
こんにちは、DXCEL WAVEの運営者(@dxcelwave)です!
こんな方におすすめ!
- Pythonを用いてAmazon S3にオブジェクトをアップロードする方法が知りたい。
- Pythonを用いてAmazon S3に保存されたCSVファイルを参照する方法が知りたい。
目次
【AWS】Amazon S3とは
S3とは、様々なデータをクラウド上に保存・管理できるストレージサービスです。Webサイトやアプリケーションのバックアップファイルを始め、静的コンテンツ(HTML/CSS・動画・画像ファイル)など多様なファイルがS3上で保存・管理できます。
S3の概要や基本操作についてはこちらの記事に詳しくまとめています。
【AWS】Amazon S3とは・使い方徹底解説|クラウドストレージサービス入門
Amazon S3の概要・基本操作方法について詳しく解説します。
【事前準備】IAMユーザー作成・アクセスキー・シークレットキー発行
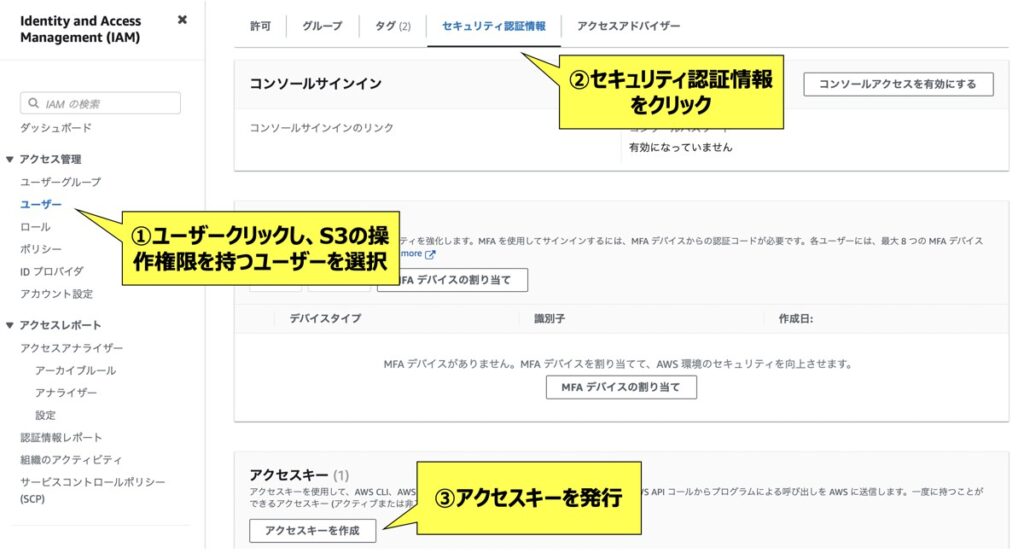
事前準備としてS3の操作権限を有したIAMユーザーを作成しておきましょう。その際、併せてアクセスキーおよびシークレットキーを発行します。これらのキーは後続のPythonコードで必要となりますので、お手元にメモしておきましょう。
【事前準備】Pythonライブラリのインストール
今回boto3というS3にアクセスするためのライブラリを活用します。コマンドプロンプト(Windows)やターミナル(Mac)を開き、以下のコードを実行することでライブラリを事前にインストールしておきましょう。
pip install boto3【Python実践】S3バケット内にCSVファイルをアップロードする方法
S3に保存されたデータ(CSVファイルや画像・動画ファイルなど)をオブジェクトと呼びます。また、オブジェクトが格納される場所をバケットと呼びます。
今回はCSVファイルを例とし、ローカルPC上にあるCSVファイルを指定のバケットにアップロードする方法を示します。以下のコードを実行しましょう。
from io import StringIO
import boto3
import pandas as pd
# ===========================================================
# アクセスキーとシークレットキー
# ===========================================================
IAM_ACCESS_KEY = "<IAMで取得したアクセスキー>"
IAM_SECRET_KEY = "<IAMで取得したシークレットキー>"
# ===========================================================
# アップロードしたいcsvファイルを読込
# ===========================================================
# CSVファイルパス
filepath = "User/XXX/XXX/sample.csv"
# アップロードしたいCSVファイルをデータフレーム形式で読込
data = pd.read_csv(filepath)
# ファイルオブジェクト変換
csv_buf = StringIO()
csv_file = data.to_csv(csv_buf, header=True, index=False)
# ===========================================================
# csvファイルをs3にアップロード
# ===========================================================
# バケット名
bucket_name = "<バケット名を記述>"
# バケットにアップロードする際のオブジェクト名(Key)
obj_name = "sample.csv"
# s3インスタンス
s3 = boto3.client("s3",
aws_access_key_id = IAM_ACCESS_KEY,
aws_secret_access_key = IAM_SECRET_KEY,)
# s3にアップロード
s3.put_object(Bucket = bucket_name, Body=csv_buf.getvalue(), Key=obj_name)ポイント
IAM_ACCESS_KEYとIAM_SECRET_KEYにIAMのコンソール画面から発行したアクセスキーとシークレットキーを入力します。filepathには、アップロードしたいCSVファイルのファイルパスを指定します。- S3アップロード先のバケットを
bucket_nameに指定します。 - S3 バケット内に保存するCSVファイル名(キー)を
obj_nameに指定します。
【Python実践】S3バケットに保存されたCSVファイルを読み込む
S3バケットに保存されたCSVファイルを参照したい場合、次のコードを実行します。
from io import StringIO
import boto3
import pandas as pd
# ===========================================================
# アクセスキーとシークレットキー
# ===========================================================
IAM_ACCESS_KEY = "<IAMで取得したアクセスキー>"
IAM_SECRET_KEY = "<IAMで取得したシークレットキー>"
# ===========================================================
# s3にアクセス
# ===========================================================
# バケット名
bucket_name = "<バケット名を記述>"
# 参照したいcsvファル(オブジェクトKey)
obj_name = "sample.csv"
# s3インスタンス
s3 = boto3.client("s3",
aws_access_key_id = IAM_ACCESS_KEY,
aws_secret_access_key = IAM_SECRET_KEY,)
# ===========================================================
# csvファイル参照
# ===========================================================
# オブジェクト取得
csv_file = s3.get_object(Bucket=bucket_name, Key=obj_name)
csv_file_body = csv_file["Body"].read().decode("utf-8")
# データフレームとして出力
df = pd.read_csv(StringIO(csv_file_body))ポイント
IAM_ACCESS_KEYとIAM_SECRET_KEYにIAMのコンソール画面から発行したアクセスキーとシークレットキーを入力します。- S3参照先のバケットを
bucket_nameに指定します。 - S3 バケット内の参照したいCSVファイル名(キー)を
obj_nameに指定します。
最後に

お問い合わせフォーム
上記課題に向けてご気軽にご相談下さい。
お問い合わせはこちら
