
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- Pythonで音声ファイルを文字起こしできる機能(Speech-To-Text)を開発したい。
- 会議メモや議事録の作成をもっと効率的したい。
- ChatGPTのWhisper API の利用に興味がある。
【OpenAI】ChatGPTとは?
ChatGPTとは、OpenAIが開発した対話型チャットボットのモデルです。ChatGPTの名前は、GPT-3という第3世代の生成言語モデルに由来しています。
ChatGPTのモデルには、人工知能(AI)が搭載されており、人間の発話に対して自然なやり取りを可能にしています。また、英語をはじめ、中国語、日本語、フランス語など複数言語を認識し、人間らしく応答できるのも特徴的です。
さらに、ChatGPTではチャットの他に、画像生成など近年多様な機能がリリースされてます。以下、ChatGPTで代表するGPTモデルおよびOpenAIが提供するAPI機能一覧を示します。
- チャット機能
- テキストから画像を生成
- オーディオを文字起こし
- Python、SQL、JavaScript等のコードを理解
- 問題あるネガティブ発言検出
- テキスト文章のベクトル変換
【参考】OpenAI社のAPI利用方法
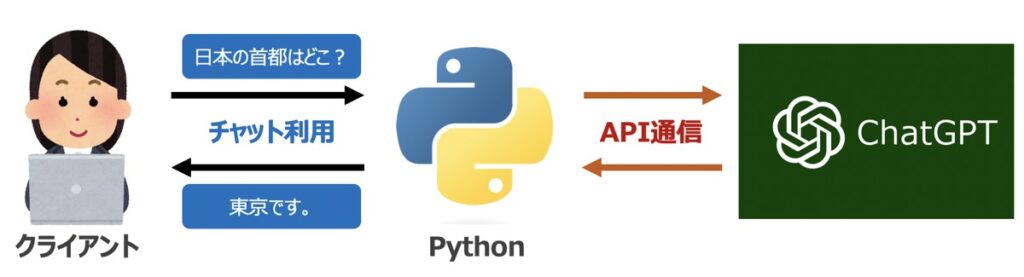
本記事ではChatGPTを用いたPythonプログラミングについて解説します。その際、Open AIが提供するAPI情報が必要になります。「ChatGPTの概要」および「API情報の取得手順」については、こちらの記事で詳しく解説しています。
【参考】ChatGPTを詳しく学びたい方向けの学習講座
ChatGPTを詳しく学びたい方向けに安価で学べるオンライン講座も併せてご紹介します。
【Python×ChatGPT】事前準備
音声ファイルの文字起こし機能実装に際して、必要な事前準備を行います。
- ChatGPT API 呼出用Pythonライブラリのインストール
- 音声ファイルの準備
ChatGPT API 呼出用Pythonライブラリのインストール
音声ファイルの文字起こし実現に際して、今回ChatGPT API(Whisper API)を利用します。このWhisper APIをPythonから呼び出す際、openaiライブラリを活用します。
コマンドプロンプト(WIndows)またはターミナル(Mac)を開き、以下を実行し、ライブラリをインストールしましょう。
pip install openai音声ファイルの準備
ChatGPT Whisper APIを活用したSpeech-To-Text機能の実装に際して、入力となる音声ファイルの準備が必要です。
mp3, mp4, wav, mpeg, mpgaいづれかの拡張子からなる音声ファイルを準備しましょう。
【Python×ChatGPT】 音声文字起こし機能の構築|Speech-To-Text
Pythonプログラムを記述し、ChatGPT APIを活用した音声文字起こし機能の構築方法について解説します。
PythonライブラリとChatGPT API情報の読込
はじめに、Pythonプログラムの先頭にライブラリとAPI認証情報を記述します。
前述で取得したAPIシークレットキーをそれぞれ入力しましょう。
from openai import OpenAI
API_Key = "<APIシークレットキーをここに入力>"音声文字起こし関数の作成
続いて、ChatGPT Whisper APIを呼び出し、音声ファイルを文字起こしするための関数を作成します。
次のコードを記述しましょう。
コード
# 音声文字起こし関数(引数:音声ファイルパス)
def speech_to_text(filepath:str)->str:
# オーディオファイルを開く
audio_file = open(filepath, "rb")
# GPTクライアント生成
client = OpenAI(api_key=API_Key)
# Speech to Text変換
response = client.audio.transcriptions.create(
model = "whisper-1", # Speech-to-Textモデル
file = audio_file, # オーディオファイル
)
# テキスト文章
return response.text引数情報
client.audio.transcriptions.create()メソッドに音声ファイルを渡し、テキストを生成しているのが特徴です。このメソッドでは、次のような引数を指定します。
| 引数名 | 概要 |
|---|---|
| model | 音声文字起こし用のモデル |
| file | 文字起こし用の音声ファイル |
音声文字起こし関数の実行
前述の関数に音声ファイルを渡し、コードを実行してみましょう。実際に出力結果も併せて確認します。
コード
# 音声ファイルのパスを指定
filepath = "chat-gpt-audio-test.wav"
# 関数実行
result = speech_to_text(filepath)出力イメージ
# 出力
print(result)
# 出力イメージ
# PythonによるChat GPTを用いた音声文字起こし機能についてご紹介します。【参考】サイズが大きい音声ファイルの分割・圧縮
今回利用したChatGPT Whisper APIに渡せる音声ファイルサイズは、上限が決まっており、25MB未満に抑えておく必要があります。そのため、25MBを超過した音声ファイルを用いたい場合、25MB以下のチャンクに分割、またはmp3等の圧縮用のオーディオ拡張子に変換する必要があります。
以下、ファイルサイズ超過した「音声ファイルの分割」および「圧縮用拡張子に変換」するためのコードも併せてご紹介します。
pydubライブラリのインストール
音声ファイルの分割および拡張子変換には、pydubライブラリを利用します。事前にインストールしておきましょう。
pip install pydub音声ファイルの分割・圧縮
音声ファイルを「10分間のファイルに分割」および「サイズ圧縮のための拡張子変換」するためのコードを以下に示します。
from pydub import AudioSegment
# 音声ファイルのパスを指定
filepath = "chat-gpt-audio-test.wav"
# AudioSegmentで読込
audio_file = AudioSegment.from_mp3(filepath)
# ミリ秒単位で時間指定(例:10分)
ten_minutes = 10 * 60 * 1000
# 拡張子変換した音声ファイルの出力先
export_path = filepath.split(".")[0] + "_10m.mp3"
# 最初10分間の音声データを分割
first_10_minutes = audio_file[:ten_minutes]
# ファイル出力
first_10_minutes.export(export_path, format="mp3")【参考】本記事で紹介したChatGPT Speech-To-Text用コード全量
最後に、本記事でご紹介した音声文字起こし用のPythonコードを全てまとめて掲載します。
# ============================================================
# API情報
# ============================================================
from openai import OpenAI
API_Key = "<APIシークレットキーをここに入力>"
# ============================================================
# 音声ファイルの文字起こし関数
# ============================================================
# 音声文字起こし関数(引数:音声ファイルパス)
def speech_to_text(filepath:str)->str:
# オーディオファイルを開く
audio_file = open(filepath, "rb")
# GPTクライアント生成
client = OpenAI(api_key=API_Key)
# Speech to Text変換
response = client.audio.transcriptions.create(
model = "whisper-1", # Speech-to-Textモデル
file = audio_file, # オーディオファイル
)
# テキスト文章
return response.text
# ============================================================
# 関数実行
# ============================================================
# 音声ファイルのパスを指定
filepath = "chat-gpt-audio-test.wav"
# 関数実行
speech_to_text(filepath)【参考】おすすめAI自動文字起こしサービス
本記事ではPythonを用いて音声ファイルを文字起こしする方法について解説しましたが、プログラミングの障壁が高い方向けに、厳選したおすすめのAI文字起こしサービスも併せてご紹介します。

【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
