
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- LangChainについて詳しく学びたい
- LangChainの主要機能であるModels・Prompts・Data Connection・Agents・Memory・Chainsを理解したい
LangChainとは?
LangChainとは、ChatGPTを代表とするような大規模言語モデル(LLM)の機能を拡張し、サービスとして展開する際に役立つライブラリです。
LangChainでできること
専門タスクに対応できる
LLMは多くの自然言語タスクを効果的に実行できますが、深いドメイン知識や専門知識を必要とする質問やタスクに対して具体的な回答を提供できない可能性があります。 たとえば、医学や法律などの特定の分野に関する質問に回答するためにLLMを使用したいとします。LLMは、この分野に関する一般的な質問には回答できる場合がありますが、専門知識を必要とする詳細な質問には、求められる回答を提供できない可能性があります。LangChainが提供する機能を用いると、上記のようなLLMが持つ課題を解決できるようになります。
最新情報に対応できる
ChatGPTを代表する大規模言語モデルは、多様な分野の質問に対して高精度に回答できる一方、日々の最新情報に紐づく質問への回答においては、精度が低くなるという課題があります。LangChainでは、LLMが最新情報にも対応できるようになる機能が提供されています。
長文にも対応できる
ChatGPTを代表する大規模言語モデルは、入力文書を渡す際に文字数制限の考慮が必要です。例えば、長文からなるPDFファイルを入力し、ChatGPTで要約された文章受け取りたいとします。このようなユースケースにおいてもLangChainを用いると容易に実現することが可能です。
対応可能言語
2023年時点でLangChainは次の言語に対応しています。
- Python
- TypeScript
【参考】LangChainを用いたプログラミング実装におすすめの学習教材
LangChainについて詳しく学びたい方向けにおすすめの教材をご紹介します。
LangChainの主要機能
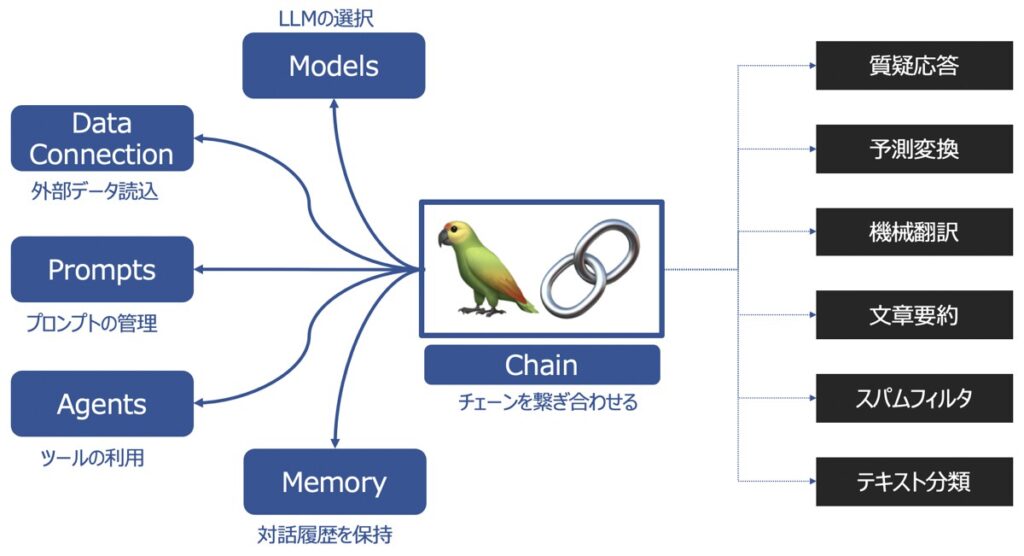
LangChainの主要な機能として以下があります。
| 主要機能 | 概要 |
|---|---|
| Models | 様々な大規模言語モデルを同じインターフェース上で取り扱えるようにする機能 |
| Prompts | プロンプトの管理、最適化、シリアル化ができる機能 |
| Memory | 言語モデルを用いてユーザーと対話した履歴を記憶する機能 |
| Data Connection | 言語モデルに外部データを投入し、外部データに基づく回答を生成する機能 |
| Chains | チェーンを複数繋げて、一連の処理を連続実行する機能 |
| Agents | ユーザーからの要望をどんな手段・順序で応えるか決定・実行する機能 |
以下、1つずつ見ていきましょう。
LangChain|Models(モデル)

LangChain Models(モデル)とは、ChatGPTを代表するGPT-3.5など、様々なLLM、チャットモデル、Embeddingsモデルを同じインターフェース上で取り扱えるようにする機能です。
様々なモデルを1つのインターフェースで扱うことで、個々のモデルを容易に組み合わせたり、カスタマイズしたモデルを作成できるようになります。結果、多分野での応用の幅が広がります。
LangChain Modelsでは、次の種類のモデルが1つのインターフェース上で取り扱い可能です。
- 大規模言語モデル(LLM)
- チャットモデル
- Embeddingsモデル
大規模言語モデル(LLM)
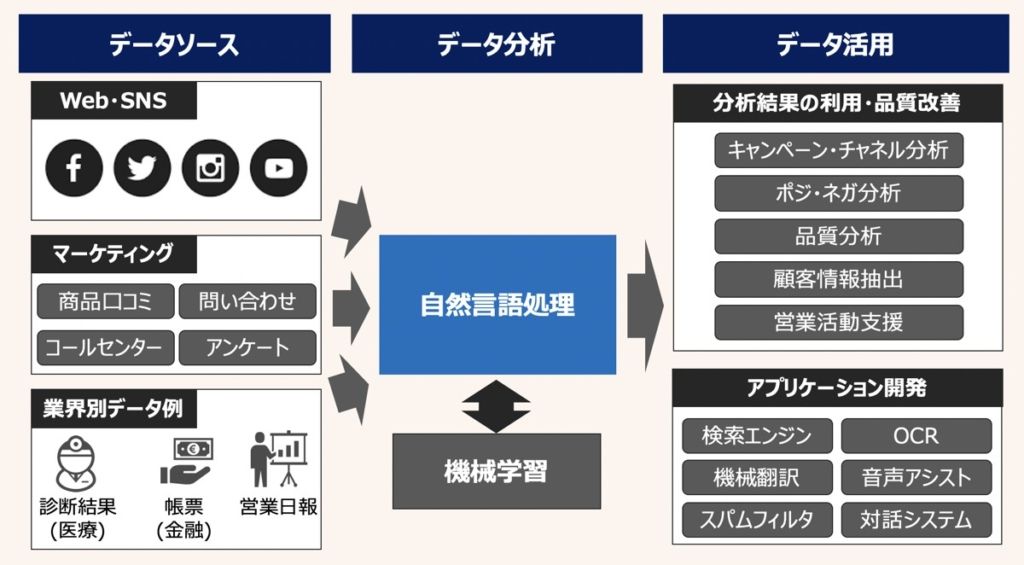
大規模言語モデル(LLM)とは、Large Language Modelsの略であり、大量のテキストデータを用いてトレーニングされた自然言語処理モデルです。たとえば、OpenAI社が提供するGPT3.5モデル(gpt-3.5-turbo)やGoogle社のFlan-T5(flan-t5-xl)等があります。
代表的な自然言語処理タスク
LLMでは、次のようなタスクをこなすことができます。
- 質疑応答
- テキスト分類
- 予測変換
- 文章要約
- 機械翻訳
- スパムフィルタ
LangChainとの連携サービス
LangChainは次に示す提供サービスと連携しています。近年ではChatGPTを代表とするOpenAI社のLLMがLangChainでも広く取り扱われています。
AI21
Aleph Alpha
Anthropic
Azure OpenAI LLM Example
Banana
CerebriumAI LLM Example
Cohere
DeepInfra LLM Example
ForefrontAI LLM Example
GooseAI LLM Example
GPT4All
Hugging Face Hub
Llama-cpp
Manifest
Modal
OpenAI
Petals LLM Example
PromptLayer OpenAI
Replicate
SageMakerEndpoint
Self-Hosted Models via Runhouse
StochasticAI
Writerチャットモデル

チャットモデルとは、チャットメッセージに対して適切な返答は返すことに特化したモデルです。
チャットモデル内部では同じくLLMが活用されています。一方、LLMの入出力形式に関してはチャットモデルに特化する形式として構造化されているのが特徴です。
Embeddingsモデル
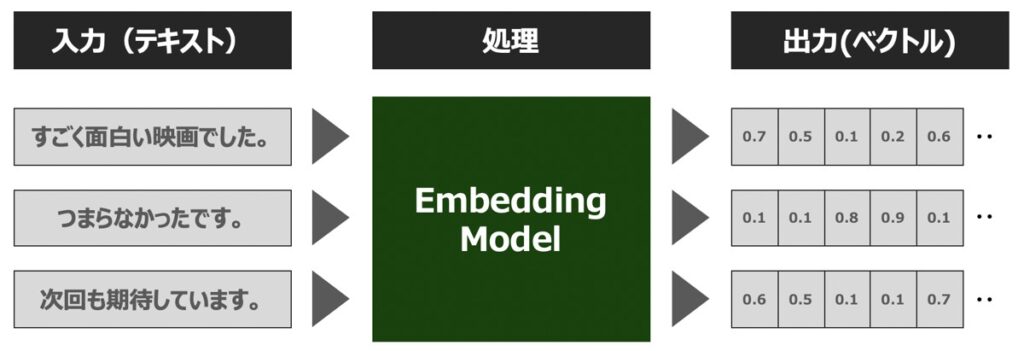
Embeddings(埋め込み表現)とは、単語や文章等の自然言語の構成要素をベクトルに変換する処理を指します。このような処理が可能なモデルを、Embeddingsモデルと呼びます。
Embeddingsモデルの役割
1つの単語の意味を低次元の実数値ベクトルで表現することを「分散表現」と呼びます。Embeddingsモデルを用いて分散表現を得ることで、次のようなタスクを実現できるようになります。
- 2つの文章同士の関連性を定量的に測定する
- 自然言語からなる特徴量を機械学習・ディープラーニングの説明変数として用いる
Embeddingは、浮動小数点数のベクトル (リスト) として出力されます。 2つのベクトル間の距離によって、それらの関連性が測定できます。 距離が小さい場合は関連性が高いことを示し、距離が大きい場合は関連性が低いことを示しています。
文章をベクトル表現に変換することで、機械学習・ディープラーニングによる計算処理が可能になり、その結果、自然言語からなる特徴量を説明変数として用いることもできるようになります。
【参考】Embeddingsとは?
Embeddingsについてさらに詳しく学びたい方はこちらの記事をご覧ください。

【参考】Python 実装方法
Pythonを用いたLangChain Modelsの機能実装方法も併せて解説しています。

LangChain|Prompts(プロンプト)
LangChain Promptsとは、プロンプトの管理、最適化、シリアル化ができる機能を指します。なお、Prompt(プロンプト)とは、言語モデルが応答を生成するための「指令文や文章」を指します。
LangChain PromptsをもとにLLMのプロンプトエンジニアリングを効率化できます。例えば、記述するコードも最小限にできたり、モデル実装にかかるコストを抑えることが可能です。
Langchain Promptsの機能を細分化すると、以下3つに分けられます。
- Prompt Templates
- Example Selectors
- Output Persers
Prompt Templates
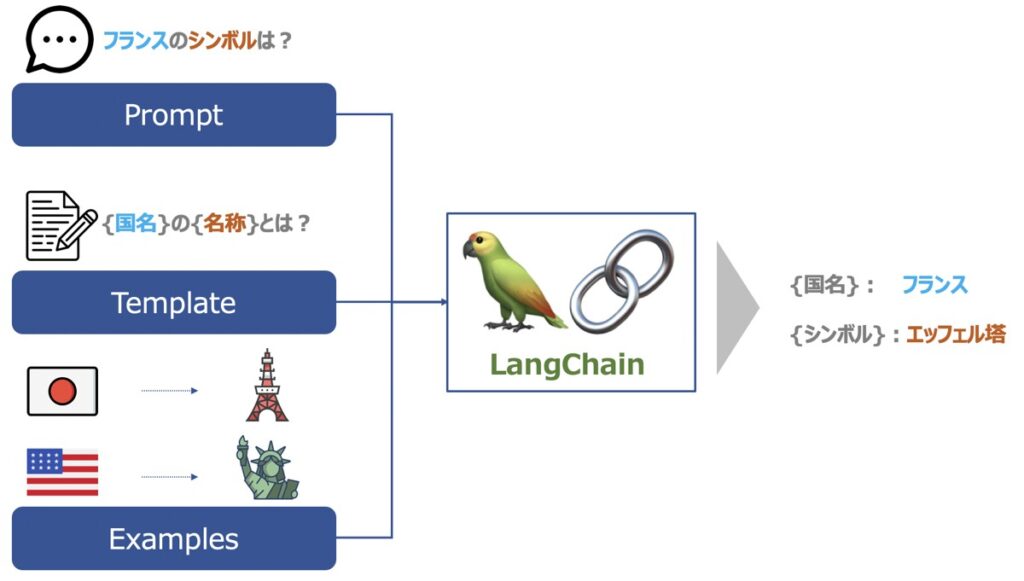
Prompt Templateとは、「形式化された指示文」です。Template内には、任意の{入力変数}が定義されています。Prompt Templateが{入力変数}を受け取ると、形式文に沿って動的にプロンプトが生成できる仕組みです。
Prompt Templatesの種類
3種類のPrompt Templateが代表的に利用されています。
| LLM Prompt Templates | LLMのプロンプト表示方法を示したテンプレート |
| Chat Prompt Templates | チャットモデルのプロンプト表示方法を示したテンプレート |
| FewShot PromptTemplate | LLMのプロンプト表示方法に加え、「教師データをどのようなフォーマットで学習させるのか」も指定したテンプレート |
Prompt Templatesの中身
Prompt Templatesには次の指示文が指定できます。
- 言語モデルへの指示文章
- 入力変数
- 言語モデルがより良い応答を生成するのに役立ついくつかの教師データ
Example Selectors
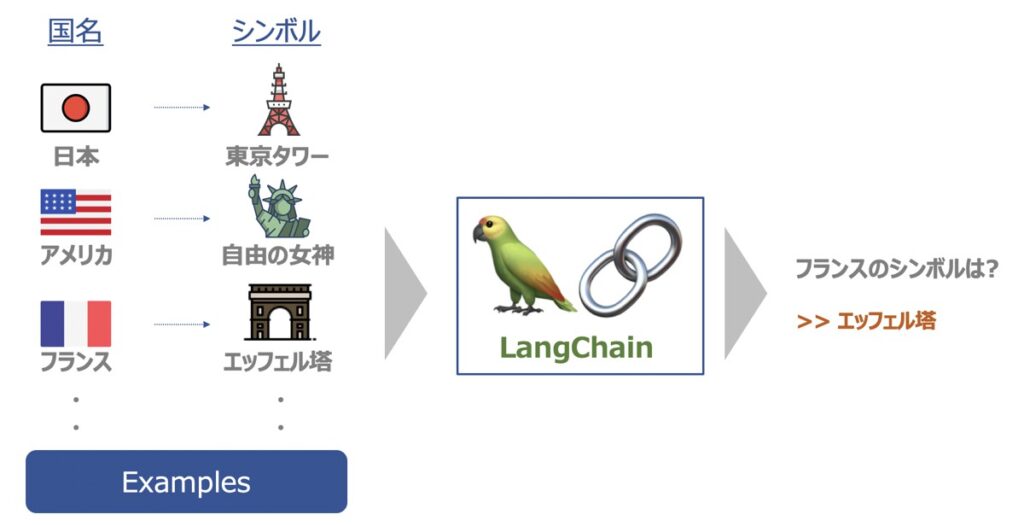
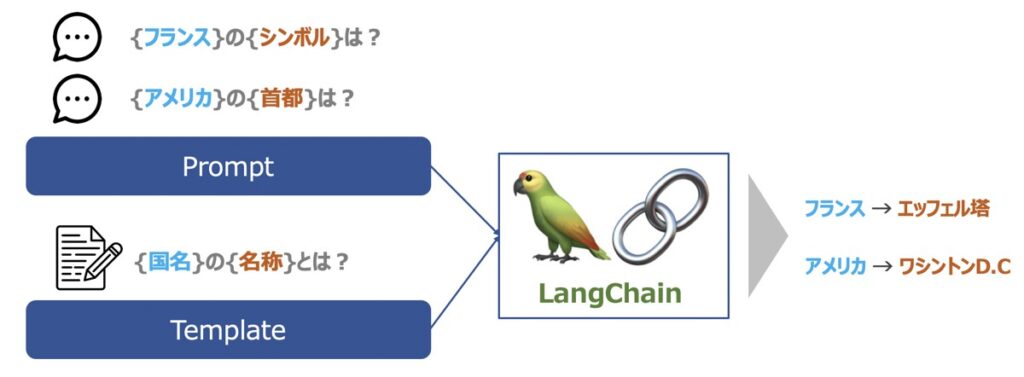
Example Selectorsとは、特定の文脈において、特定の種類の例文を適切に選択できるようにするための機能です。
Example Selectorは、言語モデルの出力に多数の例が想定される際に有効な機能です。
例えば、OpenAIが提供するGPTモデルの場合、GPTモデルで入出力できる最大トークン数が制限されています。プロンプトテンプレートに多数の例文を含めてしまうと、最大トークン数を超過してしまったり、出力できるトークン数の上限を小さくしなければならなくなります。
そこで検討されたのが、ユーザーが入力した文脈に対して適当な例文のみをプロンプトテンプレートに含めるという考えです。これをExample Selectorsを用いて実現し、特定の種類の例を優先したり、無関係な例を除外したり制御するのです。
Output Persers
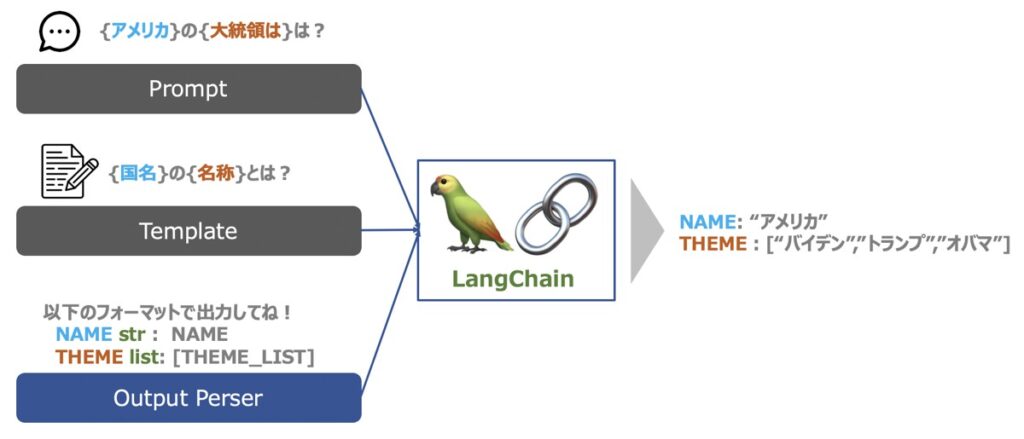
Output Parsersとは、LLMの出力結果を構造化するのに役立つ機能です。
LLMはテキストを出力できます。この時、単にテキストをそのまま出力するだけではなく、構造化された形式のもと、結果を出力したい場合があるでしょう。 このような場面でOutput Perserが役立ちます。
【参考】Python 実装方法
Pythonを用いたLangChain Prompsの機能実装方法も併せて解説しています。

LangChain|Memory(メモリー)
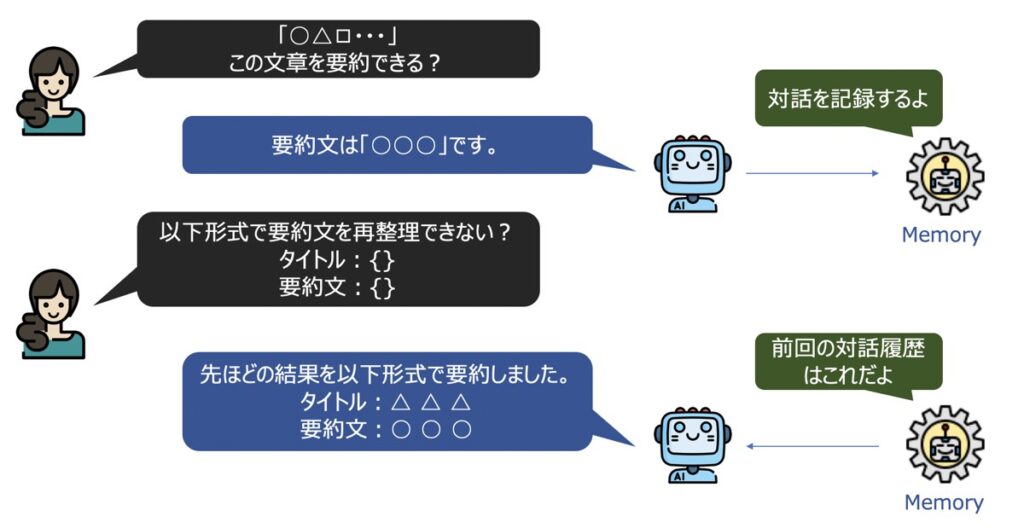
LangChain Memory(メモリー)とは、LLMを用いてユーザーと対話した履歴を記憶する機能です。
チャット上のやり取りはデフォルトでステートレスであるため、対話履歴が保持されず、各クエリが独立したものとしてみなされてしまいます。一方、メモリーを用いることで過去の対話を履歴として残し、それに基づき新たな回答を生成することができるようになります。
LangChain Memoryの種類
Langchain Memoryには2種類の代表モジュールがあります。
- ConversationBufferMemory
- ConversationSummaryMemory
- ConversationBufferWindowMemory
ConversationBufferMemory
ConversationBufferMemoryとは、チャット履歴を記録するための機能です。
ユーザー(人間)・AIのメッセージをそれぞれ記録し、その記録内容をLLMが容易に参照できる機能を有しています。
ConversationSummaryMemory
ConversationSummaryMemoryとは、チャット内容を要約して記録するための機能です。
前述のConversationBufferMemory を用いて、大量のトークン履歴を保持する場合、ストレージの容量制限を受ける可能性があります。容量対策において、ConversationSummaryMemoryは有効です。
ConversationBufferWindowMemory
ConversationBufferWindowMemoryとは、ConversationBufferMemory同様、チャット履歴を記録するための機能ですが、メモリにウィンドウ機能が付属しています。
Windowとは、ユーザーとAIとの対話を最新のいくつまで記録するかを指定できる機能です。例えば、100と指定すると最新の対話100個まで記録されます。
【参考】Python 実装方法
Pythonを用いたLangChain Memoryの機能実装方法も併せて解説しています。

LangChain|Data Connection(データコネクション)
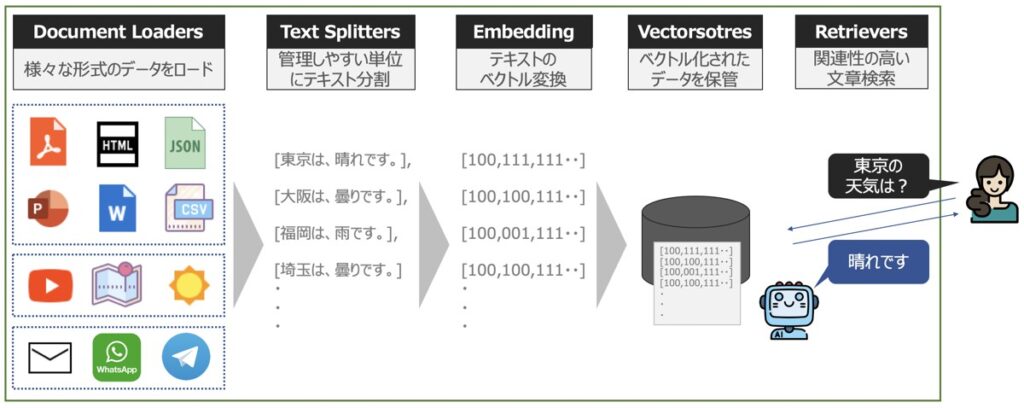
LangChain Data Connection(データコネクション)とは、言語モデルに対して外部データを新たに追加し、外部データに基づく文章の回答を生成できるようにする機能です。
ユースケース
LangChain Data Connectionは、次に示す要望を満足させるのに有効です。
- 独自で用意したドキュメントから目的の文章をChatGPT等のLLMで検索できるようにしたい。
- 特定のウェブサイトから最新情報をLLMで抽出したい。
LangChain Data Connectionの機能一覧
Langchain Data Connectionの機能を細分化すると、以下4つに分けられます。
- Document Loaders
- Document Transformers(Text Splitters)
- Embeddings
- Vector Stores
- Retrievers
Document Loaders
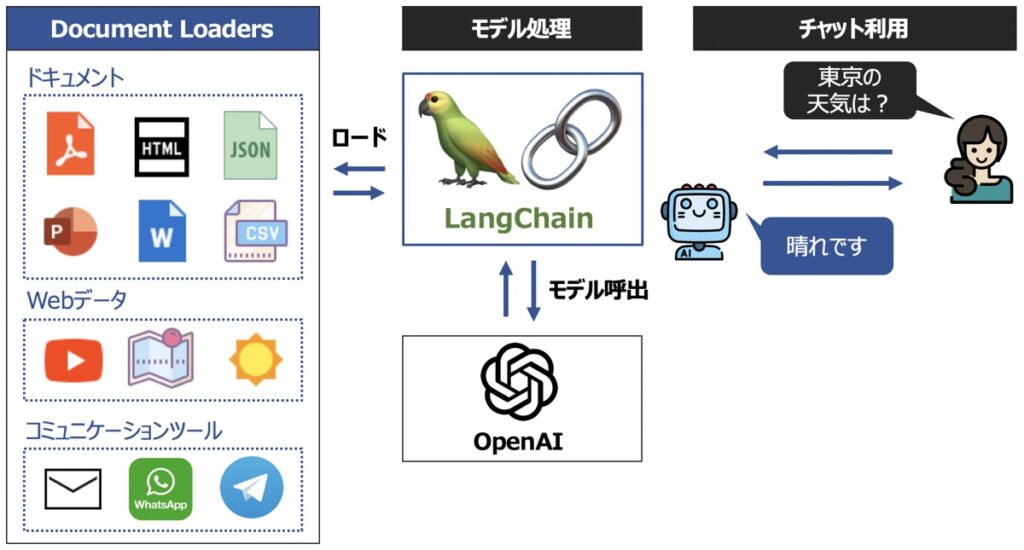
Document Loadersとは、外部データを言語モデルに読込できるようにするフォーマット機能です。
Document Loadersの機能概要
Document Loadersには、データ形式に応じて3つのLoaderが活用できます。
| Transform loaders | データを特定の形式からドキュメント形式に読込・変換する汎用機能。 |
| Public dataset or service loaders | パブリックドメインにあるデータセットの読込機能。 |
| Proprietary dataset or service loaders | プライベートドメインのデータセットの読込機能。 ※データ読込先のアクセストークンを別途入手する必要あり。 |
読込可能な外部データ一覧
Document Loadersは、現在次のようなデータの読込に対応しています。
「Transform loaders」をもとに読込可能なデータセット
Airtable
OpenAIWhisperParser
CoNLL-U
Copy Paste
CSV
Email
EPub
EverNote
Microsoft Excel
Facebook Chat
File Directory
HTML
Images
Jupyter Notebook
JSON
Markdown
Microsoft PowerPoint
Microsoft Word
Open Document Format (ODT)
Pandas DataFrame
PDF
Sitemap
Subtitle
Telegram
TOML
Unstructured File
URL
Selenium URL Loader
Playwright URL Loader
WebBaseLoader
Weather
WhatsApp Chat「Public dataset or service loaders」をもとに読込可能なデータセット
Arxiv
AZLyrics
BiliBili
College Confidential
Gutenberg
Hacker News
HuggingFace dataset
iFixit
IMSDb
MediaWikiDump
Wikipedia
YouTube transcripts「Proprietary dataset or service loaders」をもとに読込可能なデータセット
Airbyte JSON
Apify Dataset
AWS S3 Directory
AWS S3 File
Azure Blob Storage Container
Azure Blob Storage File
Blackboard
Blockchain
ChatGPT Data
Confluence
Examples
Diffbot
Docugami
DuckDB
Fauna
Figma
GitBook
Git
Google BigQuery
Google Cloud Storage Directory
Google Cloud Storage File
Google Drive
Image captions
Iugu
Joplin
Microsoft OneDrive
Modern Treasury
Notion DB
Obsidian
Psychic
PySpark DataFrame Loader
ReadTheDocs Documentation
Reddit
Roam
Slack
Snowflake
Spreedly
Stripe
2Markdown
TwitterDocument Transformers
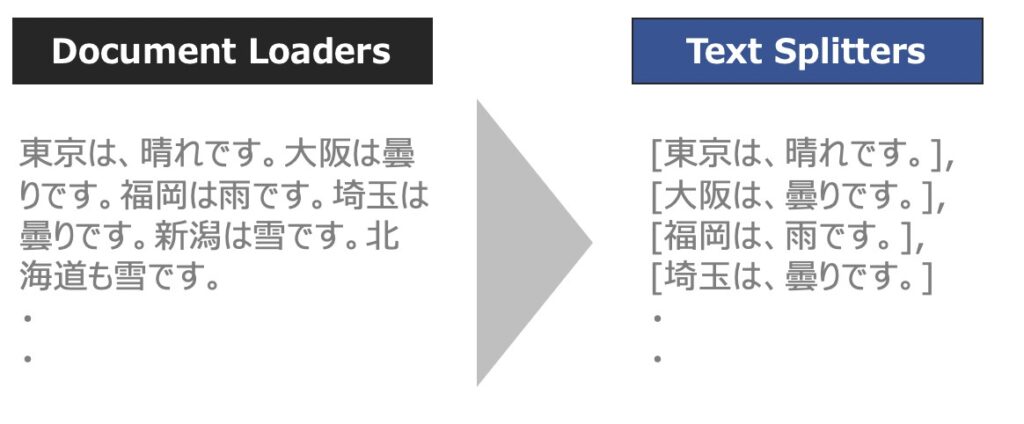
Document Transformersとは、読み込んだデータセットを管理しやすい単位にテキスト分割したり、冗長なテキストを除去することで、言語モデルの文章理解を手助けするデータ加工機能です。
Document Transformersの中でも代表的に用いられるのが、Text Splittersというテキスト分割モジュールです。以下、Text Splittersの概要を中心に解説します。
Text Splittersの役割
LLMに長いテキスト文章を投入する場合、テキストをいくつかのチャンクに分割する必要があります。この時、意味的に関連する文章は束ねて1つのチャンクとして分割できれば問題ないですが、関連する文章同士が別々のチャンクとして分割されてしてしまった場合、LLM利用時の応答性能にも悪影響を及ぼしてしまいます。
Text Splittersは、関連する文章同士を束ねて分割するのに有効な機能です。
Text Splittersによる処理の流れ
Text Splittersを用いると、以下の手順で処理がなされます。
- テキストを意味的に意味のある小さなチャンクに分割
- 特定のサイズに達するまで小さなチャンクを組み合わせて大きくしていく
Text Splittersが対応できるもの
Text Splittersは、単純なテキスト文章だけでなく、以下に示すものも分割可能です。
- テキスト文章
- コード(HTML、Python、SQL、Java、Rubyなど)
- Natural Language Toolkit(NLTK)
- OpenAI Tiktoken
Vector Stores
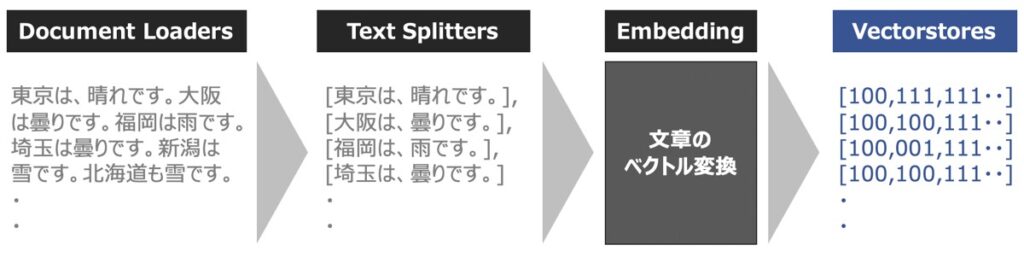
Vector Storesとは、ベクトル化された文章を管理・保管するための機能です。
前述のText Splittersをもとに分割されたテキストは、通常、Embedding関数を用いてベクトル化されます。このベクトル化されたデータをローカル環境に保存する役割をVector Storesが担います。
また、ベクトル化されたデータはローカル環境に保存することができ、データの永続化も実現できます。結果、LLMがある質問に対して決まった回答を出力することも可能になります。
Retrievers
Retrieversとは、ドキュメント検索機能です。ChatGPTが提供するLLMとの連携も可能です。
LangChain Data Connection Retrieversは、Vector Storesへのアクセスと、LLMを呼び出して意図した「データ検索」の実現に寄与します。
LangChain|Chains(チェーン)
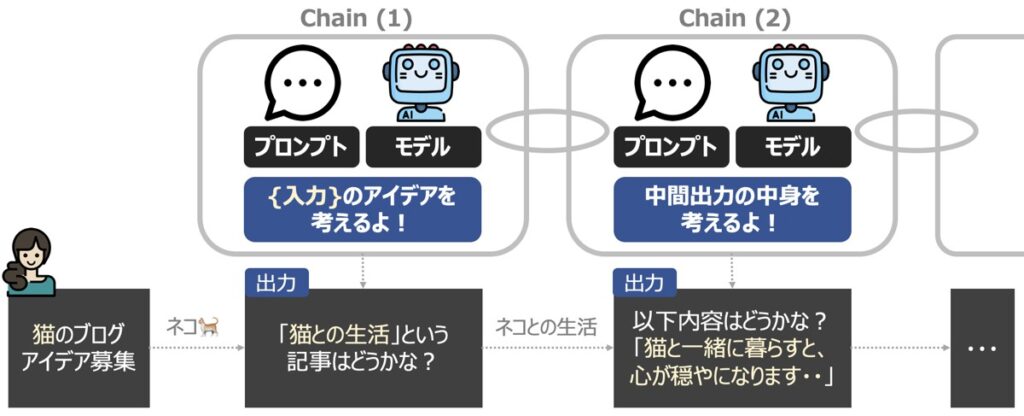
LangChain Chainsとは、文字通りチェーンを繋げて、一連の処理を連続して実行できるようにする機能です。チェーンの最小単位は、プロンプトと言語モデルをもとに構成されます。
1つのプロンプトに対して1つの回答を得るようなシンプルなタスクであれば、Chainsの機能は不要です。一方、プロンプトが複雑化したタスクは、この機能が本領を発揮します。
例えば上図のように、正確な最終出力を得るために、段階的に中間結果を出力する場合に有効です。このように、中間的な推論ステップを用いて複雑な推論能力向上させ、最終的に適切な回答を得るための手法をChain-of-Thought(COT)プロンプティングと呼びます。
Chainsの種類一覧
Langchain Chainsの機能を細分化すると、以下3つに分けられます。
- LLM Chain
- Sequential Chain
- Custom Chain
LLM Chain

LLM Chainとは、プロンプトとLLM からの構成される最小単位のチェーンです。Simple Chainとも呼ばれます。
Sequential Chain
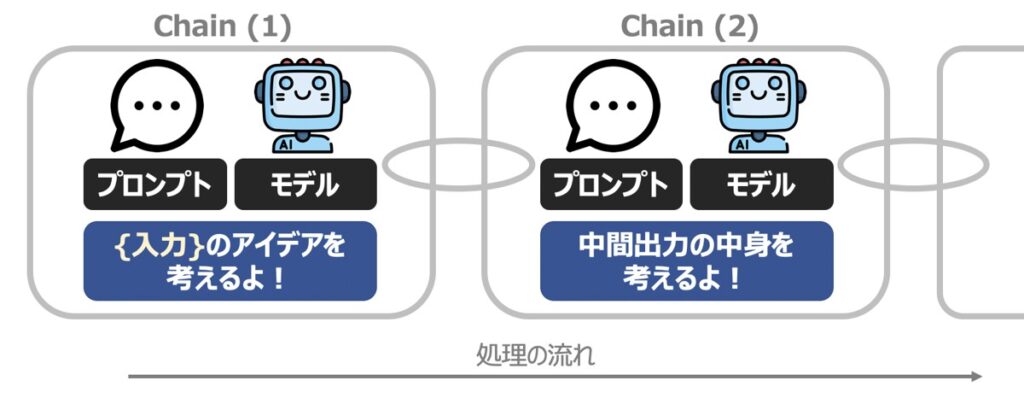
Sequential Chainとは、複数のチェーンを順番に実行するためのチェーンです。
Custom Chain
Custom Chainとは、特定のケースに対応すべく、自由に繋いだカスタマイズドなチェーンです。
Custom Chainを用いると、各Chainの入出力を細かく定義でき、複雑な質問への対応力が向上します。
【参考】Python 実装方法
Pythonを用いたLangChain Chainsの機能実装方法も併せて解説しています。

LangChain|Agents(エージェント)
LangChain Agentsとは、言語モデルを使用して、ユーザーからの要望をどんな手段・順序で実行するか決定する機能です。
Langchain Agentsの機能を細分化すると、以下4つに分けられます。
- Agent
- Tools
- Toolkit
- Agent Executor
Tools
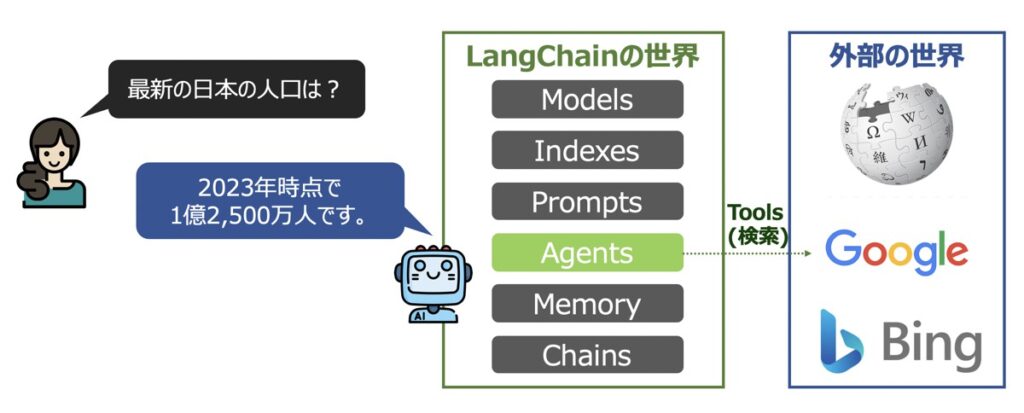
Tools(ツール)とは、エージェントが外部とやり取りをするための機能です。
Toolの参考事例
OpenAI社のGPT-4を代表とするLLMは「最新情報を知ることができない」という弱点がありました。これは、LLMが外部の世界と接続していないためです。
この問題の解決策としてLangChain Agentsが挙げられています。Agentsに用意されたToolsを用いることで、外部の世界と接続でき、最新データにアクセスできるようになるのです。
公開中のTool一覧
前述では最新データを得るためのツールを例に紹介しましたが、その他にも多数の種類のツールが公開されています。
Apify
ArXiv API Tool
AWS Lambda API
Shell Tool
Bing Search
ChatGPT Plugins
DuckDuckGo Search
File System Tools
Google Places
Google Search
Google Serper API
Gradio Tools
GraphQL tool
HuggingFace Tools
Human as a tool
Call the API
Use Metaphor as a tool
OpenWeatherMap API
Python REPL
Requests
SceneXplain
Search Tools
SerpAPI
Twilio
Wikipedia
YouTubeSearchTool
Zapier Natural Language Actions API
Example with SimpleSequentialChainAgents
Agentsとは、プロンプトの内容に基づき、言語モデルがどのようなツールを用いて、どのようなアクションを取るべきか判断してくれる機能です。
Agentsの種類
LangChain Agentsには様々な種類のAgentが用意されています。
| zero-shot-react-description | 「Toolの説明文のみ」を渡すと、どのツールを使用するか決定してくれるエージェント。 |
| react-docstore | ドキュメントを検索するための「Search Tool」と、ドキュメント内の用語を検索するための「Lookup Tool」を渡すと、 指定のドキュメントストアと対話してくれるエージェント。 |
| self-ask-with-search | 自問自答することで、Q&A精度を高めてくれるエージェント。 |
| conversational-react-description | 会話用に最適化されたエージェント。 エージェントがユーザーとのチャットを通じて、必要な時にツールの呼出ができる。 |
Toolkits
Toolkitsとは、デフォルトでツールを搭載したAgentであり、特定のユースケースに応用されています。
LangChainには現在次のようなToolkitsが公開されています。
Azure Cognitive Services Toolkit
CSV Agent
Gmail Toolkit
Jira
JSON Agent
OpenAPI agents
Natural Language APIs
Pandas Dataframe Agent
PlayWright Browser Toolkit
PowerBI Dataset Agent
Python Agent
Spark Dataframe Agent
Spark SQL Agent
SQL Database Agent
Vectorstore AgentAgent Executor
Agent Executorとは、エージェントが決定したアクションを実行するための機能です。
【参考】PythonによるLLM実装|ChatGPT・LangChain

本記事では、PythonでLLMを構築し、様々なタスクをこなす機能の実装方法を多数解説しています。
Python × ChatGPT関連記事
Python × LangChain関連記事
自然言語処理の学習におすすめの書籍

自然言語処理の概要について詳しく学びたい方向けに、厳選したおすすめの学習教材を紹介しています。
最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
