
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- 社内・独自のドキュメントから目的の文章をChatGPT経由で検索したい。
- 上記をPythonと実現できる「LangChain Data Connection」という機能について詳しく知りたい。
LangChainとは?
LangChainとは、ChatGPTを代表とするような大規模言語モデル(LLM)の機能を拡張し、サービスとして展開する際に役立つライブラリです。
LangChainの主要機能
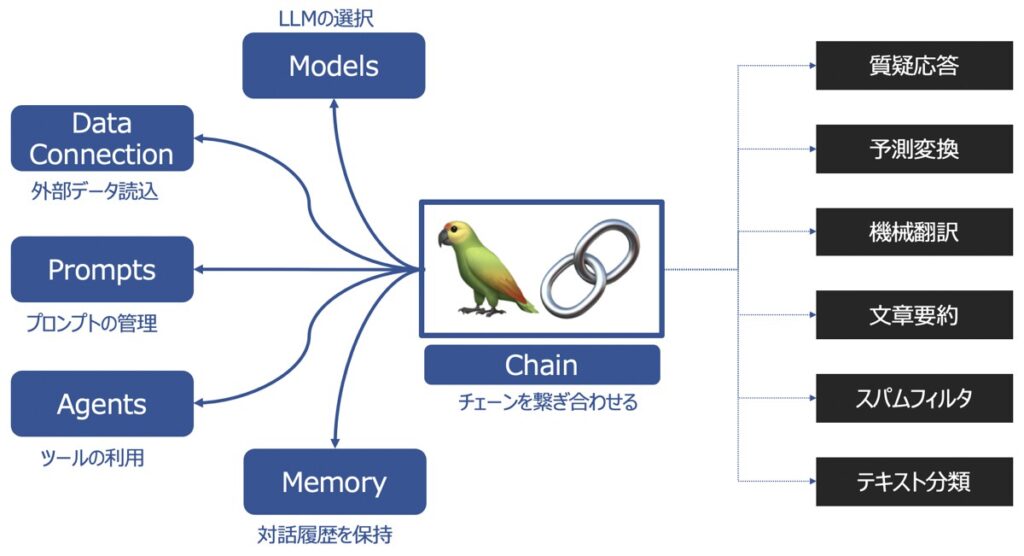
LangChainの主要な機能として以下があります。
| 主要機能 | 概要 |
|---|---|
| Models | 様々な大規模言語モデルを同じインターフェース上で取り扱えるようにする機能 |
| Prompts | プロンプトの管理、最適化、シリアル化ができる機能 |
| Memory | 言語モデルを用いてユーザーと対話した履歴を記憶する機能 |
| Data connection | 言語モデルに外部データを投入し、外部データに基づく回答を生成する機能 |
| Chains | チェーンを複数繋げて、一連の処理を連続実行する機能 |
| Agents | ユーザーからの要望をどんな手段・順序で応えるか決定・実行する機能 |
LangChainの各種機能の詳細を知りたい方は、こちらの記事をご覧下さい。

【参考】LangChainを用いたプログラミング実装におすすめの学習教材
LangChainライブラリを用いてプログラミングし、アプリケーションを実装したい方向けに、おすすめの学習教材をご紹介します。
LangChain|Data Connection(データコネクション)
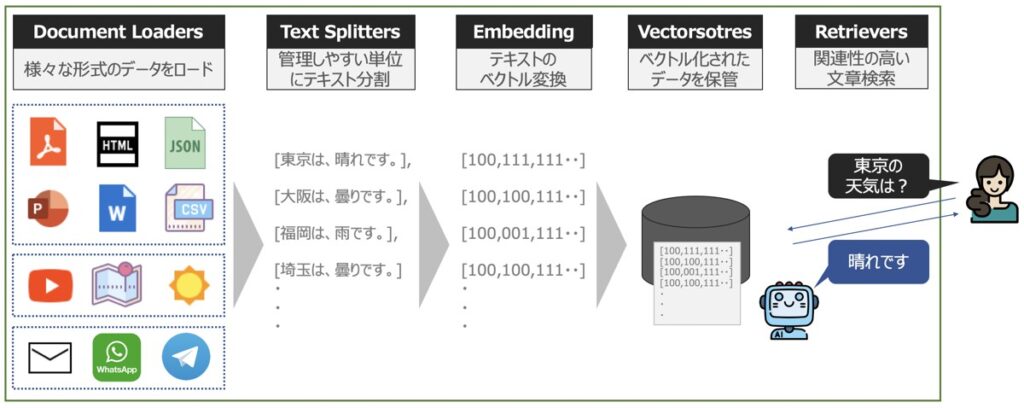
LangChain Data Connection(データコネクション)とは、言語モデルに対して外部データを新たに追加し、外部データに基づく文章の回答を生成できるようにする機能です。
ユースケース
LangChain Data Connectionは、次に示す要望を満足させるのに有効です。
- 独自で用意したドキュメントから目的の文章をChatGPT等のLLMで検索できるようにしたい。
- 特定のウェブサイトから最新情報をLLMで抽出したい。
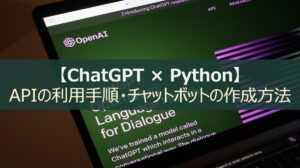
LangChain Data Connectionの機能一覧
Langchain Data Connectionの機能を細分化すると、以下4つに分けられます。
- Document Loaders
- Document Transformers(Text Splitters)
- Embeddings
- Vector Stores
- Retrievers
Document Loaders
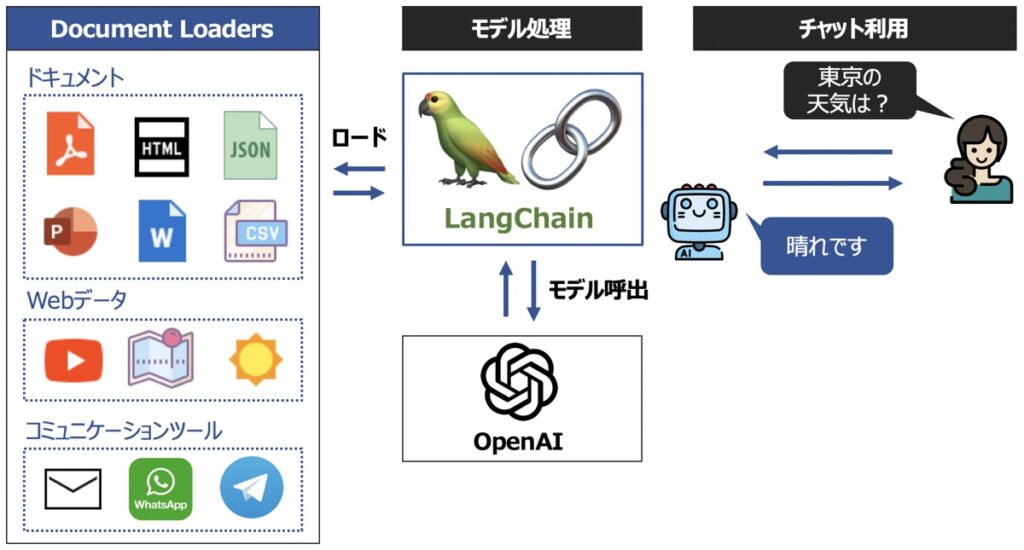
Document Loadersとは、外部データを言語モデルに読込できるようにするフォーマット機能です。
Document Loadersの機能概要
Document Loadersには、データ形式に応じて3つのLoaderが活用できます。
| Transform loaders | データを特定の形式からドキュメント形式に読込・変換する汎用機能。 |
| Public dataset or service loaders | パブリックドメインにあるデータセットの読込機能。 |
| Proprietary dataset or service loaders | プライベートドメインのデータセットの読込機能。 ※データ読込先のアクセストークンを別途入手する必要あり。 |
読込可能な外部データ一覧
Document Loadersは、現在次のようなデータの読込に対応しています。
「Transform loaders」をもとに読込可能なデータセット
Airtable
OpenAIWhisperParser
CoNLL-U
Copy Paste
CSV
Email
EPub
EverNote
Microsoft Excel
Facebook Chat
File Directory
HTML
Images
Jupyter Notebook
JSON
Markdown
Microsoft PowerPoint
Microsoft Word
Open Document Format (ODT)
Pandas DataFrame
PDF
Sitemap
Subtitle
Telegram
TOML
Unstructured File
URL
Selenium URL Loader
Playwright URL Loader
WebBaseLoader
Weather
WhatsApp Chat「Public dataset or service loaders」をもとに読込可能なデータセット
Arxiv
AZLyrics
BiliBili
College Confidential
Gutenberg
Hacker News
HuggingFace dataset
iFixit
IMSDb
MediaWikiDump
Wikipedia
YouTube transcripts「Proprietary dataset or service loaders」をもとに読込可能なデータセット
Airbyte JSON
Apify Dataset
AWS S3 Directory
AWS S3 File
Azure Blob Storage Container
Azure Blob Storage File
Blackboard
Blockchain
ChatGPT Data
Confluence
Examples
Diffbot
Docugami
DuckDB
Fauna
Figma
GitBook
Git
Google BigQuery
Google Cloud Storage Directory
Google Cloud Storage File
Google Drive
Image captions
Iugu
Joplin
Microsoft OneDrive
Modern Treasury
Notion DB
Obsidian
Psychic
PySpark DataFrame Loader
ReadTheDocs Documentation
Reddit
Roam
Slack
Snowflake
Spreedly
Stripe
2Markdown
TwitterDocument Transformers
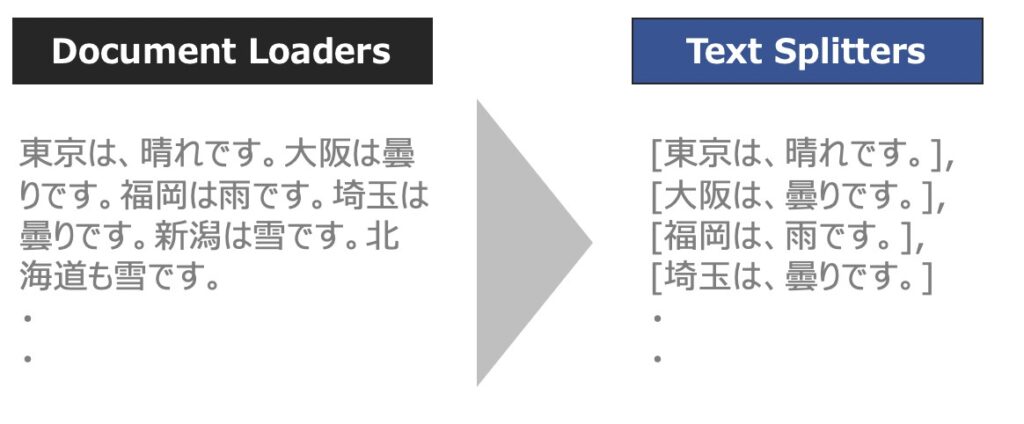
Document Transformersとは、読み込んだデータセットを管理しやすい単位にテキスト分割したり、冗長なテキストを除去することで、言語モデルの文章理解を手助けするデータ加工機能です。
Document Transformersの中でも代表的に用いられるのが、Text Splittersというテキスト分割モジュールです。以下、Text Splittersの概要を中心に解説します。
Text Splittersの役割
LLMに長いテキスト文章を投入する場合、テキストをいくつかのチャンクに分割する必要があります。この時、意味的に関連する文章は束ねて1つのチャンクとして分割できれば問題ないですが、関連する文章同士が別々のチャンクとして分割されてしてしまった場合、LLM利用時の応答性能にも悪影響を及ぼしてしまいます。
Text Splittersは、関連する文章同士を束ねて分割するのに有効な機能です。
Text Splittersによる処理の流れ
Text Splittersを用いると、以下の手順で処理がなされます。
- テキストを意味的に意味のある小さなチャンクに分割
- 特定のサイズに達するまで小さなチャンクを組み合わせて大きくしていく
Text Splittersが対応できるもの
Text Splittersは、単純なテキスト文章だけでなく、以下に示すものも分割可能です。
- テキスト文章
- コード(HTML、Python、SQL、Java、Rubyなど)
- Natural Language Toolkit(NLTK)
- OpenAI Tiktoken
Vector Stores
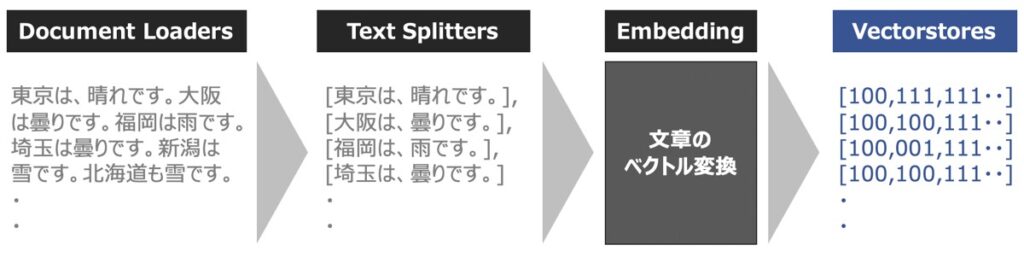
Vector Storesとは、ベクトル化された文章を管理・保管するための機能です。
前述のText Splittersをもとに分割されたテキストは、通常、Embedding関数を用いてベクトル化されます。このベクトル化されたデータをローカル環境に保存する役割をVector Storesが担います。
また、ベクトル化されたデータはローカル環境に保存することができ、データの永続化も実現できます。結果、LLMがある質問に対して決まった回答を出力することも可能になります。
Retrievers
Retrieversとは、ドキュメント検索機能です。ChatGPTが提供するLLMとの連携も可能です。
LangChain Data Connection Retrieversは、Vector Storesへのアクセスと、LLMを呼び出して意図した「データ検索」の実現に寄与します。
【事前準備】Python環境構築・ChatGPT API取得
PythonとLangChain Data Connectionを用いて「独自で用意したドキュメントから目的の文章を検索できる機能」を構築します。そのために必要な事前準備を3点実施しましょう。
Pythonライブラリのインストール
プログラム実装に際して、以下に示すライブラリをインストールしましょう。
OpenAI
ChatGPTを代表とするOpenAI社のAPIをPython環境から呼び出すためのライブラリです。
pip install openai --upgradeLangChain
LangChainに搭載された機能の利用に際して必要なライブラリです。
pip install langchainfaiss-cpu
ベクトル変換されたテキストデータから目的の情報抽出する際に役立つライブラリです。
pip install faiss-cpu【ChatGPT】OpenAI社のAPI発行
LangChain機能構築に際して、OpenAI社が提供するGPTモデルをAPI経由で呼び出す必要があります。
OpenAI社の公式サイトから「API シークレットキー」を事前に発行しておきましょう。なお、シークレットキーの発行方法はこちらの記事で詳しく解説しています。
Pythonライブラリの読み込み
後述するプログラムは全てOpenAI社のAPI情報を利用します。
以下のPythonプログラムを先頭に配置し、OpenAI社のサイトから取得したシークレットキーを自身のものに書き換えましょう。
import openai
import os
# APIシークレットキーを記述
SECRET_KEY = "............."
# API認証情報設定
os.environ["OPENAI_API_KEY"] = SECRET_KEY【Python】LangChain Document Loadersの利用方法
「Document Loadersを用いて様々な形式のドキュメントを読み込み、目的の文章を検索する方法」について解説します。
文書検索に必要なPythonライブラリ
以下ではPDFから目的の文章を検索する方法を解説します。
PDFの読み込みに必要なPythonライブラリを追加でインストールする必要があります。
pip install pypdfコード
PDFファイルのパスfilepathと検索したい内容queryを指定した以下のコードを実行します。
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
# ================================================================================
# 入力ドキュメント
# ================================================================================
# サンプルファイルパス
filepath = "https://di-acc2.com/wp-content/uploads/2023/06/tokyo_travel.pdf"
# 検索内容
query = "東京の観光名所「スカイツリー」について教えて"
# ================================================================================
# 文書検索
# ================================================================================
# Document Loader実行
loader = PyPDFLoader(filepath)
# データロード
loaded_data = loader.load_and_split()
# 検索オブジェクト
faiss_index = FAISS.from_documents(loaded_data, # document_loaderでロードしたデータ
OpenAIEmbeddings(), # 文章の分散表現を作成するEmbeddingモデル
)
# 検索結果
results = faiss_index.similarity_search(
query, # 入力クエリ
k=1, # 指定した数だけ検索結果を抽出
)
# ================================================================================
# 結果出力
# ================================================================================
# 出力
for result in results:
print("【Page】\n" + str(result.metadata["page"]))
print("【Content】\n" + str(result.page_content))出力イメージ
# 検索内容
# "東京の観光名所「スカイツリー」について教えて"
# 出力イメージ
# 【Page】
# 1
# 【Content】
# 2. 東京スカイツリー - 東京都内でも最も高い建物で、展望台からは絶景が見られる - ショッピングやグルメも楽しめる【参考】LangChain DocumentLoadersを用いた様々な文書読込
今回PDFを例に解説しましたが、それ以外にもテキストファイル、CSV、Microsoft Word、特定のWebサイトなどから目的の文章をDocument Loaders経由で接続できます。
Document Loadersの使い方は、情報量が多い理由からこちらの記事でも別途詳しく解説しています。

【Python】LangChain Document Transformersの利用方法
Document Transformersの主要機能である「Text Splitters」について解説します。
これは、前述のDocument Loadersから読み込んだデータを「管理しやすい単位に分割」できる機能です。以下のコードを実行してみましょう。
コード
from langchain.text_splitter import CharacterTextSplitter
# ================================================================================
# 入力情報
# ================================================================================
data = \
"""
東京都の観光名所
1. 浅草寺
- 東京都内でも有数の観光スポットで、日本文化や歴史を感じられる
- 仲見世通りにはお土産屋や飲食店が多く、楽しめる
2. 東京スカイツリー
- 東京都内でも最も高い建物で、展望台からは絶景が見られる
- ショッピングやグルメも楽しめる
3. 新宿御苑
- 都心にありながら、自然豊かな公園で四季折々の景色が楽しめる
- 早朝にはジョギングや散歩をする人々が多く、リフレッシュできる
4. 明治神宮
- 東京都内でも有数の神社で、参拝や神楽などが楽しめる
- 境内には美しい自然が広がり、散策にも最適
5. お台場
- 東京湾に面したエリアで、夜景や海風が気持ち良い
- ショッピングやレストラン、遊園地などがあり、家族で楽しめる
"""
# ================================================================================
# Text Splitterを定義
# ================================================================================
# テキスト分割オブジェクト
text_splitter = CharacterTextSplitter(
separator = "\n\n", # テキスト分割の基準を指定
chunk_size = 100, # チャンクの最大サイズ
chunk_overlap = 0, # チャンク間のオーバーラップ。チャンク間の連続性の維持に有効
length_function = len, # チャンクの長さの計算方法。デフォルト(len)は単純な文字数カウント
)
# テキスト分割の実行
texts = text_splitter.create_documents([data])
# ================================================================================
# 結果を出力
# ================================================================================
# 出力
for text in texts:
print(text.page_content)
print("---------------------")出力イメージ
出力結果を見ると、入力データが意味のある塊として正しく分割されていることが分かります。
# 出力イメージ
# 東京都の観光名所
# ---------------------
# 1. 浅草寺
# - 東京都内でも有数の観光スポットで、日本文化や歴史を感じられる
# - 仲見世通りにはお土産屋や飲食店が多く、楽しめる
# ---------------------
# 2. 東京スカイツリー
# - 東京都内でも最も高い建物で、展望台からは絶景が見られる
# - ショッピングやグルメも楽しめる
# ---------------------
# 3. 新宿御苑
# - 都心にありながら、自然豊かな公園で四季折々の景色が楽しめる
# - 早朝にはジョギングや散歩をする人々が多く、リフレッシュできる
# ---------------------
# 4. 明治神宮
# - 東京都内でも有数の神社で、参拝や神楽などが楽しめる
# - 境内には美しい自然が広がり、散策にも最適
# ---------------------
# 5. お台場
# - 東京湾に面したエリアで、夜景や海風が気持ち良い
# - ショッピングやレストラン、遊園地などがあり、家族で楽しめる
# ---------------------【Python】LangChain Vector Storesの利用方法
OpenAI社が提供するEmbeddingsモデルを用いてテキストデータをベクトル変換し、その変換データをLangChain Vector Storesで管理する方法を解説します。
【準備】Pythonライブラリのインストール
Vector Storesを用いて、ベクトル変換したデータをChromaDBというデータベースに保存します。
Python環境でのChromaDBを利用する際は、以下のライブラリをインストールする必要があります。
pip install chromadb【参考】テキストファイルダウンロード
テキストファイルのサンプルデータを配布していますので、必要に応じてご利用ください。ダウンロードしたテキストファイルは後述コードのfilepath部分に指定します。
LangChain Vector Stores
次のコードは、以下の流れで処理しています。
Document Loaderを用いてテキストデータを読込。- 読み込んだデータを
Text Splitterで分割。 - 分割したテキストデータを
OpenAIEmbeddings関数でベクトル変換。 - ベクトル変換したデータを
Vector Storesで管理。 Vector Storesに対して問い合わせを行い、目的の文章を検索。
コード|メイン
前述の1〜4に該当するコードを以下に示します。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import TextLoader
from langchain.indexes import VectorstoreIndexCreator
# ================================================================================
# 1 Document Loaderを用いてデータロード
# ================================================================================
# テキストファイル
filepath = 'travel_tokyo.txt'
# データロード
loader = TextLoader(filepath)
# ================================================================================
# 2 Text Splitterを用いてデータベースに格納するためにデータ加工
# ================================================================================
# テキスト分割オブジェクト
text_splitter = CharacterTextSplitter(
separator = "\n\n", # テキスト分割の基準を指定
chunk_size = 1000, # チャンクの最大サイズ
chunk_overlap = 0, # チャンク間のオーバーラップ。チャンク間の連続性の維持に有効
length_function = len, # チャンクの長さの計算方法。デフォルト(len)は単純な文字数カウント
)
# ================================================================================
# 3 テキスト文章をベクトル変換するEmbedding関数作成
# ================================================================================
embeddings = OpenAIEmbeddings()
# ================================================================================
# 4 ベクトル化されたデータ管理オブジェクト作成
# ================================================================================
# VectorstoreIndexCreator
index = VectorstoreIndexCreator(
vectorstore_cls = Chroma, # データを管理するデータベース
embedding = OpenAIEmbeddings(), # Embedding関数
text_splitter = text_splitter, # テキスト分割関数
).from_loaders([loader])コード|検索実行
前述のコードで作成したVector Storeオブジェクトindexに対して、問い合わせを行い、目的の文章を検索するコードを以下に示します。
# ================================================================================
# 5 Vector Storesから目的の文章検索
# ================================================================================
# 検索クエリ
query = "スカイツリーの概要"
# 検索結果
result = index.query(query)出力イメージ
# ================================================================================
# 結果出力
# ================================================================================
# 出力
print(result)
# 出力イメージ
# 東京都内でも最も高い建物で、展望台からは絶景が見られる。ショッピングやグルメも楽しめる。ベクトル変換後のテキストデータをローカルに保存する
ベクトル変換したテキストデータをローカル環境に保存する方法も併せて解説します。保存の流れは以下の手順で実施します。
Document Loaderを用いてテキストデータを読込。- 読み込んだデータを
Text Splitterで分割。 - 分割したテキストデータを
OpenAIEmbeddings関数でベクトル変換。 ChromaDB内にベクトル変換したデータを持たせてローカルに保存。
コード
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import TextLoader
from langchain.indexes import VectorstoreIndexCreator
# ================================================================================
# 1 Document Loaderを用いてデータロード
# ================================================================================
# テキストファイル
filepath = 'data/travel_tokyo.txt'
# データロード
loader = TextLoader(filepath)
loaded_document = loader.load()
# ================================================================================
# 2 Text Splitterを用いてデータベースに格納するためにデータ加工
# ================================================================================
# テキスト分割オブジェクト
text_splitter = CharacterTextSplitter(
separator = "\n\n", # テキスト分割の基準を指定
chunk_size = 100, # チャンクの最大サイズ
chunk_overlap = 0, # チャンク間のオーバーラップ。チャンク間の連続性の維持に有効
length_function = len, # チャンクの長さの計算方法。デフォルト(len)は単純な文字数カウント
)
# テキスト分割実行
documents = text_splitter.split_documents(loaded_document)
# ================================================================================
# 3 テキスト文章をベクトル変換するEmbedding関数作成
# ================================================================================
embeddings = OpenAIEmbeddings()
# ================================================================================
# 4 ベクトル化されたデータを保管するデータベースを作成&ローカルに保存
# ================================================================================
# データベースの保存先
db_dir = 'db'
# ChromaDB作成
db = Chroma.from_documents(
documents = documents, # テキスト分割済データ
embedding = embeddings, # Embeddings関数
persist_directory = db_dir, # データベースの保存先
)
# ローカルに書き込み
db.persist()
db = NoneChromaDB関連フォルダの生成イメージ
上記コードを実行することで、Pythonファイルと同じディレクトリにdbというChromaDB関連フォルダが生成されます。フォルダ構成イメージも併せて記載します。
db
|
--- chroma-collections.parquet
|
--- chroma-embeddings.parquet
|
--- index
|
--- xxx.pkl
|
--- xxx.binローカルの保存したChromaDBから目的の文章を検索
前述でローカルに保存したChromaDBをPython環境にロードし、目的の文章を検索する方法を解説します。
コード|ChromaDBをPython環境にロード
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.indexes import VectorstoreIndexCreator
# ================================================================================
# ローカルに保存したChromaデータベースをロード
# ================================================================================
# Embeddings関数
embedding = OpenAIEmbeddings()
# データベースの読込先
db_dir = 'db'
# データベースをロード
loaded_db = Chroma(persist_directory = db_dir, # データベースの読込先
embedding_function = embedding # Embeddings関数
)コード|Python環境にロードしたChromaDBから目的の文書を検索
# ================================================================================
# データ検索
# ================================================================================
# 検索クエリ
query = "スカイツリーの概要"
# 検索結果
results = loaded_db.similarity_search_with_score(query)
# ================================================================================
# 結果出力
# ================================================================================
# 検索結果を出力
print("【検索結果】")
print(results[0][0].page_content)
# 検索クエリと出力結果のベクトルの距離スコアを出力。距離スコアが小さいほど、類似度の高い検索結果という意味
print("【検索スコア】")
print(results[0][1])出力イメージ
出力結果と検索時のスコアを併せて出力しています。検索スコアとは、検索した内容と得られた出力結果の類似スコアであり、値が小さいほど検索内容と類似度が高い出力が得られていることを意味します。
# 出力イメージ
# 【検索結果】
# 2. 東京スカイツリー
# - 東京都内でも最も高い建物で、展望台からは絶景が見られる
# - ショッピングやグルメも楽しめる
# 【検索スコア】
# 0.2744781970977783【Python】LangChain Retrieversの利用方法
最後にLangChain Data Connectionの検索機能「Retrievers」の実装方法を解説します。RetrieversをもとにChatGPTが提供するモデルとも連携することで、より良い検索体験を実現します。
最後のコードは上図のフローを全て含めた形式で記述します。
【準備】Pythonライブラリのインストール
Python環境でのChromaDBを利用する際は、以下のライブラリをインストールする必要があります。
pip install chromadb【参考】テキストファイルダウンロード
テキストファイルのサンプルデータを配布していますので、必要に応じてご利用ください。ダウンロードしたテキストファイルは後述コードのfilepath部分に指定します。
Document Loaders〜Vector Stores作成・ローカルにデータ保存

はじめに、上図赤枠部分の機能を作成します。以下のコードを実行しましょう。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import TextLoader
from langchain.indexes import VectorstoreIndexCreator
# ================================================================================
# Document Loaderを用いてデータロード
# ================================================================================
# テキストファイル
filepath = 'travel_tokyo.txt'
# データロード
loader = TextLoader(filepath)
loaded_document = loader.load()
# ================================================================================
# Text Splitterを用いてデータベースに格納するためにデータ加工
# ================================================================================
# テキスト分割オブジェクト
text_splitter = CharacterTextSplitter(
separator = "\n\n", # テキスト分割の基準を指定
chunk_size = 100, # チャンクの最大サイズ
chunk_overlap = 0, # チャンク間のオーバーラップ。チャンク間の連続性の維持に有効
length_function = len, # チャンクの長さの計算方法。デフォルト(len)は単純な文字数カウント
)
# テキスト分割実行
documents = text_splitter.split_documents(loaded_document)
# ================================================================================
# テキスト文章をベクトル変換するEmbedding関数作成
# ================================================================================
embeddings = OpenAIEmbeddings()
# ================================================================================
# ベクトル化されたデータを保管するデータベースを作成&ローカルに保存
# ================================================================================
# データベースの保存先
db_dir = 'db'
# ChromaDB作成
db = Chroma.from_documents(
documents = documents, # テキスト分割済データ
embedding = embeddings, # Embeddings関数
persist_directory = db_dir, # データベースの保存先
)
# ローカルに書き込み
db.persist()
db = NoneRetrievers
前述でローカルに保存したChromaDBに対して、Retrieversで検索し、検索結果を取得します。
上図の最右部分の処理を実現するコードを以下に示します。
コード
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# ================================================================================
# ローカルに保存したChromaDBをロード
# ================================================================================
# Embeddings関数
embedding = OpenAIEmbeddings()
# データベースの読込先
db_dir = 'db'
# データベースをロード
loaded_db = Chroma(persist_directory = db_dir, # データベースの読込先
embedding_function = embedding # Embeddings関数
)
# ================================================================================
# ChromaDB検索用のLLM作成
# ================================================================================
LLM = OpenAI(
model_name = "text-davinci-003", # OpenAIモデル名
temperature = 0, # 出力する単語のランダム性(0から2の範囲) 0であれば毎回返答内容固定
n = 1, # いくつの返答を生成するか
)
# ================================================================================
# Retriverオブジェクト作成
# ================================================================================
# Retrieverボブジェクト
retriever = loaded_db.as_retriever()
# RetrievalQAチェーン
QA = RetrievalQA.from_chain_type(
llm = LLM, # LLM
chain_type = "stuff", # チェーン種類
memory = None, # メモリー
input_key = "query", # 入力キー
output_key = "result", # 出力キー
retriever = retriever, # retrieverオブジェクト
verbose = False, # 途中プロンプトの表示有無
)
# ================================================================================
# データ検索
# ================================================================================
# 検索クエリ
query = "スカイツリーの概要が知りたい。"
# 検索結果
result = QA.run(query)出力イメージ
# 結果出力
print(result)
# 出力イメージ
# 東京スカイツリーは東京都内でも最も高い建物で、展望台からは絶景が見られるほか、ショッピングやグルメも楽しめます。LangChain Models
前述で定義したLLMの概要・使い方についてはこちらの記事でも詳しく解説しています。

【参考】PythonによるLLM実装|ChatGPT・LangChain

本記事では、PythonでLLMを構築し、様々なタスクをこなす機能の実装方法を多数解説しています。
Python × ChatGPT関連記事
Python × LangChain関連記事
自然言語処理の学習におすすめの書籍

自然言語処理の概要について詳しく学びたい方向けに、厳選したおすすめの学習教材を紹介しています。
最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
