
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
- LangGraphを活用した生成AIエージェントの開発に興味がある!
- LangGraphにおける「 State」の概念・使い方を知りたい!
LangGraphとは
LangGraphとは、複数の大規模言語モデル(LLM)やエージェントを連携させ、複雑なワークフローやタスクを効率的に管理できるライブラリです。主に自然言語処理やAIアプリケーションの開発を強力にサポートします。
LangGraphを理解するためには、以下の用語を正しく把握しておくことが重要です。
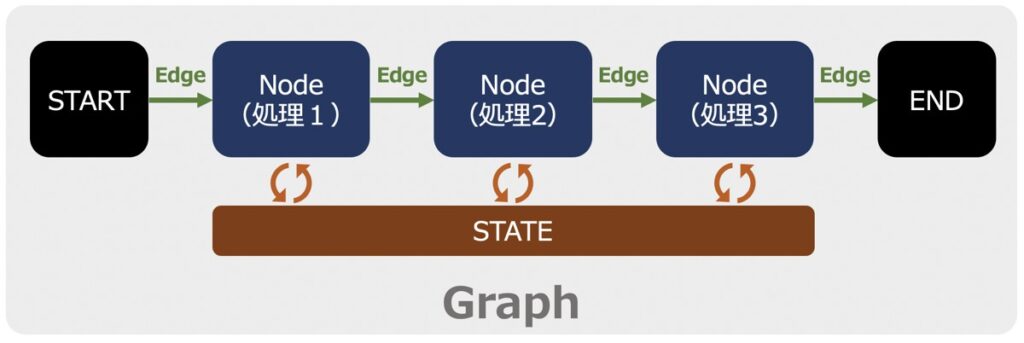
Node(ノード)
ノードとは、LangGraph内で実行される個々の処理ステップを指します。各ノードは明確に定義された役割や処理を持ち、Stateを受け取り、何らかの処理を実行した後、次のノードにStateを引き渡します。
Edge(エッジ)
エッジはノード間を接続する「経路」を意味します。エッジによって、どのノードからどのノードへとデータが流れるのかを定義します。明確なエッジの設定により、データの流れが整理され、処理順序が管理されます。
Graph(グラフ)
Graphはノードとエッジをまとめた全体的な処理フローを示す構造体です。LangGraphの処理はGraphを通じて組み立てられ、各ノードやエッジがGraphの一部として明確に機能します。
State(状態)
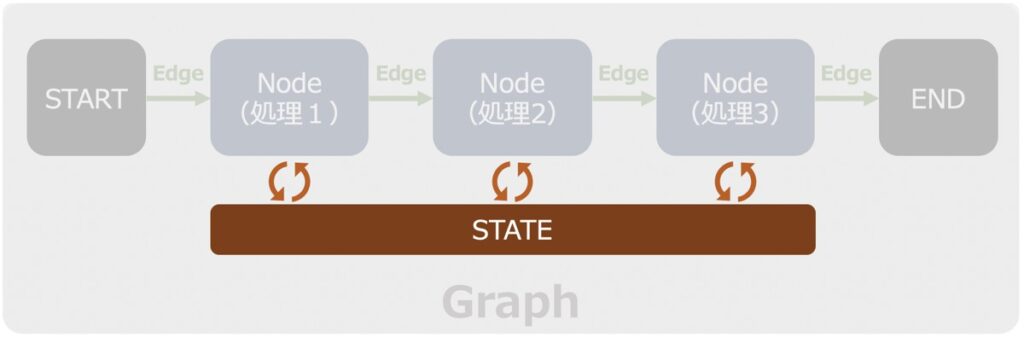
LangGraphにおける「State」とは、プロセスやエージェント間でやり取りされるデータを指します。
具体的には、ユーザーの入力情報、途中経過として得られた結果、各ノードで処理した情報、最終的な出力データなど、アプリケーションの動作に必要となる情報が含まれます。
Stateはアプリケーション全体の「状態管理」を行う重要な役割を担っており、各ノード(処理ステップ)間でデータを引き継ぎながらワークフローを実現します。これにより、各ノードが独立した機能を持ちつつも、一連の処理がスムーズに流れ、最終的な目標を達成できるようになります。
さらに、Stateを利用することで、処理過程で発生したエラーや問題点を特定・デバッグしやすくなるという利点もあります。アプリケーションの挙動を把握しやすくなり、保守性や拡張性の高い設計を実現できます。
つまり、Stateを使いこなすことは、LangGraphアプリケーションのパフォーマンスを向上させ、開発効率を高めるために不可欠なスキルとなっています。
State設計時のポイント
開発プロセスにおけるStateの設計段階では以下のポイントを検討しましょう。
データの明確化
各ノードでどのようなデータが必要かを明確に定義しましょう。データの流れを可視化し、各ノードが処理に必要な情報を漏れなく含めることが重要です。
データの粒度
Stateに格納するデータの粒度(細かさ)を適切に設定することが重要です。粒度が粗すぎるとノード間で不要なデータをやり取りすることになり、細かすぎると処理負荷が高まるため注意が必要です。
データのライフサイクル
各データがいつ作成され、どのタイミングで更新され、いつ削除されるかを明確にしておくことで、不要なデータを蓄積せず、効率的な状態管理が可能になります。
エラー処理とロギング
エラーが発生した場合にどのようにStateを扱うかを考えましょう。また、処理過程を追跡するためのログ情報をStateに含めることも検討するとよいでしょう。
拡張性と保守性
将来的な機能拡張を見越して、Stateの構造を柔軟に保つような設計を心がけましょう。後から変更が難しい設計にならないよう注意する必要があります。
【Python実践】LangGraphにおけるState管理
実際にプログラミングコードを見ながらStateの開発プロセスをイメージしましょう。
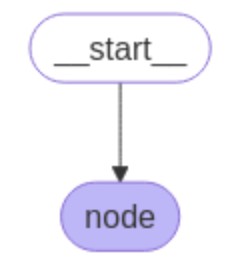
Graphの構築
Graphイメージ
コード
from langchain_core.runnables import RunnableConfig
from typing_extensions import TypedDict
from langgraph.graph import StateGraph
from IPython.display import Image, display
# =========================
# State
# =========================
class State(TypedDict):
value: str
# =========================
# node
# =========================
def node(state: State, config: RunnableConfig):
return {"value": "1"}
# =========================
# Graph
# =========================
graph = StateGraph(State)
graph.add_node("node", node)
graph.set_entry_point("node")
app = graph.compile()
# =========================
# 可視化
# =========================
png = app.get_graph().draw_mermaid_png()
display(Image(png))出力イメージ
# 出力
result = app.invoke({"value": ""})
print(result)
# 出力イメージ
# {'value': '1'}【参考】 Stateの書き方
LangGraphではStateの構造を定義するために、PythonのTypedDictを用います。
from typing_extensions import TypedDict
class State(TypedDict):
value: strTypedDictは型を明示的に定義することができ、コードの可読性と安全性の向上に寄与します。明確に型定義をすることで、どのようなデータがState内で取り扱われるかが一目で分かり、タイプミスや型エラーなどのバグを早期に発見できます。
【Python実践】Stateを用いた状態の引き継ぎ
続いて、複数nodeを結合したgraphを構築し、Stateでデータを引き継いでいく様子を詳しくみていきます。
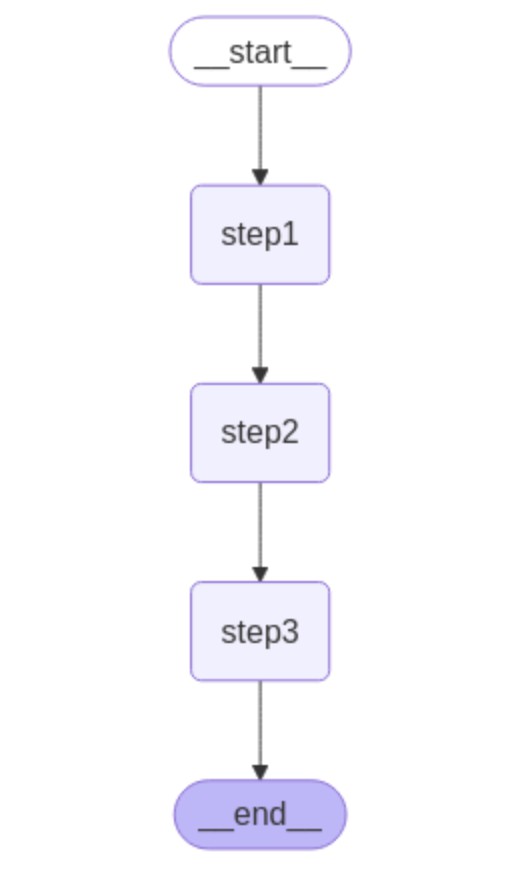
Graphの構築
Graphイメージ
コード
from typing_extensions import TypedDict
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
# =========================
# State
# =========================
class State(TypedDict, total=False):
# ① これまでのメッセージ履歴を蓄積
messages: list[str]
# ② カウンタを実装
count: int
# ③ 実行したノードを備考欄として保持
note:str
# =========================
# node
# =========================
def step1(state: State, config: RunnableConfig) -> dict:
# 初期状態のmessagesに'step1'を追加
new_message = state.get("messages", []) + ["step1"]
# カウンタを1更新
new_count = state.get("count", 0) + 1
# 備考
note = "step1を実行"
# 更新したStateを出力
update_state = {"messages": new_message, "count": new_count, "note":note}
return update_state
def step2(state: State, config: RunnableConfig) -> dict:
# Step1で受け取ったmessageに"step2"を追加
new_message = state.get("messages", []) + ["step2"]
# カウントに+1追加
new_count = state["count"] + 1
# 備考
note = "step2を実行"
# 更新したState出力
update_state = {"messages": new_message, "count": new_count, "note":note}
return update_state
def step3(state: State, config: RunnableConfig) -> dict:
# Step2で受け取ったmessageに"step3"を追加
new_message = state.get("messages", []) + ["step3"]
# カウントを2倍
new_count = state["count"] *2
# 備考
note = "step3を実行"
# 更新したState出力
update_state = {"messages": new_message, "count": new_count, "note":note}
return update_state
# =========================
# Graph
# =========================
graph = StateGraph(State)
graph.add_node("step1", step1)
graph.add_node("step2", step2)
graph.add_node("step3", step3)
graph.add_edge(START, "step1")
graph.add_edge("step1", "step2")
graph.add_edge("step2", "step3")
graph.add_edge("step3", END)
app = graph.compile()
# =========================
# 可視化
# =========================
png = app.get_graph().draw_mermaid_png()
display(Image(png))出力イメージ
Graphの各ノードの中間出力を逐次出力する場合、stream()メソッドを用います。
以下のコードを実行すると、Stateでの情報がどのように更新されているかが分かりやすいですね。
# Stateの初期状態を入力として渡す
initial_state = {"messages": [], "count": 0, "node_id":""}
# nodeの中間出力を表示
for event in app.stream(initial_state):
print(event)
# 出力イメージ
# {'step1': {'messages': ['step1'], 'count': 1, 'note': 'step1を実行'}}
# {'step2': {'messages': ['step1', 'step2'], 'count': 2, 'note': 'step2を実行'}}
# {'step3': {'messages': ['step1', 'step2', 'step3'], 'count': 4, 'note': 'step3を実行'}}Graphの最終結果のみ出力する場合はinvoke()メソッドを用いて次のように記述します。
# 最終結果取得
result = app.invoke(initial_state)
print(result)
# 出力イメージ
# {'messages': ['step1', 'step2', 'step3'], 'count': 4, 'note': 'step3を実行'}最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
