデータ型をスキーマとして定義します。
スキーマはsnowflake.snowpark.typesに用意されたメソッドを用いて定義可能です。
# =======================================================================
# Snowflakeのデータフレームに変換
# =======================================================================
# スキーマ作成
schema = StructType([StructField("Sepal_Length", FloatType()),
StructField("Sepal_Width", FloatType()),
StructField("Petal_Length", FloatType()),
StructField("Petal_Width", FloatType()),
StructField("Species", IntegerType()),
])Snowflakeのデータフレームに変換(PandasデータフレームをSnowflake形式に変換)
Snowflakeで取り扱い可能なデータフレームは、次のように変換処理しています。
session.create_dataframe()メソッドの第一引数にリスト型のデータ群、例えば[[1,2,3,4],[5,6,7,8],[9,10,11,12]]のような形式でデータを指定します。第二引数にはフィールドのデータ型を定義したスキーマを指定します。
# =======================================================================
# Snowflakeのデータフレームに変換
# =======================================================================
# データフレーム(Snowflake)
df_snowflake = session.create_dataframe(df_pandas.values.tolist(), # 説明変数
schema, # フィールド名
)データベースにレコード追加
既存のSnowflakeテーブルへのレコード追加は、次のコードをもとに実行しています。
save_as_table("<テーブル名>")に対象のテーブルを指定するのがポイントです。
# =======================================================================
# データベースにレコード追加
# =======================================================================
df_snowflake.write.mode("overwrite").save_as_table("TEST_DB.PYTHON_DATA.IRIS")出力イメージ
処理が正常に動作した場合、次のような出力結果が確認できます。
# SEPAL_LENGTH SEPAL_WIDTH PETAL_LENGTH PETAL_WIDTH SPECIES
# 5.1 3.5 1.4 0.2 0
# 4.9 3 1.4 0.2 0
# 4.7 3.2 1.3 0.2 1
# 4.6 3.1 1.5 0.2 1【実践】SQLワークシートを開き、正常にレコードが追加された確認
最後に、Pythonワークシートから追加したレコードが正常に反映されているか、SQLワークシート上からも確認しておきます。SQLワークシートを開き、以下のコードを実行しましょう。
コード
// テーブル参照
SELECT * FROM TEST_DB.PYTHON_DATA.IRIS;出力イメージ
処理が正常に動作した場合、次のような出力結果が確認できます。
# SEPAL_LENGTH SEPAL_WIDTH PETAL_LENGTH PETAL_WIDTH SPECIES
# 5.1 3.5 1.4 0.2 0
# 4.9 3 1.4 0.2 0
# 4.7 3.2 1.3 0.2 1
# 4.6 3.1 1.5 0.2 1【参考】Pythonでのデータ前処理・分析・可視化
当サイトではPythonを用いた「データ前処理手法」「データ分析」「グラフや表を用いた可視化」手法について幅広く解説しております。AI・機械学習にも応用できる内容となっておりますため、興味がある方は併せてご確認下さい。
Pythonを活用したデータ処理・分析手法一覧



【参考】Pythonとは・できること一覧
最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
