
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- ChatGPTで様々な形式の独自ドキュメントとChatGPTを連携したい。
- 上記を実現するLangChain Data Connection「Document Loaders」の概要を理解し、Pythonで実装する方法を学びたい。
LangChainとは?
LangChainとは、ChatGPTを代表とするような大規模言語モデル(LLM)の機能を拡張し、サービスとして展開する際に役立つライブラリです。
LangChainの主要機能
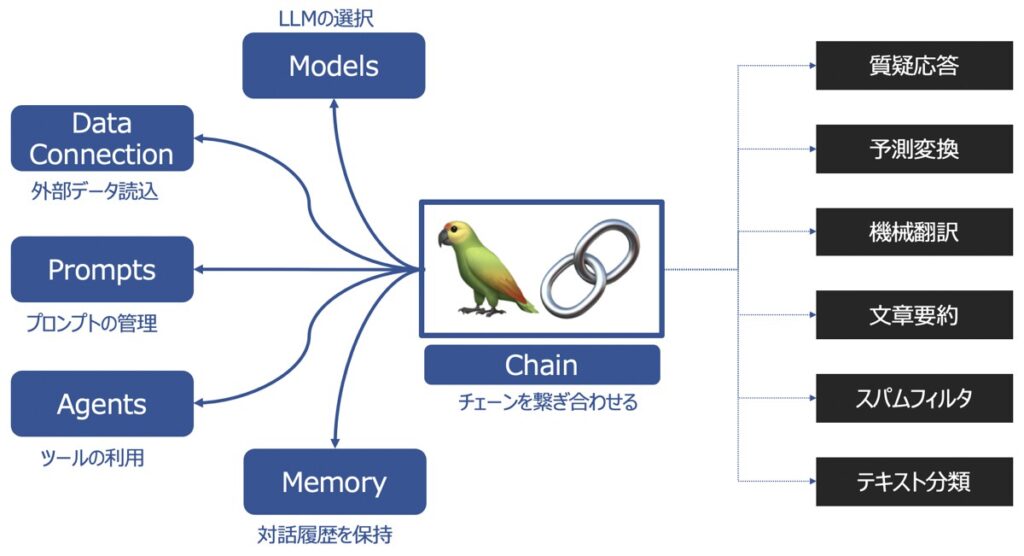
LangChainの主要な機能として以下があります。
| 主要機能 | 概要 |
|---|---|
| Models | 様々な大規模言語モデルを同じインターフェース上で取り扱えるようにする機能 |
| Prompts | プロンプトの管理、最適化、シリアル化ができる機能 |
| Memory | 言語モデルを用いてユーザーと対話した履歴を記憶する機能 |
| Data connection | 言語モデルに外部データを投入し、外部データに基づく回答を生成する機能 |
| Chains | チェーンを複数繋げて、一連の処理を連続実行する機能 |
| Agents | ユーザーからの要望をどんな手段・順序で応えるか決定・実行する機能 |
LangChainの各種機能の詳細を知りたい方は、こちらの記事をご覧下さい。

【参考】LangChainを用いたプログラミング実装におすすめの学習教材
LangChainライブラリを用いてプログラミングし、アプリケーションを実装したい方向けに、おすすめの学習教材をご紹介します。
LangChain Data Connection|Document Loadersとは?
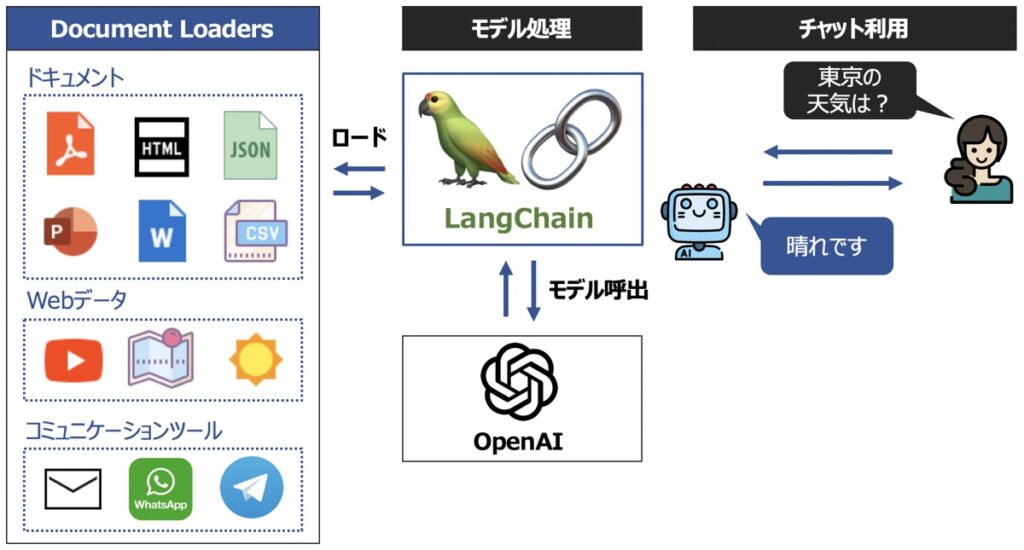
Document Loadersとは、外部データを言語モデルに読込できるようにするフォーマット機能です。
本記事では、「LangChain Document Loadersを用いて様々な形式のドキュメントを読み込み、OpenAI社の大規模言語モデルを用いて、ユーザーの質問に回答するPythonプログラムの構築方法」について解説します。
【事前準備】Pythonライブラリインストール・OpenAI API情報取得
「LangChain Document Loadersを用いて様々な形式のドキュメントを読み込み」に際して、必要な準備2点を実施しましょう。
Pythonライブラリのインストール
Pythonプログラム実装に際して、以下に示すライブラリを事前にインストールします。
入力ドキュメントの形式に応じてインストールすべきライブラリが異なる点に考慮が必要です。
| ライブラリ概要 | インストール方法 | 必須/任意 |
|---|---|---|
| OpenAI社のGPT API利用 | pip install –upgrade openai | 必須 |
| LangChainライブラリ | pip install langchain | 必須 |
| ベクトル変換された文章検索 | pip install faiss-cpu | 必須 |
| SSL認証 | pip install pyopenssl –upgrade | 必須 |
| 【データ読込】PDF | pip install pypdf | 任意 |
| 【データ読込】Microsoft Word | pip install docx2txt | 任意 |
| 【データ読込】ウェブ上のデータ | pip install selenium, unstructured | 任意 |
【ChatGPT】OpenAI社のAPI発行
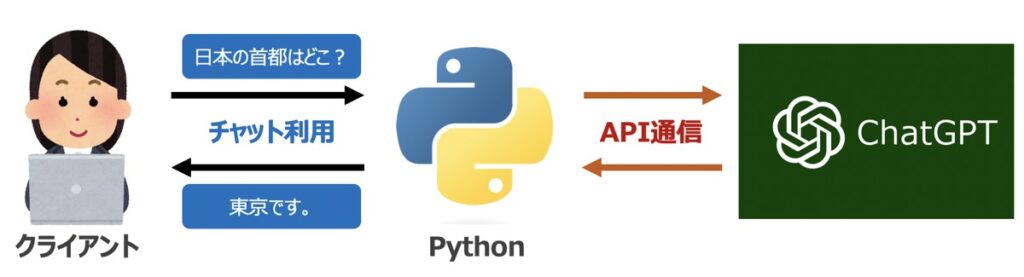
LangChain機能構築に際して、OpenAI社が提供するGPTモデルをAPI経由で呼び出す必要があります。
OpenAI社の公式サイトから「API シークレットキー」を事前に発行しておきましょう。なお、シークレットキーの発行方法はこちらの記事で詳しく解説しています。
【Python実践】LangChain データロード関数の作成(共通)
ここから実際に「様々なドキュメントから目的の文章を、OpenAI社(ChatGPT)の大規模言語モデル経由で、検索できる機能」をPythonで構築します。
はじめに、全てのドキュメント検索に共通して必要とコンポーネントを以下に記述します。Pythonファイルの先頭に配置しましょう。
【共通】Pythonライブラリのインストール
Pythonファイルの先頭に以下のプログラムを配置し、OpenAI社のサイトから取得したシークレットキーを記述しましょう。
import openai
import os
# APIシークレットキーを記述
SECRET_KEY = "............."
# API認証情報設定
os.environ["OPENAI_API_KEY"] = SECRET_KEY【共通】ドキュメントローダー関数作成
加えて、様々なドキュメントをロードする際に有効な関数を配置します。
第一引数に検索クエリquery、第二引数に検索件数num、第三引数に後述するドキュメントローダーloaderを指定した以下の関数を記述しましょう。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
# ================================================================================
# 関数作成
# ================================================================================
def document_loader(query, num, loader):
# データロード
loaded_data = loader.load_and_split()
# 検索オブジェクト
faiss_index = FAISS.from_documents(loaded_data, # document_loaderでロードしたデータ
OpenAIEmbeddings(), # 文章の分散表現を作成するEmbeddingモデル
)
# 検索結果
results = faiss_index.similarity_search(
query, # 入力クエリ
k=num, # 指定した数だけ検索結果を抽出
)
return results【Python】「PDF」から目的文書をChatGPTで検索
前述で配置したPythonライブラリ、OpenAI社のAPI認証情報およびドキュメントローダー関数を用いて、「PDFから目的の文書を検索する機能」を作成します。
コード
ChatGPTと連携するPDFのファイルパスfilepath、検索内容query、検索出力件数num、PDF読込用のドキュメントローダーPyPDFLoader()を関数に渡して実行します。
from langchain.document_loaders import PyPDFLoader
# ================================================================================
# 入力ドキュメント
# ================================================================================
# サンプルファイルパス
filepath = "https://di-acc2.com/wp-content/uploads/2023/06/tokyo_travel.pdf"
# 検索内容
query = "東京の観光名所「スカイツリー」について教えて"
# ================================================================================
# 関数実行
# ================================================================================
# Document Loader実行
results = document_loader(query = query, # 入力クエリ
num = 1, # 出力したい検索結果数
loader = PyPDFLoader(filepath), # PDF Loader
)
# ================================================================================
# 結果出力
# ================================================================================
# 出力
for result in results:
print("【Page】\n" + str(result.metadata["page"]))
print("【Content】\n" + str(result.page_content))出力イメージ
上記を実行すると、次のような出力結果が得られます。
# 出力イメージ
# 【Page】
# 1
# 【Content】
# 2. 東京スカイツリー - 東京都内でも最も高い建物で、展望台からは絶景が見られる - ショッピングやグルメも楽しめる【Python】「Microsoft Word」から目的文書をChatGPTで検索
前述で配置したPythonライブラリ、OpenAI社のAPI認証情報およびドキュメントローダー関数を用いて、「Microsoft Wordから目的の文書を検索する機能」を作成します。
コード
ChatGPTと連携するMicrosoft Wordのファイルパスfilepath、検索内容query、検索出力件数num、Microsoft Word読込用のドキュメントローダーDocx2txtLoader()を関数に渡して実行します。
from langchain.document_loaders import Docx2txtLoader
# ================================================================================
# 入力ドキュメント
# ================================================================================
# サンプルファイルパス
filepath = "https://di-acc2.com/wp-content/uploads/2023/06/tokyo_travel.docx"
# 検索内容
query = "東京の観光名所「スカイツリー」について教えて"
# ================================================================================
# 関数実行
# ================================================================================
# Document Loader実行
results = document_loader(query = query, # 入力クエリ
num = 1, # 出力したい検索結果数
loader = Docx2txtLoader(filepath), # Microsoft Word Loader
)
# ================================================================================
# 結果出力
# ================================================================================
# 出力
for result in results:
print("【Content】\n" + str(result.page_content))出力イメージ
上記を実行すると、次のような出力結果が得られます。
# 出力イメージ
# 【Content】
# 東京都の観光名所
# 1. 浅草寺
# - 東京都内でも有数の観光スポットで、日本文化や歴史を感じられる
# - 仲見世通りにはお土産屋や飲食店が多く、楽しめる
# 2. 東京スカイツリー
# - 東京都内でも最も高い建物で、展望台からは絶景が見られる
# - ショッピングやグルメも楽しめる
# 3. 新宿御苑
# - 都心にありながら、自然豊かな公園で四季折々の景色が楽しめる
# - 早朝にはジョギングや散歩をする人々が多く、リフレッシュできる【Python】「テキストファイル」から目的文書をChatGPTで検索
前述で配置したPythonライブラリ、OpenAI社のAPI認証情報およびドキュメントローダー関数を用いて、「テキストファイルから目的の文書を検索する機能」を作成します。
【参考】テキストファイルダウンロード
テキストファイルのサンプルデータを配布していますので、必要に応じてご利用ください。ダウンロードしたテキストファイルは後述コードのfilepath部分に指定します。
コード
ChatGPTと連携するテキストファイルのパスfilepath、検索内容query、検索出力件数num、テキスト読込用のドキュメントローダーTextLoader()を関数に渡して実行します。
from langchain.document_loaders import TextLoader
# ================================================================================
# 入力ドキュメント
# ================================================================================
# ファイルパス
filepath = 'travel_tokyo.txt'
# 検索内容
query = "東京の観光名所「スカイツリー」について教えて"
# ================================================================================
# 関数実行
# ================================================================================
# Document Loader実行
results = document_loader(query = query, # 入力クエリ
num = 1, # 出力したい検索結果数
loader = TextLoader(filepath), # Text Loader
)
# ================================================================================
# 結果出力
# ================================================================================
# 出力
for result in results:
print("【Content】\n" + str(result.page_content))出力イメージ
上記を実行すると、次のような出力結果が得られます。
# 出力イメージ
# 【Content】
# 東京都の観光名所
# 1. 浅草寺
# - 東京都内でも有数の観光スポットで、日本文化や歴史を感じられる
# - 仲見世通りにはお土産屋や飲食店が多く、楽しめる
# 2. 東京スカイツリー
# - 東京都内でも最も高い建物で、展望台からは絶景が見られる
# - ショッピングやグルメも楽しめる
# 3. 新宿御苑
# - 都心にありながら、自然豊かな公園で四季折々の景色が楽しめる
# - 早朝にはジョギングや散歩をする人々が多く、リフレッシュできる【Python】「CSVファイル」から目的文書をChatGPTで検索
前述で配置したPythonライブラリ、OpenAI社のAPI認証情報およびドキュメントローダー関数を用いて、「CSVファイルから目的の文書を検索する機能」を作成します。
【参考】CSVファイルダウンロード
CSVサンプルファイル(utf-8)を配布していますので、必要に応じてご利用ください。ダウンロードしたCSVファイルは後述コードのfilepath部分に指定します。
コード
ChatGPTと連携するCSVファイルのパスfilepath、検索内容query、検索出力件数num、テキスト読込用のドキュメントローダーTextLoader()を関数に渡して実行します。
from langchain.document_loaders.csv_loader import CSVLoader
# ================================================================================
# 入力ドキュメント
# ================================================================================
# ファイルパス
filepath = "fruits_data.csv"
# 検索内容
query = "みかんの価格が知りたい"
# ================================================================================
# 関数実行
# ================================================================================
# Document Loader実行
results = document_loader(query = query, # 入力クエリ
num = 1, # 出力したい検索結果数
loader = CSVLoader(filepath), # CSV Loader
)
# ================================================================================
# 結果出力
# ================================================================================
# 出力
for result in results:
print("【Row】\n" + str(result.metadata["row"]))
print("【Content】\n" + str(result.page_content))出力イメージ
上記を実行すると、次のような出力結果が得られます。
# 出力イメージ
#【Row】
# 2
#【Content】
# 商品名: みかん
# 価格: 130
# 数量: 30【Python】「特定のWebサイト」から目的文書をChatGPTで検索
前述で配置したPythonライブラリ、OpenAI社のAPI認証情報およびドキュメントローダー関数を用いて、「特定のWebサイトから目的の文書を検索する機能」を作成します。
コード
ChatGPTと連携するWebサイトのURLパスurls、検索内容query、検索出力件数num、URL読込用ローダーSeleniumURLLoader()を関数に渡して実行します。
今回の例ではGoogle Map上のデータに問い合わせて目的の文章を抽出します。
from langchain.document_loaders import SeleniumURLLoader
# ================================================================================
# 入力ドキュメント
# ================================================================================
# URLs(複数URLの指定も可能)
urls = [
"https://goo.gl/maps/PEt4NFeBYV6REuXm9", # Google Map(東京タワー)
"https://goo.gl/maps/gvXvbikKNV7toHYQ7", # Google Map(スカイツリー)
]
query = "東京タワーの位置情報が知りたい"
# ================================================================================
# 関数実行
# ================================================================================
# Document Loader実行
results = document_loader(query = query, # 入力クエリ
num = 1, # 出力したい検索結果数
loader = SeleniumURLLoader( # SeleniumURLLoader
urls=urls, # ロードするURL
browser="firefox", # Seleniumが起動するブラウザ("chrome" or "firefox")
),
)
# ================================================================================
# 結果出力
# ================================================================================
# 出力
for result in results:
print("【Source】\n" + str(result.metadata["source"]))
print("【Content】\n" + str(result.page_content))出力イメージ
上記を実行すると、次のような出力結果が得られます。
# 【Source】
# https://goo.gl/maps/PEt4NFeBYV6REuXm9
# 【Content】
# Tokyo Tower
# 4.4(62,916)
# 観光名所
# 4 Chome-2-8 Shibakoen
# Well-known tower with observation areas
# Open ⋅ Closes 10:30 PM
# ・・・・・【まとめ】LangChain×ChatGPTモデルを用いて文書検索精度を改善
様々なドキュメントを読み込み、目的の文書を検索できるようにする方法について解説しました。
一方で、今回利用したDocument Loadersのみでは、検索性能が低いという課題があります。
言語モデルが理解しやすいように読み込んだデータを加工したり、ChatGPTの言語モデルと連携できると、より高精度な検索性能が得られるでしょう。当サイトでは、Document Loadersにこれらの機能拡張を実現する方法についても併せて解説しています。

【参考】PythonによるLLM実装|ChatGPT・LangChain

本記事では、PythonでLLMを構築し、様々なタスクをこなす機能の実装方法を多数解説しています。
Python × ChatGPT関連記事
Python × LangChain関連記事
自然言語処理の学習におすすめの書籍

自然言語処理の概要について詳しく学びたい方向けに、厳選したおすすめの学習教材を紹介しています。
