
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- 自然言語処理で登場する「Embedding」とは何か知りたい。
- PythonとOpenAI(ChatGPT)APIを用いてEmbeddingモデルを構築したい。
【自然言語処理】Embeddingとは?|文章のベクトル変換
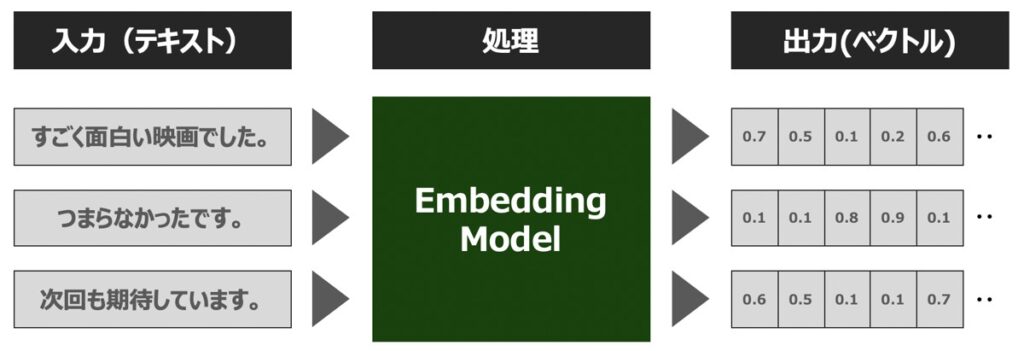
Embedding(埋め込み表現)とは、単語や文章等の自然言語の構成要素をベクトル表現に変換する処理を指します。
文章をベクトル表現に変換することで、次のようなタスクを実現することができます。
- 2つの文章同士の関連性を定量的に測定する
- 自然言語からなる特徴量を機械学習・ディープラーニングの説明変数として用いる
Embeddingは、浮動小数点数のベクトル (リスト) として出力されます。 2つのベクトル間の距離によって、それらの関連性が測定できます。 距離が小さい場合は関連性が高いことを示し、距離が大きい場合は関連性が低いことを示しています。
文章をベクトル表現に変換することで、機械学習・ディープラーニングによる計算処理が可能になり、その結果、自然言語からなる特徴量を説明変数として用いることもできるようになります。
Embedding × 機械学習
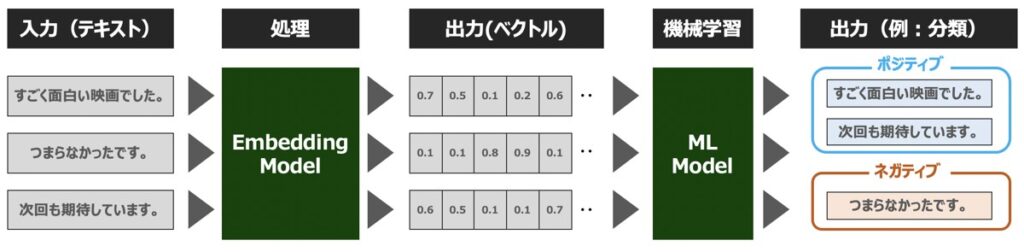
Embeddingモデルと機械学習モデルと組み合わせることで、次のような目的に利用することができます。
| 目的 | 概要 |
|---|---|
| 検索 | 入力テキストとの関連性の高いテキスト情報を検索 |
| クラスタリング | テキスト文章が類似性によってグループ化 |
| 推奨 | 入力テキストと関連するアイテム情報をレコメンド |
| 異常検出 | 対象となるテキスト文章と関連性の低い外れ値を特定 |
| 多様性測定 | テキスト間の類似性分布を分析 |
| 分類 | テキスト文字列が最も類似したラベルに分類 |
【OpenAI】ChatGPTとは?
ChatGPTとは、OpenAIが開発した対話型チャットボットのモデルです。ChatGPTの名前は、GPT-3という第3世代の生成言語モデルに由来しています。
ChatGPTのモデルには、人工知能(AI)が搭載されており、人間の発話に対して自然なやり取りを可能にしています。また、英語をはじめ、中国語、日本語、フランス語など複数言語を認識し、人間らしく応答できるのも特徴的です。
さらに、ChatGPTではチャットの他に、画像生成など近年多様な機能がリリースされてます。以下、ChatGPTで代表するGPTモデルおよびOpenAIが提供するAPI機能一覧を示します。
- チャット機能
- テキストから画像を生成
- オーディオを文字起こし
- Python、SQL、JavaScript等のコードを理解
- 問題あるネガティブ発言検出
- テキスト文章のベクトル変換
【参考】OpenAI社のAPI利用方法
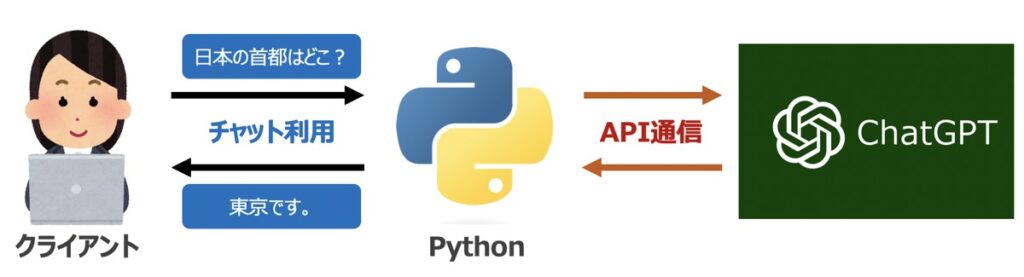
本記事ではChatGPTを用いたPythonプログラミングについて解説します。その際、Open AIが提供するAPI情報が必要になります。「ChatGPTの概要」および「API情報の取得手順」については、こちらの記事で詳しく解説しています。
【参考】ChatGPTを詳しく学びたい方向けの学習講座
ChatGPTを詳しく学びたい方向けに安価で学べるオンライン講座も併せてご紹介します。
【Python×OpenAI】テキスト文章のベクトル変換(Embedding)
Pythonを用いてテキスト文章をベクトル変換するEmbeddingモデルを作成します。今回、モデルはChatGPTで有名なOpenAIが提供するAPI(OpenAI – What are Embeddings)を用いて作成することとします。
【事前準備】Pythonライブラリインストール
OpenAI提供のAPIをPython環境で利用できるライブラリが必要になります。
コマンドプロンプト(WIndows)またはターミナル(Mac)を用いてインストールしましょう。
pip install openai【実践】Pythonライブラリ読込
Pythonプログラムの先頭にライブラリとAPI認証情報を記述します。
前述で紹介したOpenAIのサイトで取得できるシークレットキーを入力しましょう。
from openai import OpenAI
API_Key = "<APIシークレットキーをここに入力>"【実践】Embedding関数作成
入力テキストをベクトル表現で出力するEmbedding関数を作成します。
関数作成
# ==========================================================================
# Embedding
# ==========================================================================
# Embedding
def get_embedding(text_input):
# クライアント
client = OpenAI(api_key=API_Key)
# ベクトル変換
response = client.embeddings.create(
input = text_input,
model = "text-embedding-ada-002",
encoding_format = "float"
)
# 出力結果取得
embeddings = response.data[0].embedding
return embeddings関数実行
上記関数を実行してみましょう。
# ==========================================================================
# 関数実行
# ==========================================================================
# 入力テキスト
text_input = "今回見た映画は、これまでのシリーズと比較して、格段に良かったです。"
# 関数実行
get_embedding(text_input)出力イメージ
上記関数実行後、浮動小数点数のベクトル (リスト) として出力されます。
# 出力イメージ
# [-0.006929283495992422,
# -0.005336422007530928,
# 0.01187589205801487,
# -0.025001877918839455,
# -0.02469271421432495,
# 0.039787933230400085,
# -0.010101565159857273,]【実践】2つの文章間の類似度測定
前述のEmbedding関数でベクトル化された値に対して、類似度指標として用いられるコサイン類似度を適用し、2つの文章間の類似性を確認したいと思います。
例えば、「おはよう」「こんにちは」という2つの文章を比較し、コサイン類似度を計算した場合、類似度が高い(=1に近い)結果が出力されました。
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# ==========================================================================
# 関数実行
# ==========================================================================
# Embedding関数を用いてテキストベクトル化(1)
vec_1 = get_embedding("こんにちは")
# Embedding関数を用いてテキストベクトル化(2)
vec_2 = get_embedding("夜ご飯")
# ==========================================================================
# shapeを揃える
# ==========================================================================
embedding1 = np.array(vec_1).reshape(1, -1)
embedding2 = np.array(vec_2).reshape(1, -1)
# ==========================================================================
# コサイン類似度計算
# ==========================================================================
similarity_score = cosine_similarity(embedding1, embedding2)
# 結果出力
print(f"Cosine Similarity: {similarity_score[0][0]}")
# 出力イメージ
# Cosine Similarity: 0.835617454558944【Python × Embedding】テキスト分析事例
Amazonで売られている食品に対するレビュー情報を今回サンプルデータセットとして用い、Embeddingモデルをもとにテキスト情報をベクトル表現に変換する例を示します。
【事前準備】データセットの準備
今回用いるデータセットには、Amazonユーザーが残した合計568,454 件の食品レビューが含まれています。レビューは英語で書かれており、肯定的または否定的な内容が含まれています。 各レビューには、ProductId、UserId、スコア、レビュー タイトル (概要)、レビュー本文 (テキスト) があります。
データセットは後続のPython処理で利用するため、こちらのリンクよりダウンロードしましょう。
【事前準備】Pythonライブラリインストール
コマンドプロンプト(WIndows)またはターミナル(Mac)を用いてインストールしましょう。
OpenAI
OpenAIが提供するAPIを利用するためのライブラリです。
pip install openaitiktoken
文字列をトークンに分割するためのライブラリです。
pip install tiktoken【実践】Pythonライブラリ読込
はじめに、Pythonライブラリの読込とOpenAIが提供するAPIの認証設定を行います。
from openai import OpenAI
import tiktoken
import pandas as pd
API_Key = "<APIシークレットキーをここに入力>"【実践】データ読込
続いて、サンプルデータセットを読み込むためのコードを記述します。
コード
コード内のfile_pathにダウンロードしたデータセットのパスを指定しましょう。
今回項目名「combine」という商品に対するレビュー情報を全て含んだ項目を用意することとします。
# ダウンロードしたファイルパス
file_path = "data/Reviews.csv"
# データフレーム形式で読込
df = pd.read_csv(file_path, index_col=0)
# Null値削除
df = df.dropna()
# タイトルとコンテンツの結合項目作成
df["combined"] = ("Title: " + df.Summary.str.strip() + "; Content: " + df.Text.str.strip())
# 最新日付の上位レコード20件のみ抽出
df = df.sort_values("Time").tail(20)出力イメージ
# 出力
print(df.head())
# 出力イメージ
# Id ProductId UserId ProfileName HelpfulnessNumerator HelpfulnessDenominator Score Time Summary Text combined
# 1 B001E4KFG0 A3SGXH7AUHU8GW delmartian 1 1 5 1303862400 Good Quality Dog Food I have bought several of the Vitality.. Title: Good Quality Dog Food; Content: I have ...
# 2 B00813GRG4 A1D87F6ZCVE5NK dll pa 0 0 3 1346976000 Not as Advertised Product arrived labeled as.. Title: Not as Advertised; Content: Product arr...【実践】Embedding関数作成
テキスト文章をベクトル化するためのEmbedding関数を作成します。
# ====================================================
# Embeddingの設定値の定義
# ====================================================
# 最大トークン数を指定
max_tokens = 8000
# エンコーディング設定(text-embedding-ada-002モデルに対応)
encoding = tiktoken.get_encoding("cl100k_base")
# ==========================================================================
# Embedding
# ==========================================================================
# Embedding
def embedding_model(text_input):
# クライアント
client = OpenAI(api_key=API_Key)
# ベクトル変換
response = client.embeddings.create(
input = text_input,
model = "text-embedding-ada-002",
encoding_format = "float"
)
# 出力結果取得
embeddings = response.data[0].embedding
return embeddings【実践】データ加工|文章からトークン情報抽出
前述で作成した商品レビュー項目combineからトークン情報を抽出し、n_tokensという合計トークン数を計算した項目を作成します。
今回、計算処理時間の都合上、トークン数の多いレコードは事前に除外する処理を入れることとします。
コード
# トークン数計算
df["n_tokens"] = df.combined.apply(lambda x: len(encoding.encode(x)))
# トークン数が長いものはベクトル変換に時間を要するため、今回除外する
df = df[df.n_tokens <= max_tokens]
# 最新日付の上位レコード20件のみ抽出
df = df.sort_values("Time").tail(20)出力イメージ
# 出力
print( df[["ProductId", "combined", "n_tokens"]] )
# 出力イメージ
# Id ProductId combined n_tokens
# 253600 B005WBETRC Title: You Can't Get These in The Stores Aroun... 198
# 452168 B000FIWIWA Title: You have to have these!; Content: Made ... 40
# 522754 B003MP12MU Title: Not very hot; Content: These are not ve... 92
# 60463 B003QNJYXM Title: A God Sent Remedy!!!; Content: I love t... 62
# 191378 B007O17V2I Title: Oat Bran; Content: This oat bran was gr... 36
# 455891 B008K9TOU0 Title: Newman's own Organics Decaf Cups; Conte... 46
# 97815 B0040J7HIU Title: not 40 bars; Content: There was NOT 40 ... 56
# 16426 B007TJGZ54 Title: super coffee; Content: Great coffee and... 46
# 401482 B000LNC3YM Title: Hoping it's all it promises to be!; Con... 100
# 61474 B005YVU4A6 Title: Chike!; Content: Just tried the orange ... 59
# 83330 B005ZBZLT4 Title: Product is good, but....; Content: I li... 89
# 253246 B005CJUAN6 Title: Tobin James is Excellent!; Content: Tob... 76【実践】Embedding関数実行
前述で加工したデータフレームdfに対してEmbedding関数を適用し、embeddngという新たな項目を作成します。
コード
# embedding実行
df['embedding'] = df.combined.apply(lambda text: get_embedding(text))出力イメージ
# 出力
print( df[["ProductId", "combined", "embedding"]] )
# 出力イメージ
# Id ProductId combined embedding
# 253600 B005WBETRC Title: You Can't Get These in The Stores Aroun... [-0.001888941158540547, -0.010343002155423164,...
# 452168 B000FIWIWA Title: You have to have these!; Content: Made ... [0.003577564377337694, -0.002358017023652792, ...
# 522754 B003MP12MU Title: Not very hot; Content: These are not ve... [-0.012358130887150764, -0.001098759938031435,...
# 60463 B003QNJYXM Title: A God Sent Remedy!!!; Content: I love t... [0.016239019110798836, -0.00246855104342103, 0...
# 191378 B007O17V2I Title: Oat Bran; Content: This oat bran was gr... [0.0026069283485412598, 0.004767912440001965, ...
# 455891 B008K9TOU0 Title: Newman's own Organics Decaf Cups; Conte... [-0.015037572011351585, -0.002554716309532523,...
# 97815 B0040J7HIU Title: not 40 bars; Content: There was NOT 40 ... [0.004331577569246292, -0.00296078366227448, 0...
# 16426 B007TJGZ54 Title: super coffee; Content: Great coffee and... [0.008149697445333004, -0.005243446212261915, ...
# 401482 B000LNC3YM Title: Hoping it's all it promises to be!; Con... [0.004841141868382692, 0.013794651255011559, 0...
# 61474 B005YVU4A6 Title: Chike!; Content: Just tried the orange ... [0.014309492893517017, 0.006073291879147291, 0...
# 83330 B005ZBZLT4 Title: Product is good, but....; Content: I li... [0.0014285191427916288, -0.014152967371046543,...
# 253246 B005CJUAN6 Title: Tobin James is Excellent!; Content: Tob... [0.0009608215186744928, -0.01486437302082777, ... これで、元データのテキストをベクトル表現に変換するまでの処理が完了しました。
項目embeddingに格納されたベクトルのリストを説明変数として用い、類似度を計算したり、機械学習やディープラーニングへ応用することもできるでしょう。
【参考】Pythonでのデータ前処理・分析・可視化
当サイトではPythonを用いた「データ前処理手法」「データ分析」「グラフや表を用いた可視化」手法について幅広く解説しております。AI・機械学習にも応用できる内容となっておりますため、興味がある方は併せてご確認下さい。
Pythonを活用したデータ処理・分析手法一覧



【参考】Pythonとは・できること一覧
最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
