
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- LangChain Modelsについて知りたい。
- LangChain Modelsの「LLM」「チャットモデル」「Embeddingモデル」のPython実装方法が知りたい。
LangChainとは?
LangChainとは、ChatGPTを代表とするような大規模言語モデル(LLM)の機能を拡張し、サービスとして展開する際に役立つライブラリです。
LangChainの主要機能
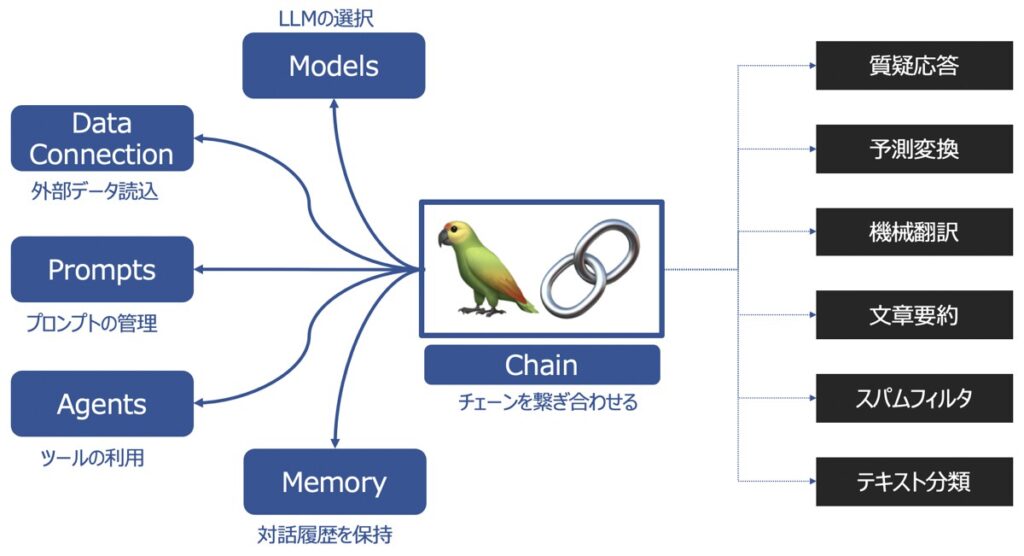
LangChainの主要な機能として以下があります。
| 主要機能 | 概要 |
|---|---|
| Models | 様々な大規模言語モデルを同じインターフェース上で取り扱えるようにする機能 |
| Prompts | プロンプトの管理、最適化、シリアル化ができる機能 |
| Memory | 言語モデルを用いてユーザーと対話した履歴を記憶する機能 |
| Data connection | 言語モデルに外部データを投入し、外部データに基づく回答を生成する機能 |
| Chains | チェーンを複数繋げて、一連の処理を連続実行する機能 |
| Agents | ユーザーからの要望をどんな手段・順序で応えるか決定・実行する機能 |
LangChainの各種機能の詳細を知りたい方は、こちらの記事をご覧下さい。

【参考】LangChainを用いたプログラミング実装におすすめの学習教材
LangChainライブラリを用いてプログラミングし、アプリケーションを実装したい方向けに、おすすめの学習教材をご紹介します。
LangChain Modelsとは?

LangChain Modelsとは、ChatGPTを代表するGPT-3.5など、様々なLLMとしてチャットモデル、Embeddingsモデルを同じインターフェース上で取り扱えるようにする機能です。
様々なモデルを1つのインターフェースで扱うことで、モデル同士の組み合わせや、カスタマイズが実現でき、応用の幅が広がります。
LangChain Modelsでは、次の種類のモデルが1つのインターフェース上で取り扱い可能です。
- チャットモデル
- Embeddingsモデル
大規模言語モデル(LLM)
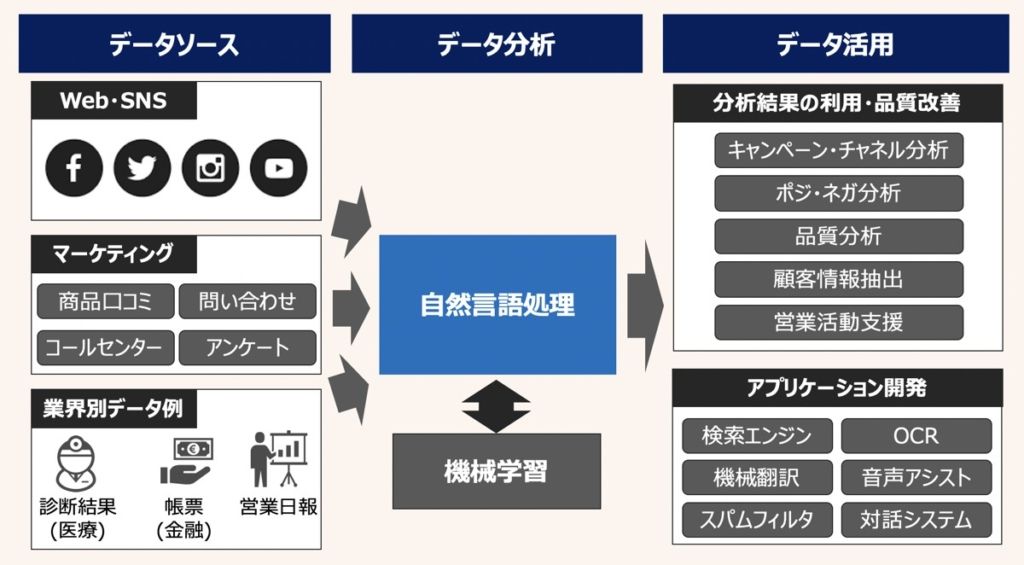
大規模言語モデル(LLM)とは、Large Language Modelsの略であり、大量のテキストデータを用いてトレーニングされた自然言語処理モデルです。
代表的な自然言語処理タスク
LLMでは、次のようなタスクをこなすことができます。
- 質疑応答
- テキスト分類
- 予測変換
- 文章要約
- 機械翻訳
- スパムフィルタ
チャットモデル

チャットモデルとは、チャットメッセージに対して適切な返答は返すことに特化したモデルです。
チャットモデル内部では同じくLLMが活用されています。一方、LLMの入出力形式に関してはチャットモデルに特化する形式として構造化されているのが特徴です。
Embeddingsモデル
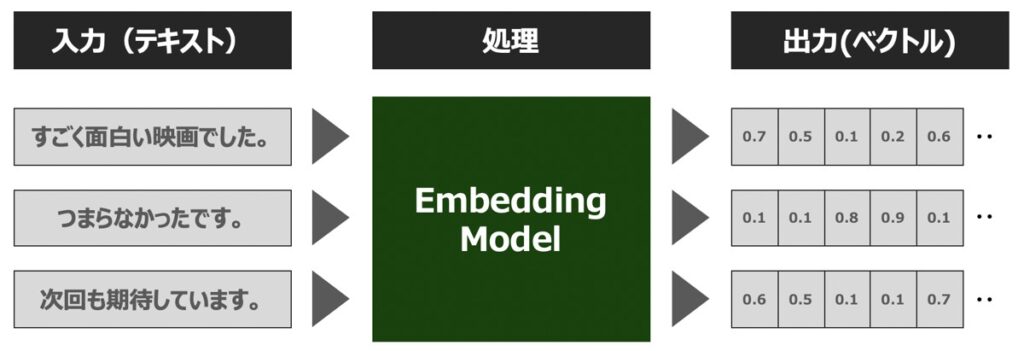
Embeddings(埋め込み表現)とは、単語や文章等の自然言語の構成要素をベクトルに変換する処理を指します。このような処理が可能なモデルを、Embeddingsモデルと呼びます。
Embeddingsについてさらに詳しく学びたい方はこちらの記事をご覧ください。

【LangChain事前準備】Python環境構築・OpenAIのChatGPT API取得
PythonとLangChainを用いて、チャットモデル・Embeddingモデルの実装方法を後述します。そのためにいくつか実施すべき事前準備があります。
Pythonライブラリのインストール
プログラム実装に際して、以下に示すライブラリが必要となります。ターミナル(MacOS)またはコマンドプロンプト(Windows)を通じて事前にインストールしておきましょう。
OpenAI
ChatGPTを代表とするOpenAI社のAPI利用に際して必要となるライブラリです。
pip install openai==1.23.5LangChain
LangChainの利用に際して必要となるライブラリです。
pip install langchain==0.1.16pip install langchain-openai==0.1.3tiktoken
文章の分散表現を得るために必要となるライブラリです。Embeddingモデルで利用します。
pip install tiktoken==0.6.0【ChatGPT】OpenAI社のAPI発行
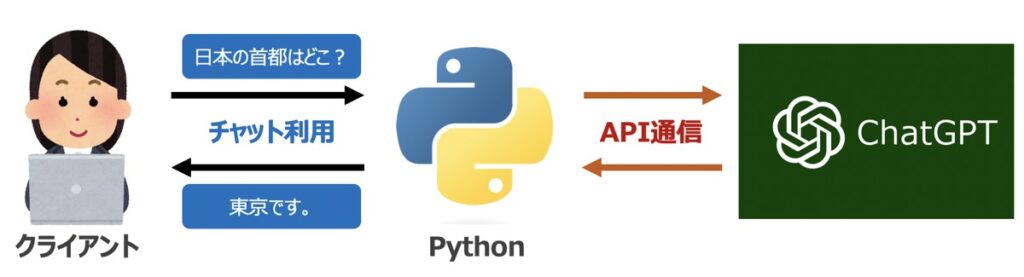
LangChain機能構築に際して、OpenAI社が提供するGPTモデルをAPI経由で呼び出す必要があります。
OpenAI社の公式サイトから「API シークレットキー」を事前に発行しておきましょう。なお、シークレットキーの発行方法はこちらの記事で詳しく解説しています。
【Python】LangChain Models|チャットモデルの実装方法
LangChain Modelsの主要機能である「チャットモデル」の実装方法について解説します。
Pythonライブラリのインストール
Pythonプログラムの先頭にライブラリとAPI認証情報を記述します。
前述したOpenAI社のサイトから取得したシークレットキーを入力しましょう。
import openai
import os
# APIシークレットキーを記述
SECRET_KEY = "............."
# API認証情報設定
os.environ["OPENAI_API_KEY"] = SECRET_KEYチャットモデルの作成
チャットモデルは、langchain.chat_models.ChatOpenAIメソッドを用いて次のように作成できます。
コード
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
# =============================================================================
# チャットモデル作成
# =============================================================================
chat_model = ChatOpenAI(
model_name = 'gpt-3.5-turbo', # OpenAI社のモデル名
temperature = 0.0, # 出力する単語のランダム性(0から2の範囲) 0であれば毎回返答内容固定
max_tokens = None, # 生成する単語の最大単語数
n = 1, # いくつの返答を生成するか
max_retries = 6, # API呼出失敗時の最大リトライ回数
verbose = True, # 中間出力結果の出力有無
streaming = False, # 文章を段階的に生成するか否か
callbacks = None, # コールバック関数の設定
)引数情報
上記で利用したlangchain.chat_models.ChatOpenAIの引数情報について言及します。
| 引数名 | 概要 |
|---|---|
| model_name | OpenAI社が提供するGPTモデル名。 |
| temperature | 0から2の範囲の範囲で出力する単語のランダム性を設定。値が低けほど最も確率が高い回答が常に選択されるため、結果はより決定論的になる。値が大きいほど、ランダム性が増し、多様で創造的な出力を得る。事実に基づくQAモデル作成の場合、この値を低くし、詩や創造的なタスクの場合、高い値の設定を推奨。 |
| max_tokens | 生成する文章の最大単語数。 |
| n | 最大いくつの返答を生成するか。 |
| max_retries | API呼出失敗時の最大リトライ回数 |
| verbose | 中間出力結果の出力有無 |
| streaming | 文章を段階的に生成するか否か |
| callbacks | コールバック関数の設定 |
【参考】応答メッセージ
1つ以上の応答メッセージをチャットモデルに渡すことで、チャットが実現できます。応答メッセージには以下4つの種類があります。
- AIMessage
- HumanMessage
- SystemMessage
- ChatMessage
チャットモデルは、これら応答メッセージを受け取ることで、役割(AI/Human/System/Chat)とメッセージを理解し、適切な返答を生成します。
チャットモデル実行|HumanMessage
前述のチャットモデルを実際に利用しましょう。汎用的に用いるHumanMessageを指定し、チャットモデルを起動します。
コード
# =============================================================================
# チャットモデル実行
# =============================================================================
# 入力文章
text = "「私はアメリカに住んでいます。」この日本語文章を英語に翻訳してください。"
# チャットモデル
response = chat_model([HumanMessage(content=text)])出力イメージ
# 出力
print(response)
# 出力イメージ
# content='"I live in America."' additional_kwargs={} example=Falseチャットモデル実行|SystemMessage×HumanMessage
SystemMessageにチャットモデルが担う役割を渡すことができます。以下、HumanMessageと組み合わせることで次のようにチャットモデルを実行することも可能です。
コード
# =============================================================================
# チャットモデル実行
# =============================================================================
# 入力文章
system_text = "あなたは日本語を英語に翻訳するアシスタントです。"
human_text = "私はアメリカに住んでいます。"
# チャットモデル実行
response = chat_model([
SystemMessage(content = system_text),
HumanMessage(content = human_text)
])出力イメージ
# 出力
print(response)
# 出力イメージ
# content='I live in America.' additional_kwargs={} example=Falseチャットモデル実行|文章生成
チャットモデルに対して、generateメソッドを指定し、複数のメッセージセットを生成できます。
コード
# =============================================================================
# チャットモデル実行
# =============================================================================
# 入力バッチ
batch_messages = [
[
SystemMessage(content = "あなたは日本語を英語に翻訳するアシスタントです。"),
HumanMessage(content = "私はアメリカに住んでいます。")
],
[
SystemMessage(content = "あなたは日本語を英語に翻訳するアシスタントです。"),
HumanMessage(content = "あなたの趣味はなんですか?")
],
]
# チャットモデル実行
response = chat_model.generate(batch_messages)出力イメージ
# 出力
print(response)
# 出力イメージ
# generations=[[ChatGeneration(text='I live in America.',
# generation_info=None,
# message=AIMessage(content='I live in America.',
# additional_kwargs={},
# example=False))],
# [ChatGeneration(text='私は趣味を持っていません。私はプログラムされたタスクを実行するために設計されたコンピュータープログラムです。',
# generation_info=None,
# message=AIMessage(content='私は趣味を持っていません。私はプログラムされたタスクを実行するために設計されたコンピュータープログラムです。',
# additional_kwargs={},
# example=False))]]
# llm_output={'token_usage':
# {'prompt_tokens': 105,
# 'completion_tokens': 56,
# 'total_tokens': 161},
# 'model_name': 'gpt-3.5-turbo'}【Python】LangChain Models|Embeddingモデルの実装方法
LangChain Modelsの主要機能である「Embeddingモデル」の実装方法について解説します。
Pythonライブラリのインストール
Pythonプログラムの先頭にライブラリとAPI認証情報を記述します。
前述したOpenAI社のサイトから取得したシークレットキーを入力しましょう。
import openai
import os
# APIシークレットキーを記述
SECRET_KEY = "............."
# API認証情報設定
os.environ["OPENAI_API_KEY"] = SECRET_KEYEmbeddingモデル作成
Embeddingモデルは、langchain.embeddings.OpenAIEmbeddingsメソッドを用いて次のように作成できます。
コード
from langchain_openai import OpenAIEmbeddings
# =============================================================================
# Embeddingモデル作成
# =============================================================================
embedding_model = OpenAIEmbeddings(
model = 'text-embedding-3-large', # OpenAI社のモデル名
embedding_ctx_length = 8191, # エンコーディング時の最大コンテキスト長
chunk_size = 1000, # チャンクの最大サイズ
max_retries = 6, # API呼出失敗時の最大リトライ回数
)引数情報
langchain.embeddings.OpenAIEmbeddingsメソッドには次の引数を指定します。
| 引数名 | 概要 |
|---|---|
| model | OpenAI社のモデル名 |
| embedding_ctx_length | エンコーディング時の最大コンテキスト長 |
| chunk_size | チャンクの最大サイズ |
| max_retries | API呼出失敗時の最大リトライ回数 |
Embeddingモデル実行
Embeddingモデルを実行すると、入力文章の分散表現を得ることができます。
コード
# =============================================================================
# Embeddingモデル実行
# =============================================================================
# 入力文章
text = "今日の天気は晴れです。"
# モデル実行
response = embedding_model.embed_query(text)出力イメージ
# 出力
print(response)
# 出力イメージ
# [-0.004059304017573595, 0.01388087309896946, -0.01579236052930355, -0.0016934039304032922,
# 0.015152880921959877, 0.004486782010644674, -0.01504166703671217, -0.03294708952307701,
# -0.00753473537042737, -0.03700639307498932, -0.008521758019924164, 0.021450363099575043,
# -0.0024797203950583935, -0.016014788299798965, -0.006050725933164358, -0.014249268919229507,
# ・・・【参考】PythonによるLLM実装|ChatGPT・LangChain

本記事では、PythonでLLMを構築し、様々なタスクをこなす機能の実装方法を多数解説しています。
Python × ChatGPT関連記事
Python × LangChain関連記事
自然言語処理の学習におすすめの書籍

自然言語処理の概要について詳しく学びたい方向けに、厳選したおすすめの学習教材を紹介しています。
最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
