
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- Pythonによる自然言語処理に興味がある
- Mecabを用いたわかち書き・形態素解析方法が知りたい
自然言語処理とは?
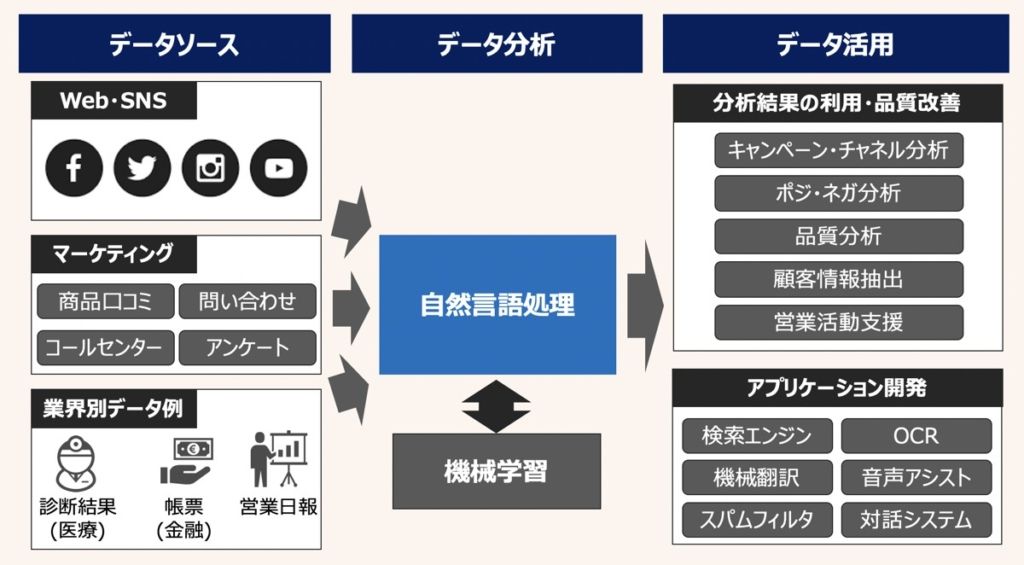
自然言語処理(Natural Language Processing)とは、コンピュータを主体とした、自然言語(我々が日常的に会話や読み書きに使用している言語)を処理する技術を指します。
自然言語処理の目的は、コンピュータに自然言語を処理・解析させ、その解析結果を我々の日常生活・業務・学術的研究に応用することです。例えば、自然言語処理を施したデータは上図のように活用されます。
【参考】自然言語処理の学習におすすめの教材
Pythonによる自然言語処理について詳しく学びたい方向けに、厳選したおすすめ教材も紹介しています。併せてご覧ください。

Mecabとは
Mecabは、日本語の形態素解析が可能なオープンソースライブラリです。
形態素解析とは、日本語の文を形態素(最小の意味を持つ言葉の単位)に分割し、それぞれの品詞や活用形などを判別することです。Mecabは、日本語の形態素解析を高速かつ正確に行うことができる特徴があります。
Mecabはオープンソースであり、多くのプログラムやアプリケーションで利用されています。具体的には、自然言語処理、機械翻訳、情報検索、テキストマイニングなどの分野で広く利用されています。
わかち書きとは、テキスト文章を単語に分解することを指します。
Mecabは分を単語に分解するだけでなく、各単語の品詞や読みなどの情報を付与することが可能です。このような品詞情報の付与まで含んだわかち書きを形態素解析と呼びます。
【事前準備】Mecab自然言語処理用のPython環境構築
Mecabを用いて自然言語処理を行うに際し、Python環境に次のようなライブラリをインストールする必要があります。以下、コマンドプロンプト(Windows)やターミナル(MacOS)を開き、事前に実行しておきましょう。
unidic-lite
pip install unidic-litemecab-python3
pip install mecab-python3【Python】Mecabを用いた自然言語処理実践|形態素解析
それでは実際にPythonのMecabライブラリを用いた形態素解析を実践します。1つずつ機能をみていきましょう。
品詞分解
文章を単語に分割した情報および品詞情報を出力する場合、次のように記述します。
コード
import MeCab
# ================================================
# 言語処理
# ================================================
# テキスト
text = "私の好きな食べ物は赤いりんごです。"
# Mecab 形態素解析
tagger = MeCab.Tagger()
# ================================================
# 出力
# ================================================
# 品詞分解
print(tagger.parse(text))出力結果

指定の単語抽出
分割した指定の単語のみを抽出する場合、次のように記述できます。
コード
import MeCab
# ================================================
# 言語処理
# ================================================
# テキスト
text = "私の好きな食べ物は赤いりんごです。"
# Mecab 形態素解析
tagger = MeCab.Tagger()
# Nodeオブジェクト
node = tagger.parseToNode(text)
# ================================================
# 出力
# ================================================
# 単語抽出(1番目)
print(node.surface)
# 単語抽出(2番目)
print(node.next.surface)
# 単語抽出(3番目)
print(node.next.next.surface)
# 単語抽出(4番目)
print(node.next.next.next.surface)
# 単語抽出(5番目)
print(node.next.next.next.next.surface)
# 単語抽出(6番目)
print(node.next.next.next.next.next.surface)出力結果
#
# 私
# の
# 好き
# な
# 食べ物指定の品詞情報抽出
分割した指定の単語に紐づく品詞情報のみを抽出する場合、次のように記述できます。
コード
import MeCab
# ================================================
# 言語処理
# ================================================
# テキスト
text = "私の好きな食べ物は赤いりんごです。"
# Mecab 形態素解析
tagger = MeCab.Tagger()
# Nodeオブジェクト
node = tagger.parseToNode(text)
# ================================================
# 出力
# ================================================
# 品詞情報抽出(1番目)
print(node.feature)
# 品詞情報抽出(2番目)
print(node.next.feature)
# 品詞情報抽出(3番目)
print(node.next.next.feature)
# 品詞情報抽出(4番目)
print(node.next.next.next.feature)
# 品詞情報抽出(5番目)
print(node.next.next.next.next.feature)
# 品詞情報抽出(6番目)
print(node.next.next.next.next.next.feature)出力結果
# BOS/EOS,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*
# 代名詞,*,*,*,*,*,ワタクシ,私-代名詞,私,ワタクシ,私,ワタクシ,和,*,*,*,*,ワタクシ,ワタクシ,ワタクシ,ワタクシ,*,*,0,*,*
# 助詞,格助詞,*,*,*,*,ノ,の,の,ノ,の,ノ,和,*,*,*,*,ノ,ノ,ノ,ノ,*,*,*,名詞%F1,*
# 形状詞,一般,*,*,*,*,スキ,好き,好き,スキ,好き,スキ,和,ス濁,基本形,*,*,スキ,スキ,スキ,スキ,*,*,2,C4,*
# 助動詞,*,*,*,助動詞-ダ,連体形-一般,ダ,だ,な,ナ,だ,ダ,和,*,*,*,*,ナ,ダ,ナ,ダ,*,*,*,名詞%F1,*
# 名詞,普通名詞,一般,*,*,*,タベモノ,食べ物,食べ物,タベモノ,食べ物,タベモノ,和,*,*,*,*,タベモノ,タベモノ,タベモノ,タベモノ,*,*,"2,3",C1,*繰り返し構文を用いた単語抽出
文章から分割した単語を繰り返し構文を用い、リスト型で出力すると使い勝手が良いです。以下のように実行します。
コード
# テキスト
text = "私の好きな食べ物は赤いりんごです。"
# Mecab 形態素解析
tagger = MeCab.Tagger()
# Nodeオブジェクト
node = tagger.parseToNode(text)
# ループによる単語抽出
while node:
print(node.surface)
node = node.next出力結果
#
# 私
# の
# 好き
# な
# 食べ物
# は
# 赤い
# りんご
# です
# 。わかち書き関数の作成
最後に、テキスト文章をインプットとし、分割した単語リストを出力するわかち書き関数を作成します。
コード(関数)
import MeCab
# ================================================
# わかち書き関数作成
# ================================================
# Mecab 形態素解析
tagger = MeCab.Tagger()
def tokenize(text):
# Nodeオブジェクト
node = tagger.parseToNode(text)
# 品詞分解
tokens_list = []
# ループで品詞分解結果をそれぞれ取得
while node:
# BOS/EOS以外の結果をAppend
if node.surface != "":
tokens_list.append(node.surface)
# 次の単語へ更新
node = node.next
return tokens_listコード(関数実行)+出力結果
# ================================================
# 関数実行
# ================================================
# テキスト情報
text = "日本の首都は東京です。"
# 関数実行
tokenize(text)
# ================================================
# 出力結果
# ================================================
# ['日本', 'の', '首都', 'は', '東京', 'です', '。']【参考】AI・機械学習における配信情報まとめ
当サイトではAI・機械学習における「基礎」から「最新のプログラミング手法」に至るまで幅広く解説しております。また「おすすめの勉強方法」をはじめ、副業・転職・フリーランスとして始める「AI・機械学習案件の探し方」についても詳しく言及しています。
【仕事探し】副業・転職・フリーランス

【教育】おすすめ勉強法

【参考】記事一覧

最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
