
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
ディープラーニングの画像認識に興味がある方向けに、Tensorflow(Keras)を用いてモデルを作成する方法について解説します。
畳み込みニューラルネットワーク(CNN)とは
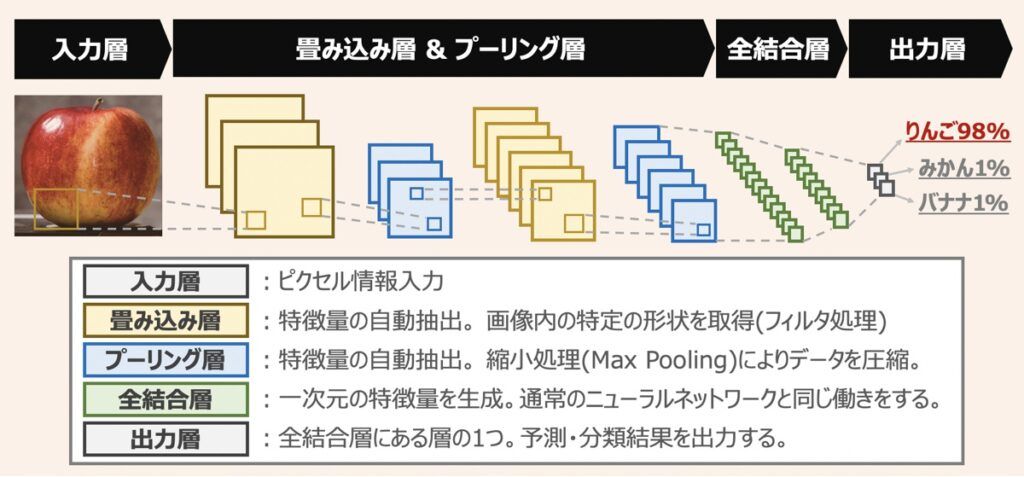
CNNは多次元配列データを扱うことに特化したニューラルネットワークであり、画像認識や動体検知の分野で広く応用されています。
CNNは「畳み込み層」「プーリング層」「全結合層」で構成されるのが特徴です。畳み込み層で画像の特徴を抽出し、プーリング層で特徴データを圧縮します。この操作を繰り返した後、結合層で分類結果を出力します。
【参考】ディープラーニングモデル最適化の仕組み
【深層学習】ニューラルネットワークの仕組みとディープラーニングモデル性能最適化のポイント解説
ディープラーニングの実装を検討している方向けです。深層学習モデルを実装するための仕組みとモデルを最適化する手法など重要なポイントを踏襲しています。本記事読了後、モデル改善に向けた適切なアプローチができるようになるでしょう。
ディープラーニングの仕組みについて詳しく知りたい方はこちらの記事をご覧下さい。
【参考】Kerasを用いた深層学習プログラミング

Kerasでディープラーニングモデルを構築する方法を詳しく知りたい方向けにおすすめ教材をご紹介します。
【深層学習】画像認識AIモデルの作成概要

AI画像認証モデルの作成に際して、本記事では「りんご」「ぶどう」「みかん」を分類することを目的としたモデル作成を試みます。
上記画像以外の分類にも横展開できるようなスクリプト構成としているため、好みの用途に活用できます。
【参考】githubレポジトリの共有
本記事のプログラムは、githubのimage-recognition-kerasに格納されています。
こちらを事前にダウンロードいただくことで、画像認識AIモデルの作成がスムーズにできます。
【Python×Keras】画像認証AIの構築|ディープラーニング実践
以下手順に従い、githubのプログラムを動作させ、画像認証AIを作成します。
後述ではgithubの各種プログラムも詳細に解説しています。
- データの準備
- 【任意】docker環境構築
- モデル学習・検証用データの作成
- モデル学習(CNN)
- 評価
- 推論
データの準備
トレーニング・テストデータを格納した画像フォルダを準備します。デフォルトでfruits-sample-datasetが以下のディレクトリに格納されています。
- data
|- image
|- apple
|- orange
|- grape今回はapple, orange, grapeで画像を分類していますが、ここを用途に合わせて変更することで様々な画像認識モデルが作成できます。例えば、man(男), woman(女)というフォルダを作成し、それぞれのデータを準備すれば、男女を区別する画像認識モデルの作成も可能です。
【任意】dockerを用いた開発環境の構築
githubリンクのdockerfileをもとに、開発環境を構築すると正常な動作確認済みの環境でプログラムを実行できます。
コマンドプロンプト(Windows)またはターミナル(Mac)を開き、dockerfileがあるディレクトリに移動し、コードを実行しましょう。
docker build -f Dockerfile -t image-classify .docker run -it --rm --name image-classify -p 5005:5000 --mount type=bind,src="$(pwd)",dst=/work image-classify bash尚、dockerについて詳しく知りたい方はこちらの記事をご覧ください。
【Docker】Dockerfileとは|書き方・コマンド一覧・イメージ作成手順を徹底解説
「Dockerfile」について知りたい方向けに「dockerfileとは」「コマンドの書き方」「作成方法」を詳しく解説します。
モデル学習・検証用データの作成
指定の画像ファイルを読み込み、3色(RGB)の数値配列に変換した後、モデル学習・評価用のトレーニングデータとテストデータを作成する方法を以下に示します。
実行コマンド
コマンドプロンプト(Windows)またはターミナル(Mac)を開き、main.pyがあるディレクトリに移動し、コードを実行しましょう。
python main.py --mode data_prep作成ファイル情報
実行後、intermediate_data.npzという数値配列からなるトレーニング・テストデータがdataフォルダ直下に作成されます。
- data
|- image
|- apple
|- orange
|- grape
|
|- intermediate_data.npz【参考】データ作成スクリプト
画像認識AIのトレーニング・検証データ準備に際して、画像をRGBの数値データに変換したコードは以下に格納されています。
src/praparation.py
from PIL import Image
import os
import glob
import numpy as np
from sklearn import model_selection
from keras.src.utils.np_utils import to_categorical
from config import *
# 中間データ作成関数
def data_prep():
# =======================================================================
# データ準備
# =======================================================================
# 画像
X = [] #学習
Y = [] #ラベル
for index, classlabel in enumerate(classes):
# 画像データ(.jpg)全取得
files = glob.glob(f'{input_dir}/{classlabel}/*.{extension}')
# 写真を順番に取得
for i, file in enumerate(files):
# 画像を1つ読込
image = Image.open(file)
# 画像をRGB変換
image = image.convert("RGB")
# サイズを揃える
image = image.resize((image_size, image_size))
# 画像を数字の配列に変換
data = np.asarray(image)
# Xに配列、Yにインデックスを追加
X.append(data)
Y.append(index)
# X,YがリストなのでTensorflowが扱いやすいようnumpyの配列に変換
X = np.array(X)
Y = np.array(Y)
# X,Yを学習用と評価用のデータに分類
X_train,X_test,y_train,y_test = model_selection.train_test_split(X, Y, test_size=0.2)
# =======================================================================
# データの正規化
# =======================================================================
# 特徴量:0~255の整数を0~1区間として正規化
X_train = X_train.astype("float") / X_train.max()
X_test = X_test.astype("float") / X_train.max()
# クラスラベル:正解は1、他は0になるようワンホット表現に変換
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
print("=======X_train=========")
print(f"shape: {X_train.shape}")
print(f"data : {X_train[0]}")
print("=======y_train=========")
print(f"shape: {y_train.shape}")
print(f"data : {y_train[0]}")
# =======================================================================
# 中間データ保存
# =======================================================================
# npz型式でデータを保存
xy = (X_train,X_test,y_train,y_test)
np.savez(intermediate_data,*xy)
# 出力
print("data prep: successfully create a intermediate data for modeling")
return [X_train, X_test, y_train,y_test]
# 実行関数
def exe_prep_data(create_data=True):
match create_data:
# 中間データがない場合
case True:
print("creating a intermediate data for modeling.")
loaded_data = data_prep()
return {"X_train": loaded_data[0],
"X_test": loaded_data[1],
"y_train": loaded_data[2],
"y_test": loaded_data[3],
}
# 中間データ作成済みの場合
case False:
print("skip creating a intermediate data.")
# npzファイルをロード
loaded_data = np.load(intermediate_data)
# npzファイルの各種データを定義付
return {"X_train": loaded_data["arr_0"],
"X_test": loaded_data["arr_1"],
"y_train": loaded_data["arr_2"],
"y_test": loaded_data["arr_3"],
}モデル学習(CNN)
前述で作成したintermediate_data.npzを読み込み、畳み込みニューラルネットワーク(CNN)のモデルを学習する方法を以下に示します。
実行コマンド
コマンドプロンプト(Windows)またはターミナル(Mac)を開き、main.pyがあるディレクトリに移動し、コードを実行しましょう。
python main.py --mode train作成ファイル情報
実行後、model_cnn_h5というKerasで作成した学習済みモデルがdataフォルダ直下に作成されます。
- data
|- image
|- apple
|- orange
|- grape
|
|- intermediate_data.npz
|
|- model_cnn_h5【参考】モデル学習用スクリプト
画像認識モデルの学習用コードは以下に格納されています。
src/modeling.py
# =============================================================
# ライブラリ設定
# =============================================================
import tensorflow
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation,Dropout,Flatten,Dense
from tensorflow.keras.optimizers import RMSprop
from tensorflow import keras
from config import *
# =============================================================
# モデル学習&評価用関数
# =============================================================
class modeling():
def __init__(self, **kwargs):
self.X_train = kwargs["X_train"]
self.X_test = kwargs["X_test"]
self.y_train = kwargs["y_train"]
self.y_test = kwargs["y_test"]
self.model_path = model_path
# モデル構築(学習・推論)
def build_model(self, mode:str):
# ======================================================
# ニューラルネットワークの定義
# ======================================================
# モデルインスタンス
model = Sequential()
# 1層目 (畳み込み)
model.add(Conv2D(32,(3,3),padding="same", input_shape=self.X_train.shape[1:]))
model.add(Activation('relu'))
# 2層目(Max Pooling)
model.add(Conv2D(32,(3,3)))
model.add(Activation('relu'))
# 3層目 (Max Pooling)
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.3))
# 4層目 (畳み込み)
model.add(Conv2D(64,(3,3),padding="same"))
model.add(Activation('relu'))
# 5層目 (畳み込み)
model.add(Conv2D(64,(3,3)))
model.add(Activation('relu'))
# 6層目 (Max Pooling)
model.add(MaxPooling2D(pool_size=(2,2)))
# データを1次元化
model.add(Flatten())
# 7層目 (全結合層)
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
# 分類クラス数を定義
model.add(Dense(num_classes))
# 出力層(softmaxで0〜1の確率を返す)
model.add(Activation('softmax'))
# ======================================================
# 学習方法の定義
# ======================================================
# 最適化手法
opt = RMSprop(learning_rate=0.001, rho=0.9, momentum=0.0, epsilon=1e-07)
# 損失関数
model.compile(loss="categorical_crossentropy", # 損失関数
optimizer=opt, # 最適化アルゴリズム
metrics=["accuracy"], # 最適化指標
)
# ======================================================
# 処理プロセスの定義
# ======================================================
match mode:
# 学習
case "train":
model.fit(self.X_train, # 学習データ
self.y_train, # 学習データ(クラスラベル)
batch_size=32, # バッチサイズ
epochs=100, # エポック数
)
# 学習済モデル保存
model.save(self.model_path)
# 検証
case "eval":
# 学習済みモデル呼出
model = keras.models.load_model(self.model_path)
# 推論
case "prediction":
# 学習済みモデル呼出
model = keras.models.load_model(self.model_path)
# モデル出力
return model今回畳み込みニューラルネットワークのレイヤーには次のようなものを定義しています。詳しくはKeras Documentationをご覧下さい。
| レイヤー | 概要 |
|---|---|
| Conv2D | 畳み込み層 |
| MaxPooling2D | プーリング層 |
| Activation | 活性化関数 |
| Dropout | ドロップアウト |
| Flatten | 多次元配列を1次元のベクトルに変換 |
| Dense | 全結合層 |
検証
上記で作成した学習済みモデルの性能評価を実施する方法について解説します。
実行コマンド
コマンドプロンプト(Windows)またはターミナル(Mac)を開き、main.pyがあるディレクトリに移動し、コードを実行しましょう。
python main.py --mode eval【参考】評価スクリプト
画像認識モデルの評価用コードは以下に格納されています。
src/evaluation.py
from PIL import Image
from config import *
def eval(learned_model, **kwargs):
# 検証データ読込
X_test = kwargs["X_test"]
y_test = kwargs["y_test"]
# 学習済みモデル読込
model = learned_model
# Kerasのevalueateメソッドで検証
scores = model.evaluate(X_test, y_test, verbose=0)
print("================================")
print(f"Test Loss: {round(scores[0],2)}")
print(f"test Accuracy: {round(scores[1],3)*100} [%]")
print("================================")
return {"Test Loss": scores[0], "test Accuracy": scores[1]}モデル推論
学習済モデルを用いて推論を実施する方法を以下に示します。
実行コマンド
コマンドプロンプト(Windows)またはターミナル(Mac)を開き、main.pyがあるディレクトリに移動し、コードを実行しましょう。
第二引数filepathに推論したい画像ファイルを指定します。
python main.py --mode prediction --filepath data/predict/grape.jpg【参考】推論スクリプト
画像認識モデルの推論用コードは以下に格納されています。
src/prediction.py
from PIL import Image
from config import *
import numpy as np
def pred(predict_path, pred_model):
# =======================================================
# 推論用のデータ準備
# =======================================================
image = Image.open(predict_path) # 画像読込
image = image.convert("RGB") # RGB変換
image = image.resize((image_size,image_size)) # リサイズ
data = np.asarray(image) # 数値の配列変換
X = []
X.append(data)
X = np.array(X)
# =======================================================
# 推論
# =======================================================
# Xを与えて予測値を取得
# データを1つしかしれてないので0番目の配列を最後に指定
result = pred_model.predict([X], verbose=0)[0]
print("===================")
print(f"class: {classes}")
print(f"pred: {result}")
# 推定値 argmax()を指定しresultの配列にある推定値が一番高いインデックス抽出
predicted = result.argmax()
# 精度を[%]表記に変換
percentage = int(result[predicted] *100)
# 結果出力
print(f"result: {classes[predicted]} ({percentage}[%])")
print("===================")
return {"result":classes[predicted], "percentage": percentage}【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
