
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- OpenAI社のChatGPTモデルをもとに作成したチャットボットの性能評価を行いたい
- LangChain QAEvalChainを用いて、言語モデルの出力精度を評価するPythonプログラム作成方法が知りたい
LangChainとは?
LangChainとは、ChatGPTを代表とするような大規模言語モデル(LLM)の機能を拡張し、サービスとして展開する際に役立つライブラリです。
LangChainの主要機能
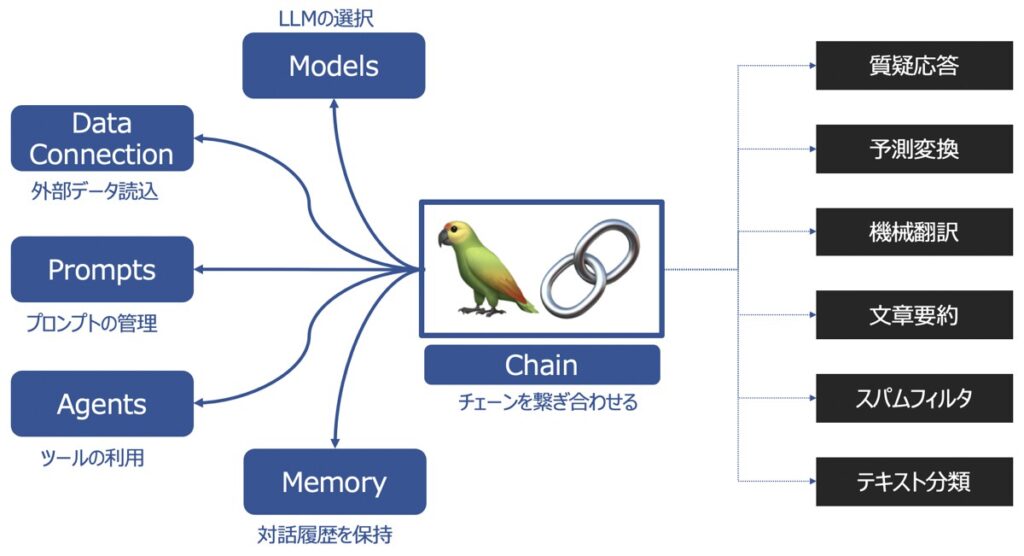
LangChainの主要な機能として以下があります。
| 主要機能 | 概要 |
|---|---|
| Models | 様々な大規模言語モデルを同じインターフェース上で取り扱えるようにする機能 |
| Prompts | プロンプトの管理、最適化、シリアル化ができる機能 |
| Memory | 言語モデルを用いてユーザーと対話した履歴を記憶する機能 |
| Data connection | 言語モデルに外部データを投入し、外部データに基づく回答を生成する機能 |
| Chains | チェーンを複数繋げて、一連の処理を連続実行する機能 |
| Agents | ユーザーからの要望をどんな手段・順序で応えるか決定・実行する機能 |
LangChainの各種機能の詳細を知りたい方は、こちらの記事をご覧下さい。

【参考】LangChainを用いたプログラミング実装におすすめの学習教材
LangChainライブラリを用いてプログラミングし、アプリケーションを実装したい方向けに、おすすめの学習教材をご紹介します。
【事前準備】Pythonライブラリインストール・OpenAI API情報取得
大規模言語モデル(LLM)やチャットモデルの回答性能評価に際して、必要な準備2点を実施しましょう。
Pythonライブラリのインストール
Pythonプログラム実装に際して、以下に示すライブラリをインストールします。
openai
OpenAI社のGPTモデル呼出に必要なライブラリです。
pip install --upgrade openailangchain
LangChain機能利用に際して必要なライブラリです。
pip install langchain【ChatGPT】OpenAI社のAPI発行
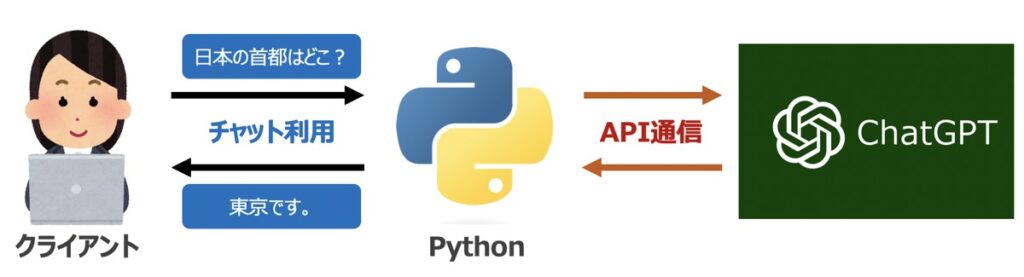
LangChain機能構築に際して、OpenAI社が提供するGPTモデルをAPI経由で呼び出す必要があります。
OpenAI社の公式サイトから「API シークレットキー」を事前に発行しておきましょう。なお、シークレットキーの発行方法はこちらの記事で詳しく解説しています。
【Python × LangChain】LLM・チャットモデルの性能評価
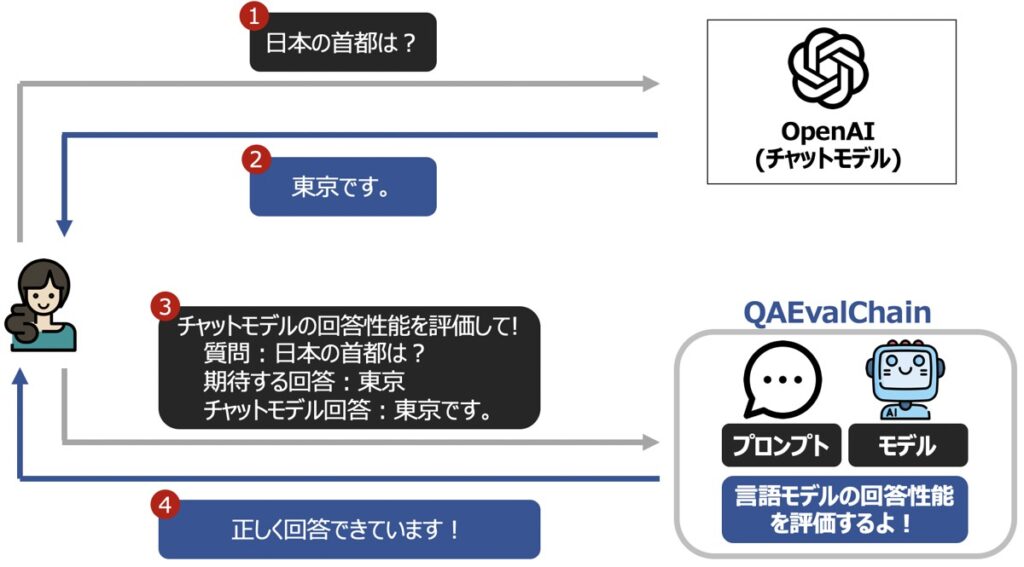
LangChain Chains機能の1つであるQAEvalChainを用いて、ChatGPTのような大規模言語モデル(LLM)の出力性能を評価する方法について解説します。
LangChain Chainsの詳しい内容についてはこちらの記事で解説しています。

【データ準備】テストデータを準備
大規模言語モデル(LLM)の性能評価に用いるテストデータ準備します。
テストデータイメージ
LLMに渡す質問内容queryと期待する回答結果answerという列を持つExcelファイルを準備します。
| query | answer |
|---|---|
| 日本の首都はどこですか? | 東京 |
| フランスの首都はどこですか? | パリ |
| イギリスの首都はどこですか? | ロンドン |
| アメリカの首都はどこですか? | ワシントンD.C |
テストデータサンプルのダウンロード
サンプルとして、validation.xlsxというExcelファイルをご自由にダウンロードしてお使い下さい。
Pythonライブラリのインストール
Pythonファイルの先頭に以下のプログラムを配置し、OpenAI社のサイトから取得したシークレットキーを記述しましょう。
import openai
import pandas as pd
import os
# APIシークレットキーを記述
SECRET_KEY = "............."
# API認証情報設定
os.environ["OPENAI_API_KEY"] = SECRET_KEYテストデータの読込
前述で用意したテストデータをPython環境に読み込みます。以下のコードを実行しましょう。
コード
# ====================================================================
# テストデータ読込
# ====================================================================
# 性能評価用の検証データを読込
test_data = pd.read_excel("validation.xlsx")
# データ構造を辞書型に変換
test_data_dict_list = []
for i in range(len(test_data)):
test_dta_dict = {"query": test_data.loc[i,"query"],
"answer": test_data.loc[i,"answer"],}
test_data_dict_list.append(test_dta_dict)出力イメージ
上記データ読込時に、後述の性能評価のために、テストデータの構造を辞書形式に変換しています。
# 出力
print(test_data_dict_list)
# 出力イメージ
# [{'query': '日本の首都はどこですか?', 'answer': '東京'},
# {'query': 'フランスの首都はどこですか?', 'answer': 'パリ'},
# {'query': 'イギリスの首都はどこですか?', 'answer': 'ロンドン'},
# {'query': 'アメリカの首都はどこですか?', 'answer': 'ワシントンD.C'}]大規模言語モデルを準備
性能評価したいLLM・チャットモデルを準備しましょう。サンプルとして単純なLLM作成例を示します。
from langchain.llms import OpenAI
# ====================================================================
# 言語モデル作成
# - ここの枠にご自身で作成した言語モデルを定義すると良い
# ====================================================================
# LLM作成
LLM = OpenAI(
model_name = "text-davinci-003", # OpenAIモデル名
temperature = 0, # 出力する単語のランダム性(0から2の範囲) 0であれば毎回返答内容固定
n = 1, # いくつの返答を生成するか
)大規模言語モデル実行
前述で作成したLLMに対して、テストデータに用意された質問内容queryを投入します。そこで得られた出力結果をresultとして保存します。
コード
# ====================================================================
# テストデータの質問内容をモデルに投入&出力結果を保存
# ====================================================================
for i in range(len(test_data_dict_list)):
# LLM実行
model_result = LLM(test_data_dict_list[i]["query"]).replace("\n","")
# LLM実行結果格納
test_data_dict_list[i]["result"] = model_result出力イメージ
テストデータの辞書リストtest_data_dict_listを出力すると、モデルの回答結果resultも併せて確認できるようになりました。
# 出力
print(test_data_dict_list)
# 出力イメージ
# [{'query': '日本の首都はどこですか?', 'answer': '東京', 'result': '日本の首都は東京都です。'},
# {'query': 'フランスの首都はどこですか?', 'answer': 'パリ', 'result': 'パリです。'},
# {'query': 'イギリスの首都はどこですか?', 'answer': 'ロンドン', 'result': 'イギリスの首都はロンドンです。'},
# {'query': 'アメリカの首都はどこですか?', 'answer': 'ワシントンD.C', 'result': 'ワシントンD.C.'}]QAEvalChainによる大規模言語モデルの性能評価
テストデータの質問内容queryと期待する回答結果answer、LLMの回答結果resultをLangChain QAEvalChainに渡すことで、LLMの回答精度を評価します。
LLMの回答精度の評価方法は、LangChain Prompt Templateに対して自由に定義することができます。
以下、「判定」と「スコアリング」という2つの評価方法を例として示します。
(1)性能評価|判定
LangChain QAEvalChainを用いた性能評価(判定)方法について解説します。
コード
from langchain.evaluation.qa import QAEvalChain
from langchain.prompts import PromptTemplate
# ====================================================================================
# プロンプトテンプレート作成
# ====================================================================================
# 評価用テンプレート
template = \
"""
You are a teacher grading a quiz.
You are given a {query}, the student's answer as {result}, and the true answer as {answer},
and are asked to score the student's answer as either CORRECT or INCORRECT.
Output format: CORRECT or INCORRECT
"""
# プロンプトテンプレート
prompt_template = PromptTemplate(
input_variables = ["query", "answer", "result"],
template = template)
# ====================================================================================
# 評価用チェーン
# ====================================================================================
# QAEvalChain作成
evaluation_chain = QAEvalChain.from_llm(
llm = OpenAI(), # 正解ラベルとモデル出力結果が正しいか判断するLLM
verbose = False, # 途中プロンプトの表示有無
prompt = prompt_template, # プロンプトテンプレート
)
# QAEvalChain実行
graded_outputs = evaluation_chain.evaluate(
test_data_dict_list, # 教師データ(クエリと正解ラベル)を含む辞書リスト
test_data_dict_list, # モデルの出力結果(result)を含むの辞書リスト
question_key = "query", # テストデータの入力項目
answer_key = "answer", # テストデータの入力項目に対する正解ラベル
prediction_key = "result", # モデルの出力結果に該当する項目
)
# ====================================================================================
# 評価結果格納
# ====================================================================================
for i in range(len(test_data_dict_list)):
test_data_dict_list[i]["QAEval"] = graded_outputs[i]["text"].replace("\n","").replace(" ","")
print(test_data_dict_list)出力イメージ
上記コードで作成したQAEvalChainの実行結果を示します。
質問内容queryに対して、期待する回答answerとLLMの回答resultが類似する場合「COLLECT」、類似しない場合「INCORRECT」と出力されます。
# 出力
print(test_data_dict_list)
# 出力イメージ
# [{'query': '日本の首都はどこですか?',
# 'answer': '東京',
# 'result': '日本の首都は東京都です。',
# 'QAEval': 'CORRECT'},
# {'query': 'フランスの首都はどこですか?',
# 'answer': 'パリ',
# 'result': 'パリです。',
# 'QAEval': 'CORRECT'},
# {'query': 'イギリスの首都はどこですか?',
# 'answer': 'ロンドン',
# 'result': 'イギリスの首都はロンドンです。',
# 'QAEval': 'CORRECT'},
# {'query': 'アメリカの首都はどこですか?',
# 'answer': 'ワシントンD.C',
# 'result': 'ワシントンD.C.',
# 'QAEval': 'CORRECT'}](2)性能評価|スコアリング
LangChain QAEvalChainを用いた性能評価(スコアリング)方法について解説します。
コード
from langchain.evaluation.qa import QAEvalChain
from langchain.prompts import PromptTemplate
# ====================================================================================
# プロンプトテンプレート作成
# ====================================================================================
# 評価用テンプレート
template = \
"""
You are an expert professor specialized in grading students' answers to questions.
You are grading the following question:{query}
Here is the real answer:{answer}
You are grading the following predicted answer:{result}
What grade do you give from 0 to 10, where 0 is the lowest (very low similarity) and 10 is the highest (very high similarity)?
Output format: grade
"""
# プロンプトテンプレート
prompt_template = PromptTemplate(
input_variables = ["query", "answer", "result"],
template = template)
# ====================================================================================
# 評価用チェーン
# ====================================================================================
# QAEvalChain作成
evaluation_chain = QAEvalChain.from_llm(
llm = OpenAI(), # 正解ラベルとモデル出力結果が正しいか判断するLLM
verbose = False, # 途中プロンプトの表示有無
prompt = prompt_template, # プロンプトテンプレート
)
# QAEvalChain実行
graded_outputs = evaluation_chain.evaluate(
test_data_dict_list, # 教師データ(クエリと正解ラベル)を含む辞書リスト
test_data_dict_list, # モデルの出力結果(result)を含むの辞書リスト
question_key = "query", # テストデータの入力項目
answer_key = "answer", # テストデータの入力項目に対する正解ラベル
prediction_key = "result", # モデルの出力結果に該当する項目
)
# ====================================================================================
# 評価結果格納
# ====================================================================================
for i in range(len(test_data_dict_list)):
test_data_dict_list[i]["QAEval"] = graded_outputs[i]["text"].replace("\n","").replace(" ","")出力イメージ
上記コードで作成したQAEvalChainの実行結果を示します。
質問内容queryに対して、期待する回答answerとLLMの回答resultが類似する場合10点に近いスコアを示し、類似しない場合0点に近いスコアが出力されます。
# 出力
print(test_data_dict_list)
# 出力イメージ
# [{'query': '日本の首都はどこですか?',
# 'answer': '東京',
# 'result': '日本の首都は東京都です。',
# 'QAEval': '10'},
# {'query': 'フランスの首都はどこですか?',
# 'answer': 'パリ',
# 'result': 'パリです。',
# 'QAEval': '10'},
# {'query': 'イギリスの首都はどこですか?',
# 'answer': 'ロンドン',
# 'result': 'イギリスの首都はロンドンです。',
# 'QAEval': '10'},
# {'query': 'アメリカの首都はどこですか?',
# 'answer': 'ワシントンD.C',
# 'result': 'ワシントンD.C.',
# 'QAEval': '10'}]【参考】PythonによるLLM実装|ChatGPT・LangChain

本記事では、PythonでLLMを構築し、様々なタスクをこなす機能の実装方法を多数解説しています。
Python × ChatGPT関連記事
Python × LangChain関連記事
自然言語処理の学習におすすめの書籍

自然言語処理の概要について詳しく学びたい方向けに、厳選したおすすめの学習教材を紹介しています。
最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
【参考】PythonによるLLM実装|ChatGPT・LangChain
本記事では、PythonでLLMを構築し、様々なタスクをこなす機能の実装方法を多数解説しています。
Python × ChatGPT関連記事
Python × LangChain関連記事
自然言語処理の学習におすすめの書籍
自然言語処理の概要について詳しく学びたい方向けに、厳選したおすすめの学習教材を紹介しています。
